Clear Sky Science · it
PADP: potatura progressiva e adattiva dei dati per l’apprendimento incrementale efficiente
Perché è importante imparare meglio con meno dati
I moderni sistemi di intelligenza artificiale sono affamati di dati e potenza di calcolo, il che li rende costosi da addestrare e difficili da eseguire su dispositivi di uso quotidiano come telefoni, fotocamere o robot domestici. Allo stesso tempo, questi sistemi devono sempre più spesso continuare ad apprendere nel tempo man mano che emergono nuovi tipi di immagini o situazioni. Questo articolo presenta un metodo chiamato PADP che aiuta le reti neurali a imparare in modo più efficiente decidendo, durante l’addestramento, quali esempi meritano davvero attenzione e quali possono essere saltati senza rischiare la perdita di conoscenze importanti del passato.
Insegnare alle macchine passo dopo passo
La maggior parte dei sistemi di riconoscimento delle immagini viene addestrata una volta su un insieme fisso di dati e poi distribuita. Nel mondo reale, però, continuano a emergere nuove categorie: una telecamera di sicurezza potrebbe dover riconoscere nuovi oggetti, o un sistema medico potrebbe affrontare nuove malattie. Questo processo graduale, noto come apprendimento incrementale, porta con sé una sfida importante: quando un modello si concentra sulle nuove classi tende a dimenticare quelle vecchie, un problema chiamato dimenticanza catastrofica. Allo stesso tempo, addestrare su tutti i dati disponibili a ogni nuovo passo è inefficiente e spesso impossibile su dispositivi con memoria e potenza limitate. Gli autori sostengono che, per rendere pratico l’apprendimento incrementale, servono metodi che riducano lo sforzo di addestramento e preservino con cura gli esempi più utili, sia vecchi che nuovi.
Selezionare esempi difficili e instabili
PADP affronta il problema assegnando a ogni esempio di addestramento un punteggio che misura quanto sia utile per il modello in diversi momenti. Il primo punteggio, chiamato punteggio di difficoltà istantanea, quantifica quanto la previsione corrente del modello si discosta dalla risposta corretta. Se il modello è costantemente sicuro e corretto su un’immagine, quell’immagine viene considerata facile e meno critica da rivedere. Se fa fatica, l’immagine è trattata come difficile e meritevole di conservazione. Il secondo punteggio, la variazione della difficoltà, osserva come questi valori di difficoltà cambiano nel corso dell’addestramento. Se la difficoltà di un esempio oscilla, ciò segnala un apprendimento instabile o dimenticanza, e il metodo considera tali esempi particolarmente informativi. Combinando quanto un esempio è difficile in un dato momento con come la sua difficoltà evolve, PADP costruisce un quadro più ricco di ciò su cui il modello ha veramente bisogno di esercitarsi.
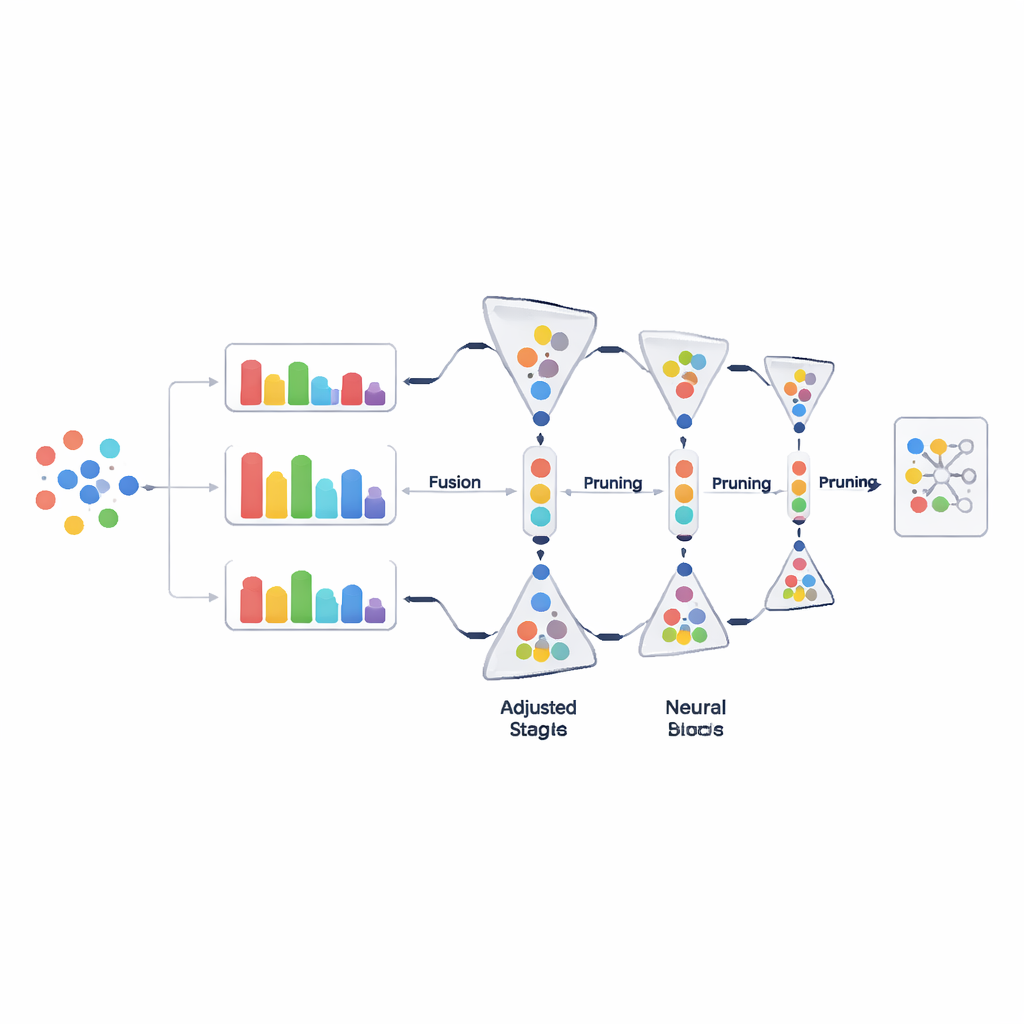
Potare i dati passo dopo passo, non in un’unica volta
