Clear Sky Science · ru
Подход STDFT-CEEMD с вейвлетной пороговой обработкой для предсказания экзонов в эукариотических клетках
Нахождение полезных частей нашего генетического кода
Внутри каждой клетки длинные цепочки ДНК содержат инструкции по созданию белков, которые поддерживают жизнь организма. Но только определённые участки этой ДНК действительно кодируют белки, тогда как большие фрагменты выполняют роль знаков препинания или фоновой информации. В этой работе рассматривается ключевая задача современной генетики: как надёжно обнаруживать белок-кодирующие фрагменты, называемые экзонами, в огромных объёмах сырых данных ДНК с помощью продуманных инструментов обработки сигналов, заимствованных у инженерии.
Почему важно отделять сигнал от шума
Гены у человека и других сложных организмов разбиты на экзоны, которые несут полезные инструкции, и интроны, которые их не несут. В процессе синтеза белка клетки копируют ДНК в РНК, затем вырезают интроны и сшивают экзоны в итоговое сообщение, определяющее состав белка. Определение начала и конца экзонов важно для понимания работы генов, причин возникновения заболеваний и возможности индивидуализации лечения. Традиционные компьютерные методы сильно зависят от больших, тщательно размеченных тренировочных наборов или подробных биологических моделей, которые не всегда доступны или могут давать сбои для малоизученных видов. Поэтому методы, работающие напрямую с сырой ДНК, рассматривая её как сигнал для анализа, становятся всё более привлекательными.
Преобразование ДНК в сигнал
