Clear Sky Science · ru
SLA-ориентированное глубокое обучение с подкреплением для адаптивного планирования задач в EdgeCloud
Почему умное распределение цифрового трафика важно
От умных камер на углах улиц до медицинских датчиков на запястьях — миллиарды мелких устройств постоянно отправляют данные, которые нужно обработать где-то между нашими телефонами, находящимися поблизости edge-серверами и отдалёнными облачными центрами. Выполнить все эти цифровые задачи вовремя, не растрачивая энергию впустую, оказывается удивительно сложно. Когда одновременно поступает слишком много заданий, некоторые не укладываются в обещанные сроки отклика, известные как соглашения об уровне сервиса (SLA). В этой работе исследуется новый способ балансировки конкурирующих требований с помощью обучающего планировщика, который адаптируется в реальном времени, сокращая задержки и энергопотребление и лучше соблюдая эти обязательства.
Текущие правила планирования не справляются
Большинство современных планировщиков в системах edge–cloud следуют простым правилам: обрабатывать запросы в порядке поступления, чередовать серверы справедливо или отдавать приоритет ближайшему дедлайну. Эти стратегии не учитывают, насколько важна каждая задача для пользователя и какова вероятность нарушения её временного или энергетического обещания. Многие новые методы используют глубокое обучение с подкреплением — ПО, которое учится методом проб и ошибок — чтобы размещать задачи более умно. Но даже они обычно рассматривают все задачи как равные и опираются на фиксированные пороги вместо постоянного отслеживания, насколько близка каждая задача к реальной проблеме. В результате в среднем они могут выглядеть хорошо, но при этом допускать срывы у самых критичных заданий.
Придание задачам чувства срочности и риска
Авторы предлагают планировщик, который рассматривает каждую входящую задачу через призму её сервисного обещания. Каждая задача помещается в один из трёх уровней — Золото, Серебро или Бронза — отражающих чувствительность к задержке и ожидаемое энергопотребление. Система затем вычисляет новую величину, называемую шкалой риска нарушения SLA (SLA Violation Risk Score, SVRS), которая оценивает вероятность того, что конкретная задача не выполнит своё обещание. Эта оценка зависит от того, насколько близок дедлайн, насколько загружена очередь целевого сервера и как часто похожие задачи терпели неудачу на этом сервере в недавнем прошлом. Задачи с высоким риском выделяются, чтобы планировщик мог обращаться с ними особенно осторожно, вместо того чтобы обнаруживать их срочность уже после просрочки.
Как обучающий планировщик принимает решения
В центре рамочной модели находится агент глубокого обучения с подкреплением, который постоянно наблюдает состояние edge–cloud системы и выбирает, куда отправить каждую задачу. Его представление о системе включает загрузки серверов, сетевые задержки, уровень SLA задачи и SVRS. Лёгкая архитектура нейронной сети обрабатывает как текущий снимок состояния, так и краткосрочную историю системы, затем предлагает возможные действия по размещению — например, отправить задачу на конкретный edge-узел или в центральное облако. Перед принятием решения шаг отсечения действий отбрасывает явно небезопасные варианты, например отправку уязвимой золотой задачи на уже перегруженный узел с высоким риском. Это сужает пространство решений и отворачивает процесс обучения от очевидно плохих ходов, помогая системе быстрее стабилизироваться.
