Clear Sky Science · nl
Een STDFT-CEEMD-benadering met wavelet-pakket-drempeling voor exonvoorspelling in eukaryote cellen
De nuttige delen van onze genetische code vinden
In elke cel dragen lange DNA-ketens instructies voor het bouwen van de eiwitten die ons in leven houden. Maar slechts bepaalde stukken van dit DNA coderen daadwerkelijk voor eiwitten, terwijl grote secties meer als interpunctie of achtergrond functioneren. Dit artikel pakt een belangrijke uitdaging in de moderne genetica aan: hoe je betrouwbaar de eiwit-coderende stukken, exonen genoemd, kunt opsporen in enorme hoeveelheden rauwe DNA-gegevens met slimme signaalverwerkingstools uit de techniek.
Waarom het onderscheiden van signaal en ruis belangrijk is
Genen in mensen en andere complexe organismen zijn opgesplitst in exonen, die nuttige instructies bevatten, en intronen, die dat niet doen. Tijdens de eiwitproductie kopiëren cellen DNA naar RNA en knippen dan de intronen eruit, waarna exonen aan elkaar worden gehecht tot een eindboodschap die de samenstelling van een eiwit bepaalt. Het identificeren waar exonen beginnen en eindigen is cruciaal om te begrijpen hoe genen werken, hoe ziekten ontstaan en hoe behandelingen kunnen worden toegesneden. Traditionele computermethoden vertrouwen sterk op grote, zorgvuldig gelabelde trainingsgegevens of gedetailleerde biologische modellen, die niet altijd beschikbaar zijn of kunnen falen bij slecht bestudeerde soorten. Daarom zijn methoden die direct op rauw DNA kunnen werken en het als een signaal behandelen aantrekkelijker geworden.
DNA omzetten in een signaal