В этом исследовании авторы рассматривают ДНК как волну, похожую на аудиодорожку, и применяют последовательность шагов обработки. Сначала каждая из четырёх букв ДНК переводится в числа с помощью специальной схемы на основе матриц Хадамара — тщательно подобранных шаблонов из плюс и минус единиц. Этот шаг создаёт четыре числовые дорожки, которые сохраняют всю информацию исходной последовательности, но лучше подходят для анализа. Затем метод сканирует последовательность скользящим окном и использует инструмент временно-частотного анализа, называемый коротковременным дискретным преобразованием Фурье (STDFT), чтобы искать повторяющийся паттерн с периодом в три основания. Этот «период-3» — хорошо известная особенность белок-кодирующих регионов, потому что белки строятся из трёхбуквенных слов, или кодонов, в генетическом коде.
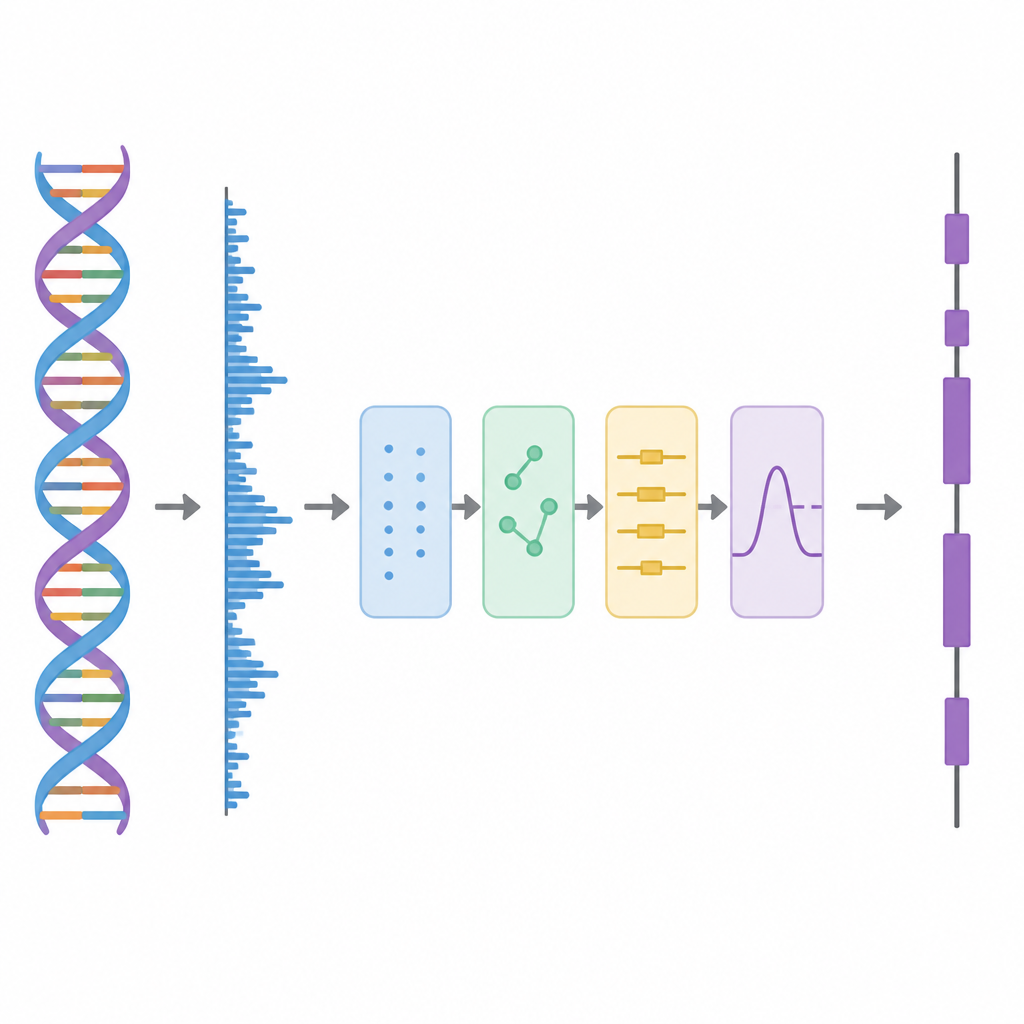
Разделение слоёв сигнала
Реальные геномные данные шумны. Долгопериодные фоновые тенденции и случайные флуктуации могут размывать период-3, особенно в коротких экзонах. Чтобы с этим справиться, авторы заимствуют идею из продвинутого разложения сигналов, где сложную волну разбивают на более простые составляющие. Они используют метод Complete Ensemble Empirical Mode Decomposition (CEEMD), который многократно добавляет сбалансированный шум и усредняет результаты, получая набор более чистых компонент. Затем мера самокорреляции применяется для решения, какие из этих компонент несут значимую структуру, а какие доминируются шумом. Шумные компоненты дополнительно очищаются с помощью пороговой обработки вейвлет-пакетов, метода, который отсекает мелкие дрожащие вариации, сохраняя основную форму сигнала.
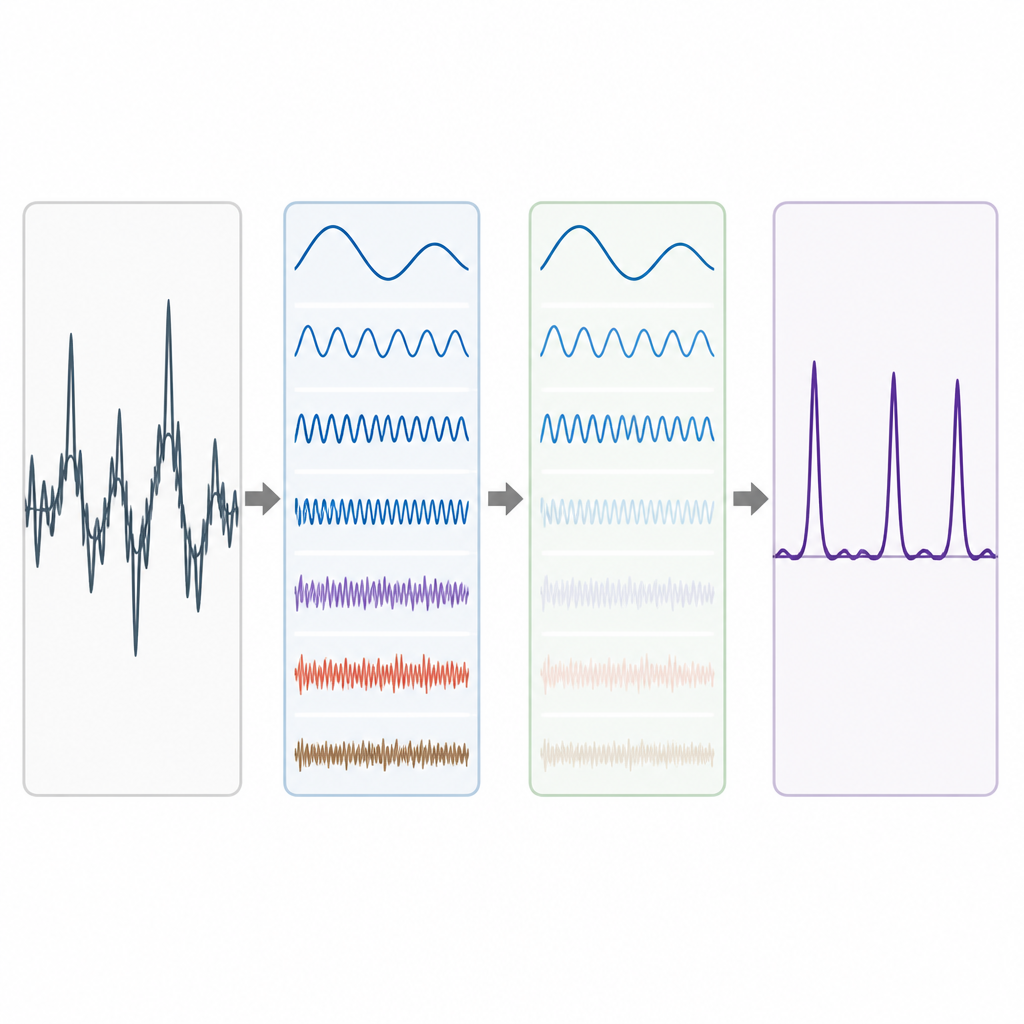
Тестирование метода на реальных генах
