Clear Sky Science · it
Un approccio STDFT-CEEMD con sogliatura tramite pacchetti wavelet per la predizione degli esoni nelle cellule eucariotiche
Trovare le parti utili del nostro codice genetico
All’interno di ogni cellula, lunghe stringhe di DNA contengono istruzioni per costruire le proteine che mantengono in vita gli organismi. Ma solo alcuni tratti di questo DNA codificano effettivamente proteine, mentre ampie sezioni svolgono ruoli più simili a punteggiatura o sfondo. Questo articolo affronta una sfida chiave nella genetica moderna: come individuare in modo affidabile i frammenti che codificano proteine, chiamati esoni, all’interno di grandi quantità di dati grezzi del DNA usando strumenti intelligenti di elaborazione del segnale presi in prestito dall’ingegneria.
Perché separare segnale e rumore è importante
I geni negli esseri umani e in altri organismi complessi sono spezzettati in esoni, che contengono istruzioni utili, e introni, che non lo fanno. Durante la produzione delle proteine, le cellule copiano il DNA in RNA e poi eliminano gli introni, cucendo insieme gli esoni in un messaggio finale che determina la composizione della proteina. Identificare dove gli esoni iniziano e finiscono è cruciale per comprendere come funzionano i geni, come insorgono le malattie e come i trattamenti possano essere personalizzati. I metodi tradizionali basati su calcolo fanno ampio uso di grandi dataset di addestramento accuratamente etichettati o di modelli biologici dettagliati, che non sono sempre disponibili o possono fallire su specie poco studiate. Per questo motivo, sono sempre più interessanti i metodi in grado di lavorare direttamente sul DNA grezzo, trattandolo come un segnale da analizzare.
Trasformare il DNA in un segnale
