Clear Sky Science · ar
PADP: التقليم التقدمي والتكيفي للبيانات من أجل التعلّم التدريجي الفعال
لماذا يهم التعلم الأذكى من بيانات أقل
أنظمة الذكاء الاصطناعي الحديثة تشتهي البيانات وقوة الحوسبة، مما يجعل تدريبها مكلفاً ويصعب تشغيلها على الأجهزة اليومية مثل الهواتف والكاميرات أو الروبوتات المنزلية. وفي الوقت نفسه، تحتاج هذه الأنظمة بشكل متزايد إلى الاستمرار في التعلم مع مرور الوقت عندما تظهر أنواع جديدة من الصور أو السياقات. يقدم هذا البحث طريقة اسمها PADP تساعد الشبكات العصبية على التعلم بكفاءة أكبر عبر اتخاذ قرار أثناء التدريب بشأن أي الأمثلة تستحق الانتباه فعلاً وأيها يمكن تخطيه بأمان، وكل ذلك مع تجنب فقدان المعرفة القديمة المهمة.
تدريب الآلات على خطوات صغيرة
الغالبية العظمى من أنظمة التعرف على الصور تُدرّب مرة واحدة على مجموعة بيانات ثابتة ثم تُنشر. في العالم الواقعي، مع ذلك، تستمر الفئات الجديدة في الظهور: قد يحتاج كاميرا أمنية إلى التعرف على أشياء جديدة، أو قد يواجه نظام طبي أمراضاً جديدة. هذه العملية خطوة بخطوة، المعروفة بالتعلّم التدريجي، تطرح تحدياً رئيسياً: عندما يركز النموذج على فئات جديدة، فإنه يميل إلى نسيان الفئات القديمة، وهي مشكلة تُسمى النسيان الكارثي. وفي الوقت نفسه، فإن التدريب على كل البيانات المتاحة عند كل خطوة جديدة مضيعة وغالباً ما يكون مستحيلاً على أجهزة ذات ذاكرة وقدرة محدودة. يجادل المؤلفون بأنه لجعل التعلّم التدريجي عملياً، نحتاج إلى طرق تقلل جهد التدريب وفي الوقت نفسه تحافظ بعناية على أكثر الأمثلة القديمة والجديدة فائدة.
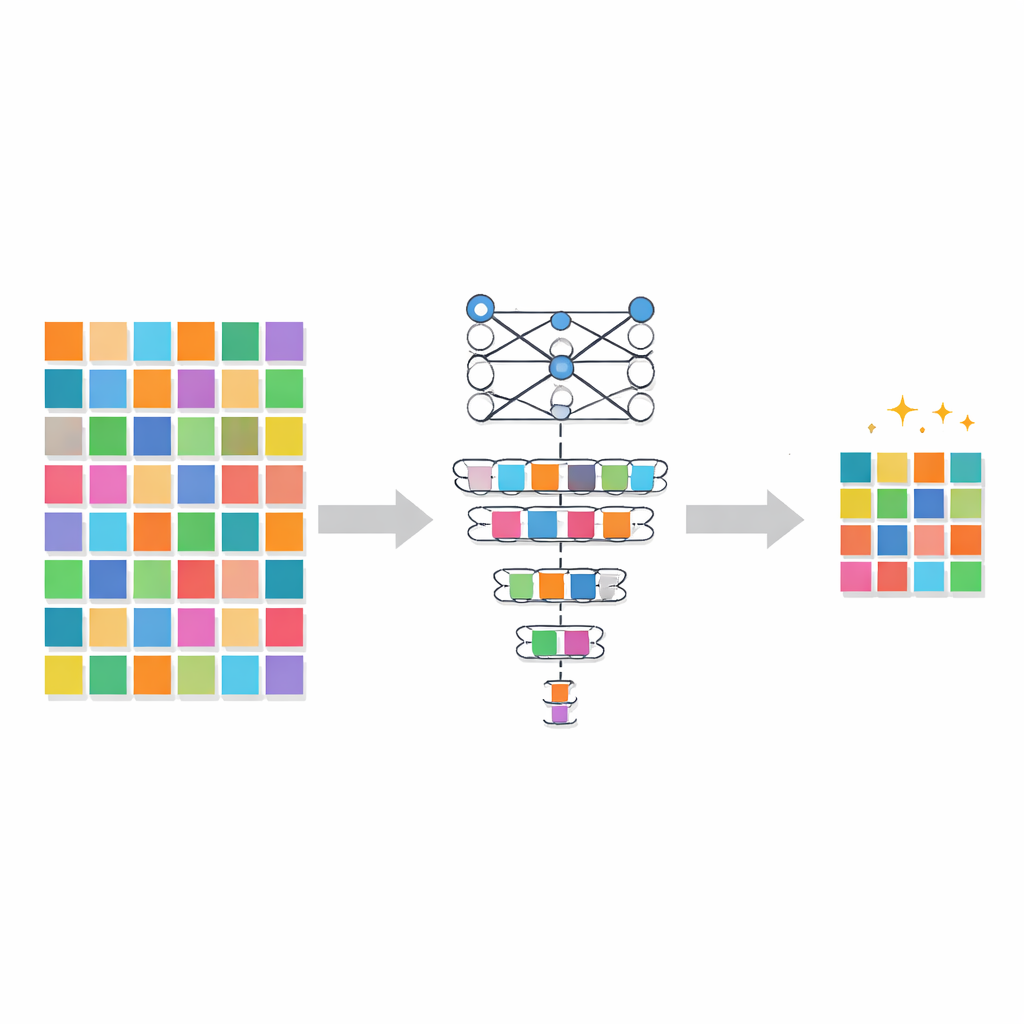
اختيار الأمثلة الصعبة وغير المستقرة