In deze studie behandelen de auteurs DNA alsof het een golfvorm is, vergelijkbaar met een audiotrack, en passen vervolgens een reeks verwerkingsstappen toe. Eerst wordt elk van de vier DNA-letters omgezet in cijfers met een speciaal schema gebaseerd op Hadamard-matrices, dit zijn zorgvuldig gekozen patronen van plus- en min-één. Deze stap creëert vier schone numerieke sporen die alle informatie uit de oorspronkelijke sequentie behouden maar beter geschikt zijn voor analyse. Vervolgens scant de methode de sequentie met een schuivend venster en gebruikt een tijd–frequentietool, de Short-Time Discrete Fourier Transform, om te zoeken naar een herhalend patroon dat elke drie basen voorkomt. Dit “periode-3”-ritme is een bekend kenmerk van eiwit-coderende regio’s omdat eiwitten worden opgebouwd uit drieletterwoorden, of codons, in de genetische code.
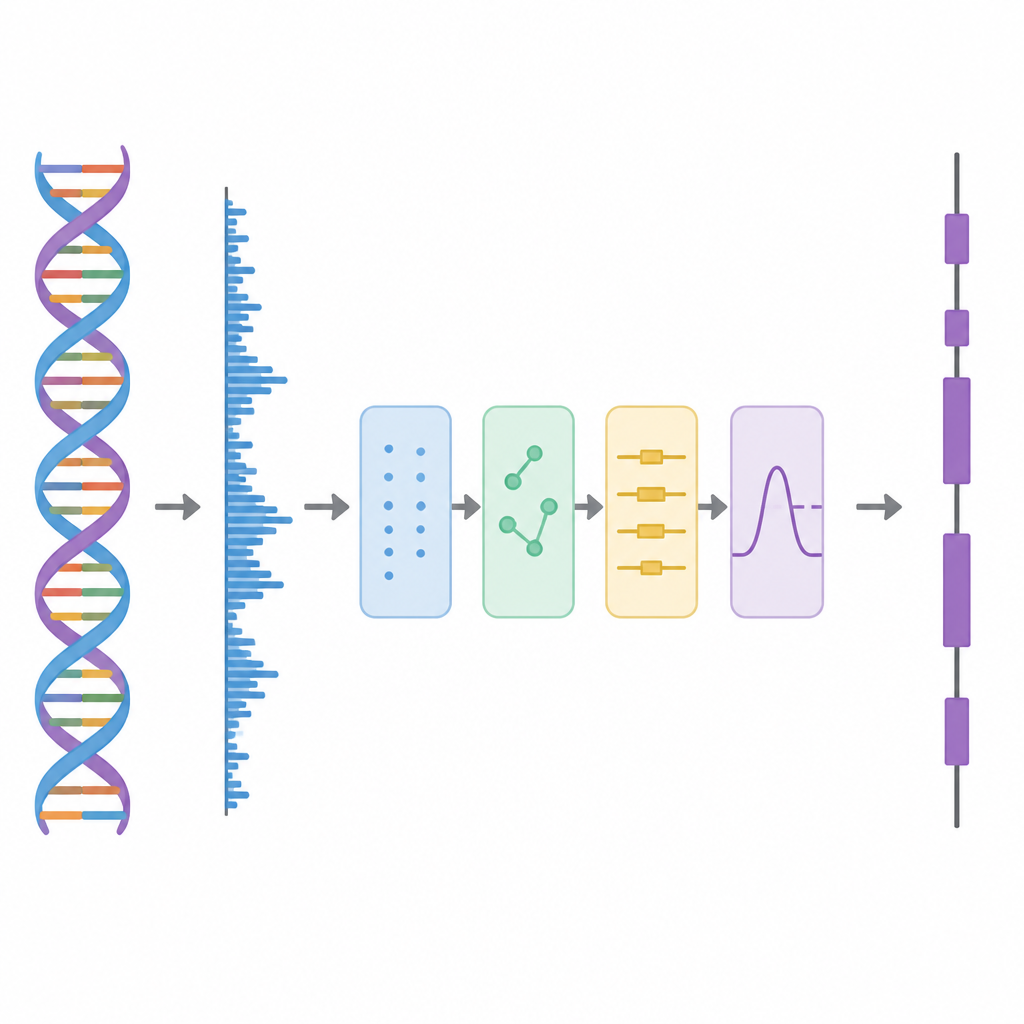
De lagen van het signaal afpellen
Reële genomische data zijn rommelig. Langsaflopende achtergrondtrends en willekeurige fluctuaties kunnen het periode-3-patroon vervagen, vooral bij korte exonen. Om dit aan te pakken lenen de auteurs een idee uit geavanceerde signaaldecompositie, waarbij een ingewikkelde golfvorm wordt opgesplitst in eenvoudigere bouwstenen. Ze gebruiken een techniek die Complete Ensemble Empirical Mode Decomposition heet, waarbij herhaaldelijk zorgvuldig uitgebalanceerde ruis wordt toegevoegd en de resultaten vervolgens gemiddeld om een set schonere componenten te produceren. Een zelfcorrelatiemaat wordt daarna gebruikt om te beslissen welke van deze componenten betekenisvolle structuur bevatten en welke door ruis worden gedomineerd. De rumoerige componenten worden verder opgeschoond met wavelet-pakket-drempeling, een methode die kleine, trillende variaties wegknipt terwijl de hoofdvorm van het signaal behouden blijft.
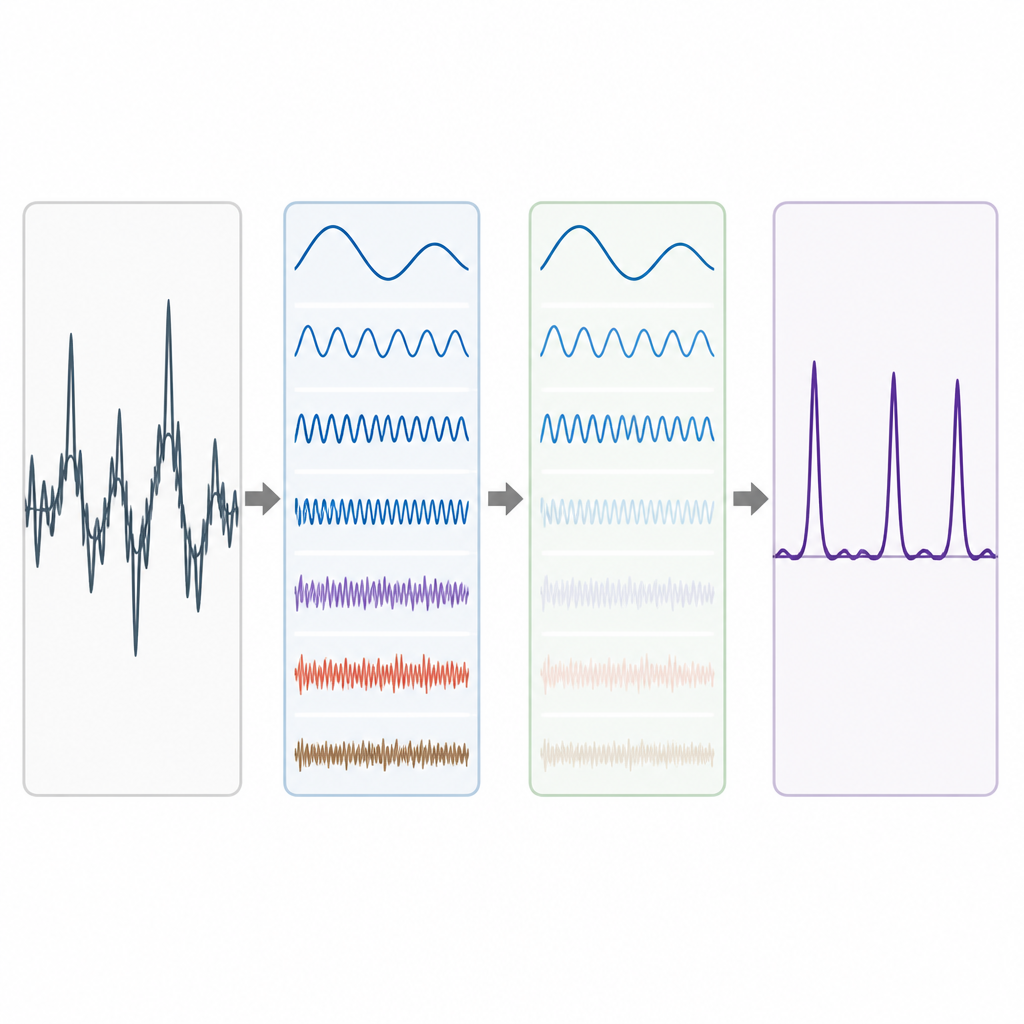
De methode testen op echte genen