Invece di eliminare grandi porzioni di dati in un’unica decisione, PADP pota progressivamente il set di addestramento man mano che l’apprendimento procede. Dopo un periodo iniziale di riscaldamento, il metodo valuta ripetutamente tutti gli esempi attualmente utilizzati, li classifica in base al punteggio di difficoltà combinato e rimuove una porzione di quelli che sembrano meno utili. Il tasso di potatura cresce gradualmente nel tempo, così le decisioni iniziali sono conservative e quelle successive diventano più aggressive una volta che la comprensione del modello si è stabilizzata. Una salvaguardia semplice ma importante assicura che ogni classe mantenga almeno un numero minimo di esempi, in modo che le categorie rare non vengano cancellate involontariamente. Questa cesellatura graduale e attenta alle classi mantiene il set di addestramento snello senza sacrificare la varietà.
Risultati più forti con meno addestramento
I ricercatori hanno testato PADP su due raccolte standard di immagini, CIFAR-100 e Tiny-ImageNet, in diversi scenari di apprendimento incrementale e lo hanno confrontato con molte tecniche esistenti per la selezione o la potatura dei dati. Nei confronti diretti, una variante di PADP con obiettivi di potatura fissi ha raggiunto un’accuratezza superiore a tutte le baseline agli stessi livelli di potatura, e in alcuni casi ha persino superato l’accuratezza ottenuta addestrando sui dataset completi. La versione adattiva predefinita, che non richiede una percentuale di potatura preimpostata, ha migliorato l’accuratezza fino a circa 6 punti percentuali rispetto all’addestramento su tutti i dati, riducendo al contempo il tempo di addestramento fino a circa il 53%. Il metodo è stato integrato in diversi framework di apprendimento incrementale e ha costantemente ridotto la dimenticanza delle classi precedenti mantenendo o migliorando l’accuratezza complessiva, suggerendo che i vantaggi sono ampi e non legati a un singolo disegno di modello.
Cosa significa per l’IA di tutti i giorni
In termini semplici, PADP insegna alle reti neurali a esercitarsi in modo più intelligente, non più intenso. Giudicando continuamente quali immagini sono facili, quali sono ostiche e quali il modello continua a riapprendere o dimenticare, può eliminare i dati di addestramento ridondanti senza compromettere le prestazioni—e spesso migliorandole. Allo stesso tempo, protegge le classi meno comuni dall’essere eliminate durante la potatura. Questa combinazione di efficienza e stabilità è particolarmente importante per i sistemi di IA che devono aggiornarsi nel tempo su dispositivi con risorse limitate. Sebbene il lavoro attuale si concentri sulla classificazione delle immagini, l’idea di base di una potatura progressiva e consapevole della difficoltà potrebbe aiutare i futuri sistemi in molti domini a imparare nuove abilità al volo senza dimenticare ciò che già sanno.
Citazione: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Parole chiave: apprendimento incrementale, potatura dei dati, efficienza nel deep learning, dimenticanza catastrofica, selezione dei campioni