Clear Sky Science · pl
PADP: progresywne i adaptacyjne przycinanie danych dla wydajnego uczenia przyrostowego
Dlaczego ważne jest uczenie się więcej przy mniejszej liczbie danych
Współczesne systemy sztucznej inteligencji potrzebują dużych ilości danych i mocy obliczeniowej, co czyni je kosztownymi w trenowaniu i trudnymi do uruchomienia na codziennych urządzeniach, takich jak telefony, kamery czy domowe roboty. Jednocześnie systemy te coraz częściej muszą uczyć się w czasie rzeczywistym, gdy pojawiają się nowe typy obrazów lub sytuacje. W artykule przedstawiono metodę nazwaną PADP, która pomaga sieciom neuronowym uczyć się efektywniej, decydując w trakcie treningu, które przykłady naprawdę warto uwzględnić, a które można bezpiecznie pominąć, nie tracąc przy tym ważnej wiedzy z przeszłości.
Nauczanie maszyn małymi krokami
Większość systemów rozpoznawania obrazów jest trenowana jednokrotnie na stałym zbiorze danych, a następnie wdrażana. W praktyce jednak pojawiają się nowe kategorie: kamera bezpieczeństwa może musieć rozpoznawać nowe obiekty, a system medyczny — radzić sobie z nowymi chorobami. Ten proces krok po kroku, zwany uczeniem przyrostowym, stawia poważne wyzwanie: kiedy model koncentruje się na nowych klasach, ma tendencję do zapominania starszych — to tzw. katastrofalne zapominanie. Równocześnie trenowanie na wszystkich dostępnych danych przy każdej aktualizacji jest marnotrawne i często niemożliwe na urządzeniach o ograniczonej pamięci i mocy. Autorzy argumentują, że aby uczenie przyrostowe było praktyczne, potrzebne są metody redukujące wysiłek treningowy, a jednocześnie starannie zachowujące najbardziej przydatne stare i nowe przykłady.
Wybieranie trudnych i niestabilnych przykładów
PADP podchodzi do tego, oceniając każdy przykład treningowy według jego użyteczności dla modelu w różnych momentach czasu. Pierwszy wskaźnik, zwany natychmiastowym współczynnikiem trudności, mierzy, jak bardzo bieżąca predykcja modelu różni się od poprawnej odpowiedzi. Jeśli model jest konsekwentnie pewny i poprawny dla obrazu, uznaje się go za łatwy i mniej istotny do ponownego zobaczenia. Jeśli ma trudności, obraz traktowany jest jako trudny i warto go zachować. Drugi wskaźnik, zmienność trudności, obserwuje, jak te wartości trudności zmieniają się w trakcie treningu. Jeżeli trudność przykładu skacze w górę i w dół, sygnalizuje to niestabilne uczenie lub zapominanie, a metoda traktuje takie przykłady jako szczególnie informacyjne. Łącząc bieżącą trudność z jej ewolucją, PADP buduje pełniejszy obraz tego, nad czym model rzeczywiście powinien ćwiczyć.
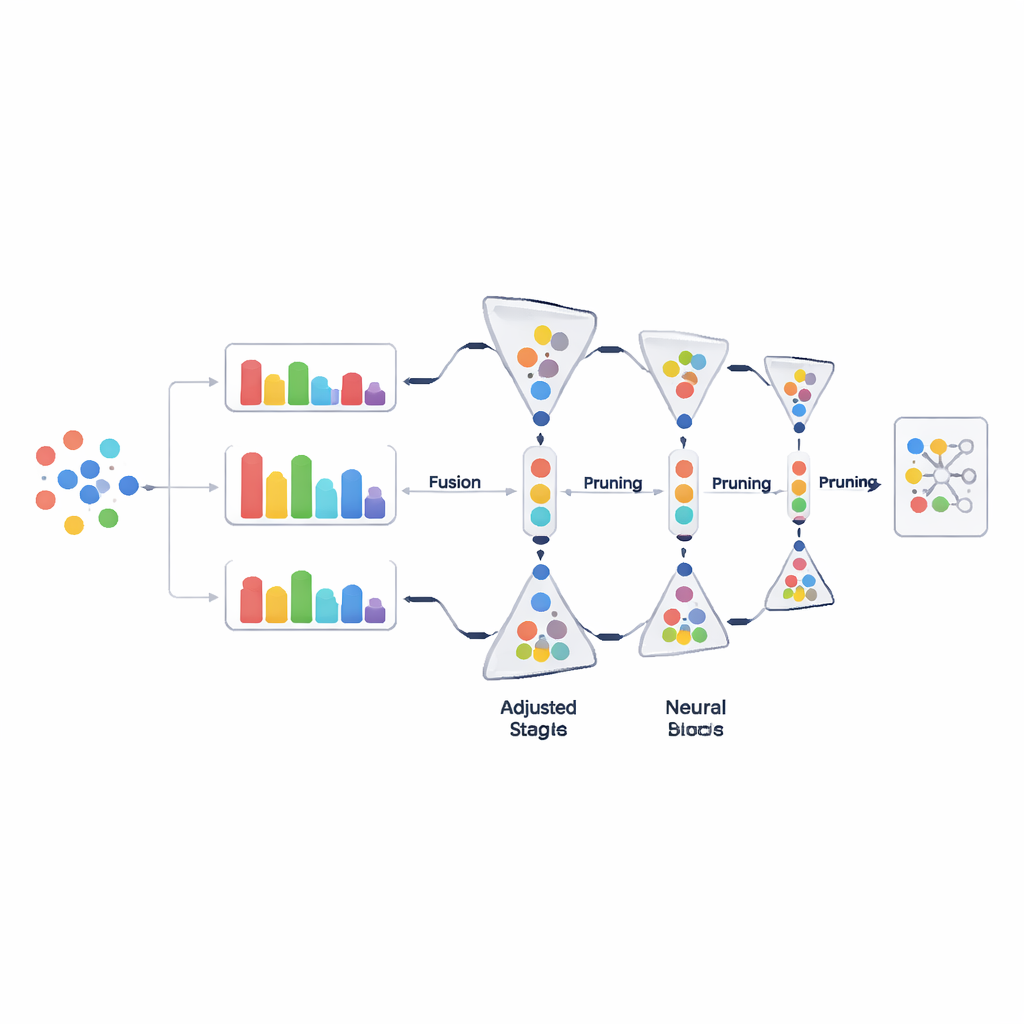
Przycinanie danych krok po kroku, a nie od razu