Чтобы проверить, насколько хорошо работает их конвейер, авторы применяют его к хорошо изученным генам круглого червя Caenorhabditis elegans и домашней мыши, а также к эталонной коллекции из 195 сегментов генов человека, мыши и крысы. В каждом случае они сравнивают свои предсказания экзонов с экспертными аннотациями. Их подход даёт более чёткие пики в местах, где действительно находятся экзоны, и более низкий фон в некодирующих регионах. При суммировании показателей с помощью общепринятых метрик — чувствительности, специфичности, точности и площади под ROC-кривой — их метод стабильно превосходит несколько предыдущих подходов обработки сигналов, которые опирались на более простые фильтры или менее тщательные разложения. Преимущества особенно заметны в балансе между корректным обнаружением экзонов и снижением числа ложных срабатываний.
Что это значит для геномного анализа
Главный вывод для читателей заключается в том, что авторы создали более точное «слуховое устройство» для генома. Тщательно отображая ДНК в числовую форму, отслеживая её ритмы в коротких окнах, разлагая сигнал на чистые компоненты и целенаправленно удаляя шум, они получают гораздо более отчётливую картину расположения белок-кодирующих инструкций. Хотя текущая реализация может быть вычислительно тяжёлой и всё ещё требует настройки некоторых параметров, эта структура показывает, что инструменты современной обработки сигналов могут существенно улучшить чтение генома. В долгосрочной перспективе такие методы могут помочь учёным быстрее аннотировать новые геномы и поддержать дальнейшие исследования функции генов, механизмов заболеваний и персонализированной медицины.
Цитирование: Benarjee, S., Vaegae, N.K. A STDFT-CEEMD approach with wavelet packet thresholding for exon prediction in eukaryotic cells. Sci Rep 16, 15948 (2026). https://doi.org/10.1038/s41598-026-43722-2
Ключевые слова: предсказание экзонов, геномная обработка сигналов, анализ ДНК, области, кодирующие белки, подавление шума