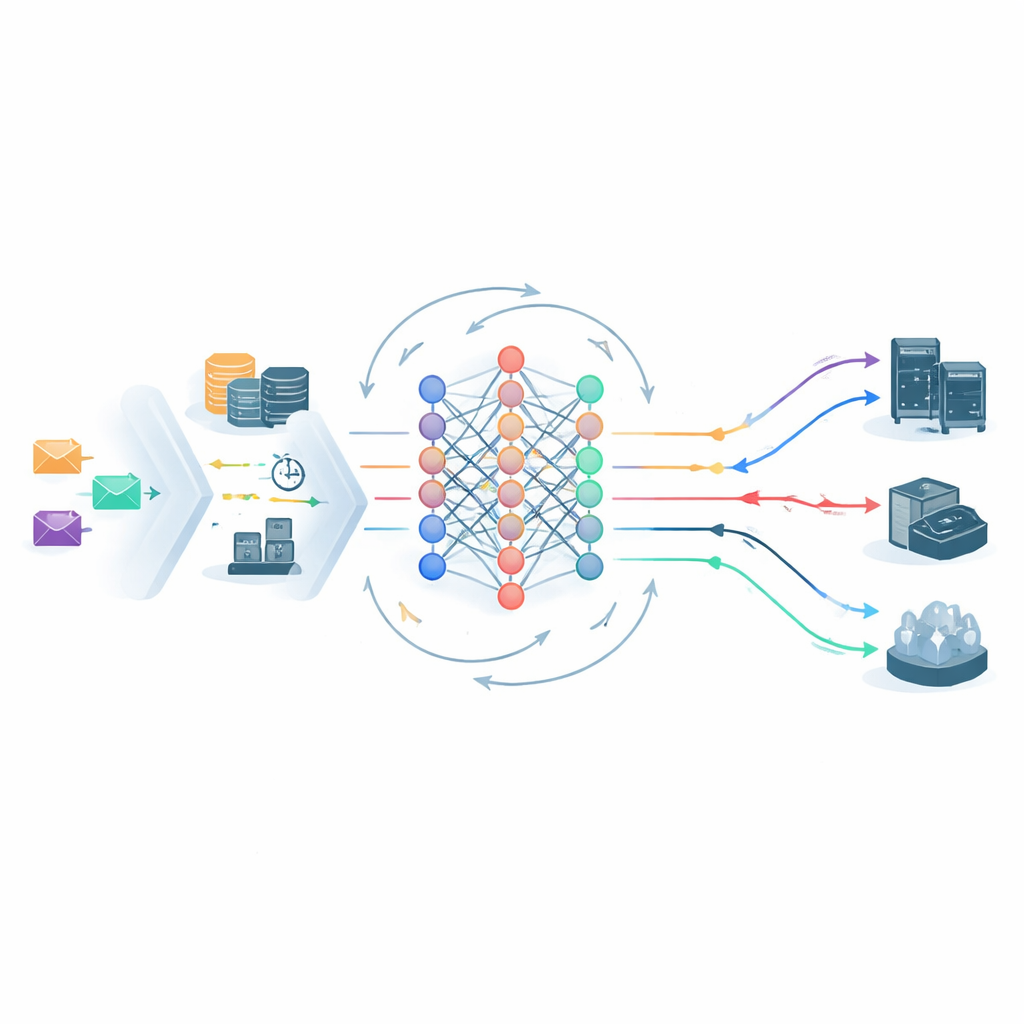
Обучение на собственных ошибках
После планирования задач модуль мониторинга отслеживает, что произошло на практике: закончилась ли каждая задача до дедлайна и соблюдался ли её энергетический бюджет. Любое нарушение фиксируется, и со временем обновляются показатели нарушений по уровням. Эти статистики возвращаются в цикл обучения двумя способами. Во-первых, они корректируют будущие значения SVRS, делая систему более осторожной в отношении серверов или паттернов, которые недавно плохо себя показали. Во-вторых, они перекраивают вознаграждения, которые получает агент обучения: ему начисляются дополнительные баллы за сохранность задач высокого приоритета и он сильнее наказывается, когда такие задачи терпят неудачу. Если уровни нарушений в конкретной категории начинают расти, штраф автоматически увеличивается, подталкивая планировщик изменить поведение без ручной перенастройки.
Что показывают эксперименты на практике
Для проверки идеи авторы создали подробный симулятор смешанного edge–cloud кластера, обрабатывающего десятки тысяч синтетических задач Интернета вещей — от небольших показаний датчиков до тяжёлой обработки видео. Они сравнили их SLA-ориентированный планировщик с классическими базовыми методами, такими как FIFO и Round Robin, энергоориентированным жадным методом и планировщиком на основе глубокого обучения с подкреплением без учёта SLA. Для множества сочетаний нагрузок новый подход сократил нарушения SLA примерно на две трети по сравнению с лучшим базовым методом, уменьшил среднюю задержку примерно на треть и снизил энергопотребление почти на тридцать процентов. Абляционное исследование, в котором ключевые элементы дизайна удаляли по очереди, показало резкое падение эффективности, подтвердив, что оценка риска, отсечение действий и вознаграждения, основанные на обратной связи, играют решающую роль.
Почему это важно для повседневных подключённых устройств
Для неспециалиста главный вывод таков: просто сделать компьютеры быстрее недостаточно; то, как мы решаем, какая задача где и когда выполняется, может сделать или испортить опыт использования подключённых устройств. Научив планировщик понимать обещания, данные пользователям, и предсказывать, какие задачи действительно находятся под угрозой опоздания, эта работа показывает, что системы edge–cloud могут работать более плавно и эффективнее одновременно. В практическом плане это может означать более стабильное видео с уличных камер, более надёжные оповещения от медицинских датчиков и более длительное время работы устройств от батареи — всё это без дополнительного железа, только за счёт использования более умных SLA-ориентированных алгоритмов обучения для управления цифровым трафиком.
Цитирование: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Ключевые слова: планирование в edge cloud, соглашения об уровне сервиса, глубокое обучение с подкреплением, оффлоадинг задач IoT, оптимизация задержки и энергопотребления