In questo studio, gli autori trattano il DNA come se fosse una forma d’onda, simile a una traccia audio, e applicano una sequenza di passaggi di elaborazione. Innanzitutto, ciascuna delle quattro lettere del DNA viene trasformata in numeri usando uno schema basato su matrici di Hadamard, che sono pattern di più e meno uno scelti con cura. Questo passaggio crea quattro tracce numeriche pulite che conservano tutte le informazioni della sequenza originale ma sono meglio adatte all’analisi. Successivamente, il metodo scorre lungo la sequenza con una finestra mobile e utilizza uno strumento tempo–frequenza chiamato Trasformata di Fourier Discreta a Tempo Breve per cercare un pattern ripetuto che compare ogni tre basi. Questo ritmo “periodo-3” è una caratteristica nota delle regioni codificanti perché le proteine sono costruite da parole di tre lettere, o codoni, nel codice genetico.
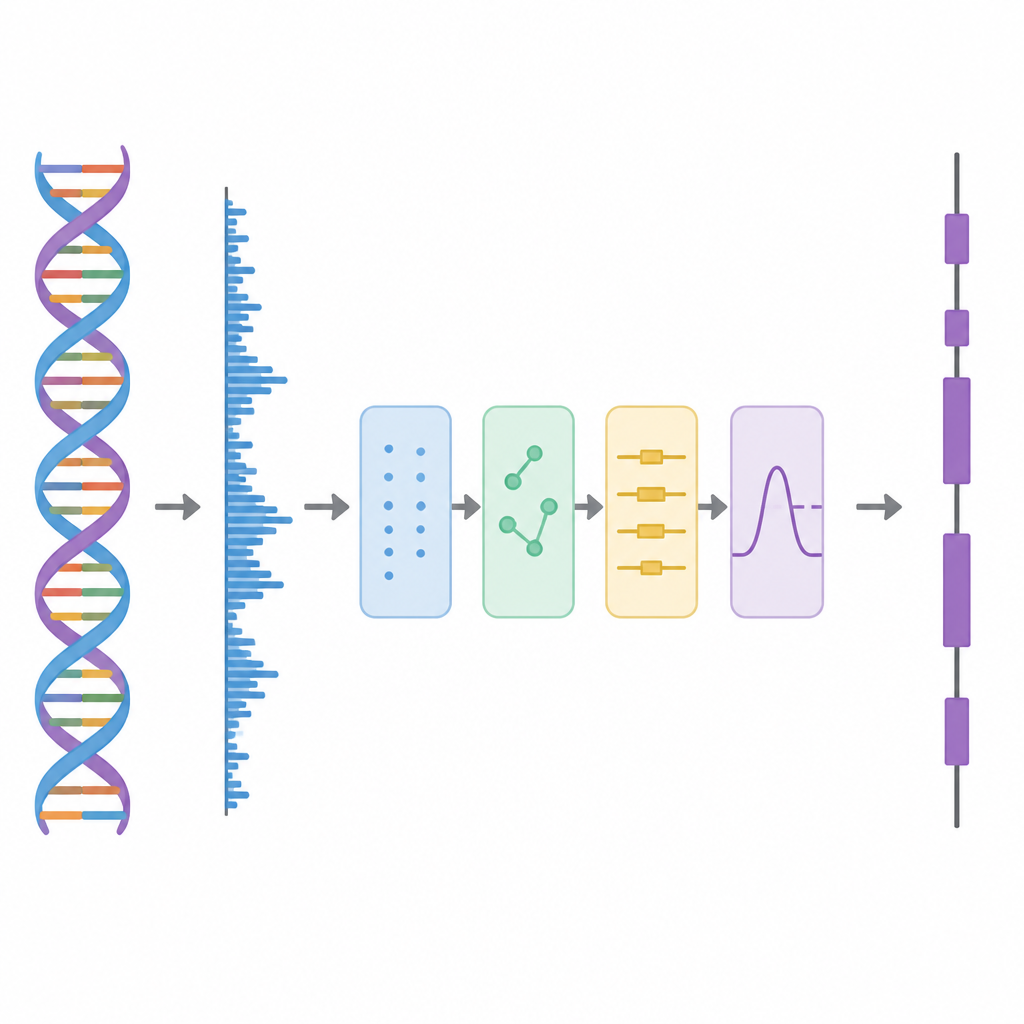
Sbucciare gli strati del segnale
I dati genomici reali sono disordinati. Tendenze di fondo a lunga scala e fluttuazioni casuali possono offuscare il pattern a periodo-3, specialmente per esoni corti. Per affrontare questo problema, gli autori prendono in prestito un’idea dalla decomposizione avanzata del segnale, nella quale una forma d’onda complessa viene scomposta in blocchi costitutivi più semplici. Utilizzano una tecnica chiamata Complete Ensemble Empirical Mode Decomposition, che aggiunge ripetutamente rumore bilanciato e poi media i risultati per produrre un insieme di componenti più pulite. Una misura di autocorrelazione viene quindi usata per decidere quali di queste componenti contengono struttura significativa e quali sono dominate dal rumore. Le parti rumorose vengono ulteriormente pulite usando la sogliatura con pacchetti wavelet, un metodo che elimina piccole variazioni tremolanti preservando la forma principale del segnale.
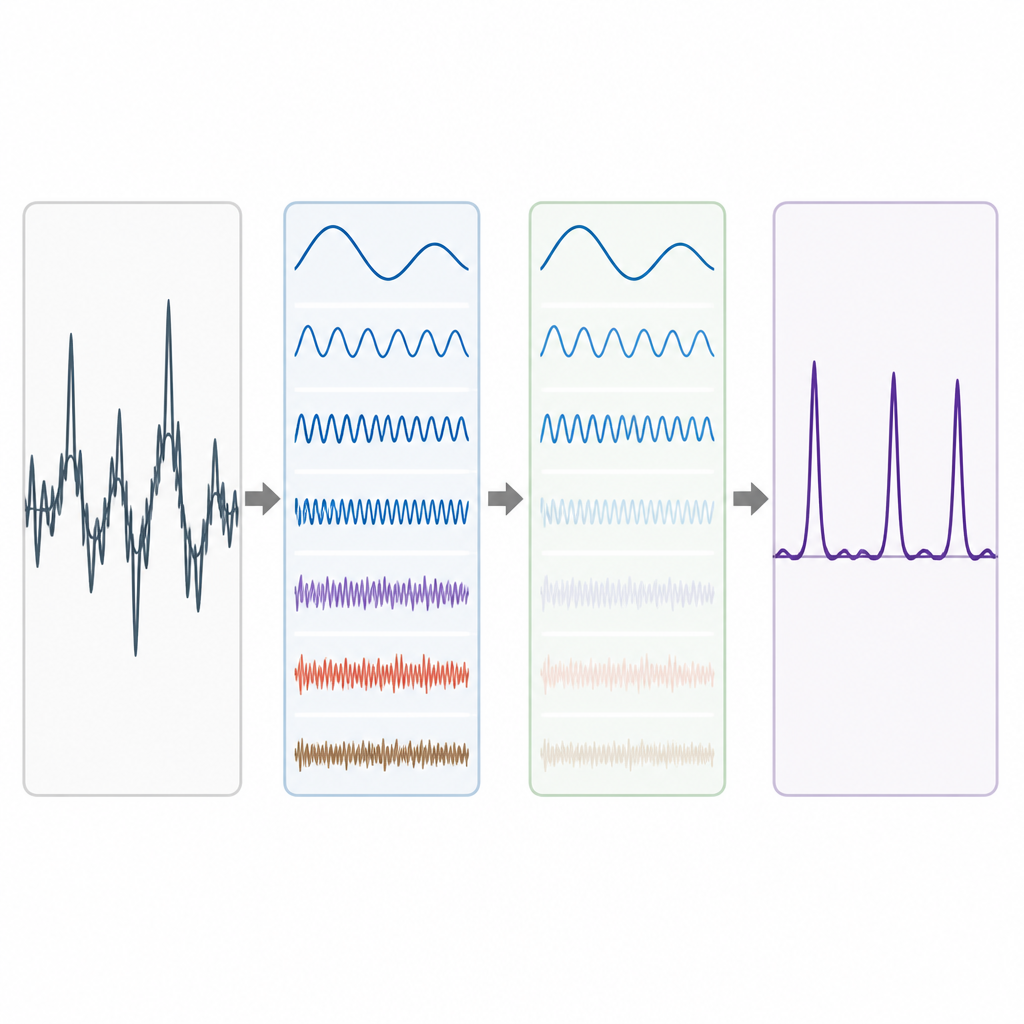
Testare il metodo su geni reali