يتعامل PADP مع هذا بتقييم كل مثال تدريبي بناءً على مدى فائدته للنموذج في لحظات زمنية مختلفة. الدرجة الأولى، المسماة درجة الصعوبة اللحظية، تقيس مدى اختلاف توقع النموذج الحالي عن الإجابة الصحيحة. إذا كان النموذج واثقاً وصحيحاً باستمرار بشأن صورة ما، فتوضع هذه الصورة في خانة السهلة وتُعتبر أقل أهمية للعرض مجدداً. أما إذا تعثر النموذج، فتعامل الصورة على أنها صعبة وتستحق الاحتفاظ بها. الدرجة الثانية، تباين درجة الصعوبة، تنظر في كيفية تغيير هذه القيم عبر مسار التدريب. إذا تقلبت صعوبة مثال ما صعوداً وهبوطاً، فإن ذلك يشير إلى تعلم غير مستقر أو نسيان، وتتعامل الطريقة مع مثل هذه الأمثلة على أنها غنية بالمعلومات بشكل خاص. بمزج مدى صعوبة المثال الآن مع كيف تتطور صعوبته، يبني PADP صورة أكثر ثراءً عما يحتاج النموذج فعلاً إلى التدريب عليه.
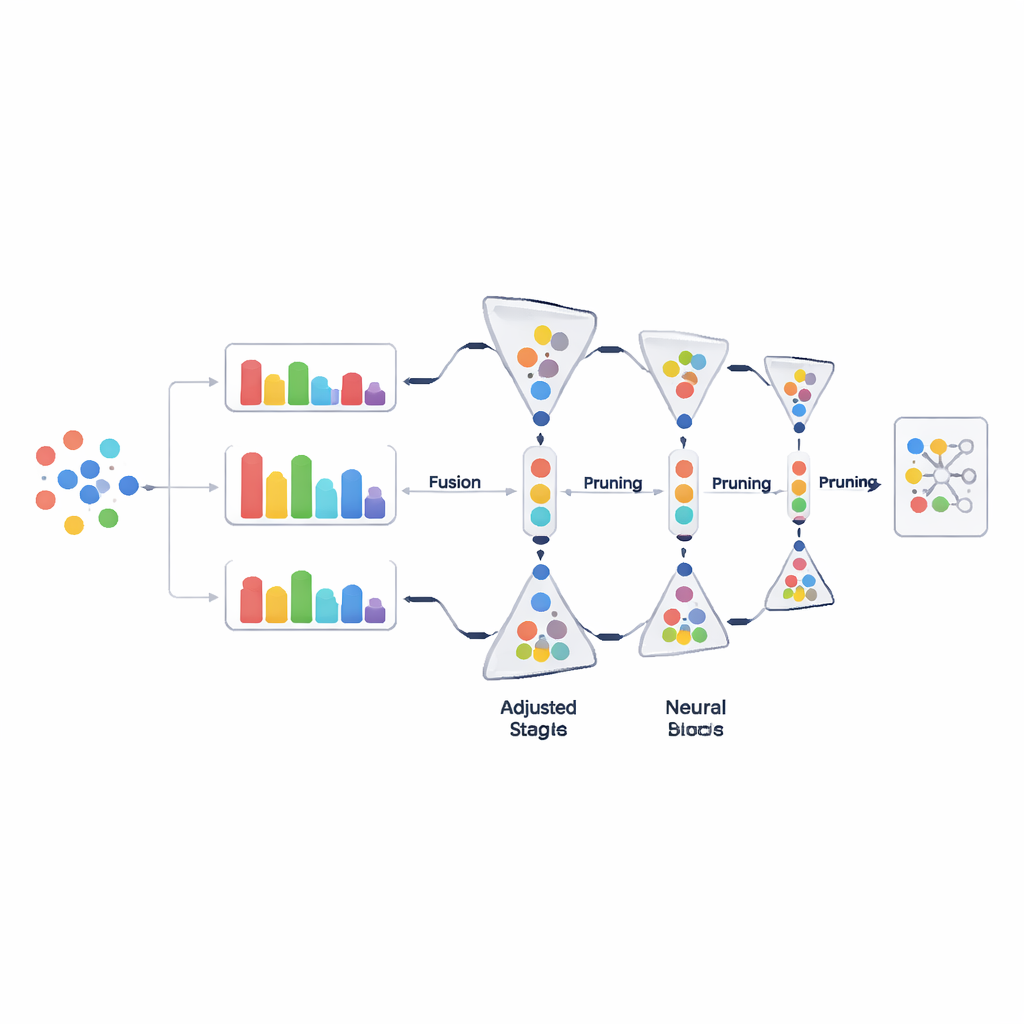
تقليم البيانات خطوة بخطوة، لا دفعة واحدة
بدلاً من حذف أجزاء كبيرة من البيانات في قرار واحد، يقلم PADP مجموعة التدريب بصورة تدريجية مع تقدم التعلم. بعد فترة إحماء أولية، تقوم الطريقة بتقييم جميع الأمثلة المستخدمة حالياً بشكل متكرر، وترتيبها حسب درجة الصعوبة المجمعة، وإزالة جزء من تلك التي تبدو أقل فائدة. نسبة التقليم تزداد تدريجياً مع الوقت، بحيث تكون القرارات المبكرة محافظة واللاحقة أكثر عدوانية بمجرد أن يستقر فهم النموذج. يوجد احتياط بسيط لكنه مهم يضمن أن كل فئة تحتفظ بعدد أدنى من الأمثلة، حتى لا تُمحى الفئات النادرة عن غير قصد. هذا التقليم التدريجي الواعي بالفئة يبقي بيانات التدريب نحيفة دون التضحية بالتنوّع.
نتائج أقوى مع تدريب أقل