Zamiast usuwać duże porcje danych w jednej decyzji, PADP stopniowo przycina zbiór treningowy w miarę postępów uczenia. Po początkowym okresie rozgrzewki metoda wielokrotnie ocenia wszystkie aktualnie używane przykłady, sortuje je według złożonego wskaźnika trudności i usuwa część tych, które wydają się najmniej pomocne. Współczynnik przycinania rośnie stopniowo w czasie, więc wczesne decyzje są zachowawcze, a późniejsze bardziej agresywne, gdy zrozumienie modelu się ustabilizuje. Proste, ale ważne zabezpieczenie zapewnia, że każda klasa zachowuje co najmniej minimalną liczbę przykładów, aby rzadkie kategorie nie zostały przypadkowo wyeliminowane. To stopniowe i świadome klasy podejście utrzymuje treningowe zbiory szczupłe bez utraty różnorodności.
Lepsze wyniki przy mniejszym treningu
Badacze przetestowali PADP na dwóch standardowych zbiorach obrazów, CIFAR-100 i Tiny-ImageNet, w kilku scenariuszach uczenia przyrostowego i porównali ją z wieloma istniejącymi technikami doboru lub przycinania danych. W bezpośrednich porównaniach wariant PADP z ustalonymi celami przycinania osiągał wyższą dokładność niż wszystkie metody bazowe przy tych samych poziomach przycinania, a w niektórych przypadkach przewyższał nawet dokładność trenowania na pełnych zbiorach danych. Domyślna, adaptacyjna wersja, która nie wymaga ustalonego wcześniej wskaźnika przycinania, poprawiła dokładność o około do 6 punktów procentowych względem trenowania na pełnych danych, jednocześnie skracając czas treningu nawet o około 53 procent. Metoda została także włączona do kilku różnych ram uczenia przyrostowego i konsekwentnie zmniejszała zapominanie starych klas, przy jednoczesnym zwiększeniu lub przynajmniej utrzymaniu ogólnej dokładności, co sugeruje, że korzyści są szerokie, a nie zależne od konkretnej architektury modelu.
Co to oznacza dla codziennej sztucznej inteligencji
Mówiąc prościej, PADP uczy sieci neuronowe, aby ćwiczyły sprytniej, a nie ciężej. Dzięki ciągłej ocenie, które obrazy są łatwe, które trudne, a które model ciągle musi powtarzać lub zapominać, można odciąć redundantne przykłady treningowe bez szkody dla wydajności — a często nawet ją poprawić. Jednocześnie metoda chroni mniej powszechne klasy przed zniknięciem podczas przycinania. To połączenie wydajności i stabilności jest szczególnie istotne dla systemów AI, które muszą aktualizować się w czasie na urządzeniach o ograniczonych zasobach. Choć obecne badanie koncentruje się na klasyfikacji obrazów, podstawowa idea przycinania danych z uwzględnieniem trudności, prowadzona progresywnie, może pomóc przyszłym systemom w wielu dziedzinach uczyć się nowych umiejętności w locie, nie zapominając tego, co już potrafią.
Cytowanie: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Słowa kluczowe: uczenie przyrostowe, przycinanie danych, wydajność uczenia głębokiego, katastrofalne zapominanie, dobór próbek