Per valutare l’efficacia della loro pipeline, gli autori la applicano a geni ben studiati del verme Caenorhabditis elegans e del topo domestico, oltre che a una raccolta di riferimento di 195 segmenti genici umani, murini e di ratto. In ogni caso confrontano le loro predizioni degli esoni con annotazioni di esperti. Il loro approccio produce picchi più netti dove si trovano i veri esoni e uno sfondo più basso nelle regioni non codificanti. Quando riassumono le prestazioni usando misure comuni come sensibilità, specificità, accuratezza e area sotto la curva ROC, il loro metodo supera costantemente diversi approcci di elaborazione del segnale precedenti che si basano su filtri più semplici o decomposizioni meno raffinate. I miglioramenti sono particolarmente evidenti nell’equilibrio tra rilevamento corretto degli esoni e riduzione dei falsi allarmi.
Cosa significa per l’analisi genomica
Per il lettore, la conclusione principale è che gli autori hanno costruito un “dispositivo d’ascolto” più preciso per il genoma. Mappando con cura il DNA in numeri, tracciandone i ritmi su finestre brevi, scomponendo il segnale in componenti pulite e rimuovendo il rumore in modo mirato, ottengono una visione molto più nitida di dove si trovano le istruzioni che codificano le proteine. Sebbene l’implementazione attuale possa essere computazionalmente intensa e richieda ancora la messa a punto di alcuni parametri, il quadro dimostra che gli strumenti dell’elaborazione moderna del segnale possono migliorare in modo significativo il modo in cui leggiamo il genoma. A lungo termine, tali metodi potrebbero aiutare gli scienziati ad annotare nuovi genomi più rapidamente e supportare studi successivi sulla funzione genica, i meccanismi delle malattie e la medicina personalizzata.
Citazione: Benarjee, S., Vaegae, N.K. A STDFT-CEEMD approach with wavelet packet thresholding for exon prediction in eukaryotic cells. Sci Rep 16, 15948 (2026). https://doi.org/10.1038/s41598-026-43722-2
Parole chiave: predizione degli esoni, elaborazione del segnale genomico, analisi del DNA, regioni codificanti proteine, riduzione del rumore