اختبر الباحثون PADP على مجموعتين معياريتين من الصور، CIFAR-100 وTiny-ImageNet، تحت عدة إعدادات للتعلّم التدريجي وقارنوها مع العديد من التقنيات القائمة لاختيار أو تقليم البيانات. في مقارنات مباشرة، حقق متغير من PADP بأهداف تقليم ثابتة دقة أعلى من جميع المنهجيات الأساسية عند نفس مستويات التقليم، وحتى تجاوز دقة التدريب على مجموعات البيانات الكاملة في بعض الحالات. النسخة التكيفية الافتراضية، التي لا تتطلب نسبة تقليم سابقة التحديد، حسّنت الدقة بما يصل إلى نحو 6 نقاط مئوية مقارنة بتدريب البيانات الكاملة مع تقليل زمن التدريب بما يصل تقريباً إلى 53 في المئة. كما التُفت الطريقة إلى عدة أُطُر مختلفة للتعلّم التدريجي وقلّلت باستمرار من نسيان الفئات القديمة مع تعزيز أو على الأقل الحفاظ على الدقة الإجمالية، مما يشير إلى أن فوائدها واسعة النطاق وليست مقصورة على تصميم نموذج واحد.
ما يعنيه هذا للذكاء الاصطناعي اليومي
بعبارة بسيطة، يعلم PADP الشبكات العصبية أن تتدرّب بذكاء، لا بمجهود أكبر. من خلال الحكم المستمر على أي الصور سهلة، وأيها معقدة، وأيها يعيد النموذج تعلمها أو ينسىها، يمكنه اقتطاع بيانات التدريب المكررة دون الإضرار بالأداء—وغالباً ما يحسّنه أيضاً. وفي الوقت نفسه، يحمي الفئات الأقل شيوعاً من الاختفاء أثناء هذا التقليم. يجمع هذا المزيج من الكفاءة والثبات أهمية خاصة لأنظمة الذكاء الاصطناعي التي يجب أن تحدّث نفسها بمرور الوقت على أجهزة محدودة الموارد. ومع أن العمل الحالي يركّز على تصنيف الصور، فإن الفكرة الأساسية للتقليم التقدمي الواعي بالصعوبة يمكن أن تساعد الأنظمة المستقبلية في مجالات عديدة على تعلم مهارات جديدة أثناء التشغيل دون نسيان ما تعلمته سابقاً.
الاستشهاد: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
الكلمات المفتاحية: التعلّم التدريجي, تقليم البيانات, كفاءة التعلّم العميق, النسيان الكارثي, اختيار العينات