Om te zien hoe goed hun pijplijn werkt, passen de auteurs deze toe op goed bestudeerde genen van de aaltje Caenorhabditis elegans en de huismuis, en op een benchmarkverzameling van 195 gensegmenten van mens, muis en rat. In elk geval vergelijken ze hun exonvoorspellingen met deskundige annotaties. Hun benadering produceert duidelijkere pieken waar echte exonen voorkomen en een lagere achtergrond in regio’s die geen eiwitten coderen. Wanneer ze de prestaties samenvatten met gangbare maten zoals sensitiviteit, specificiteit, nauwkeurigheid en de oppervlakte onder de ROC-curve, presteert hun methode consequent beter dan verschillende eerdere signaalverwerkingsbenaderingen die afhankelijk waren van eenvoudigere filters of minder verfijnde decomposities. De verbeteringen zijn vooral opvallend in het balanceren van correcte detectie van exonen en het vermijden van vals alarm.
Wat dit betekent voor genomische analyse
Voor lezers is de belangrijkste conclusie dat de auteurs een preciezer “luisterinstrument” voor het genoom hebben gebouwd. Door DNA zorgvuldig naar cijfers te mapen, ritmes over korte vensters te volgen, het signaal in schone componenten af te pellen en ruis doelgericht te verwijderen, verkrijgen ze een veel scherper beeld van waar de eiwit-coderende instructies liggen. Hoewel de huidige implementatie rekenintensief kan zijn en nog afstemming van bepaalde instellingen vereist, toont dit kader aan dat tools uit de moderne signaalverwerking zinvol kunnen verbeteren hoe we het genoom lezen. Op de lange termijn zouden dergelijke methoden wetenschappers kunnen helpen nieuwe genomen sneller te annoteren en ondersteunde vervolgonderzoeken naar genfunctie, ziekteprocessen en gepersonaliseerde geneeskunde mogelijk te maken.
Bronvermelding: Benarjee, S., Vaegae, N.K. A STDFT-CEEMD approach with wavelet packet thresholding for exon prediction in eukaryotic cells. Sci Rep 16, 15948 (2026). https://doi.org/10.1038/s41598-026-43722-2
Trefwoorden: exonvoorspelling, genomische signaalverwerking, DNA-analyse, eiwitcoderende regio's, ruisonderdrukking