Clear Sky Science · de
SLA-bewusstes Deep Reinforcement Learning für adaptive Edge‑Cloud Aufgabenplanung
Warum intelligenter digitaler Verkehr wichtig ist
Von intelligenten Kameras an Straßenecken bis zu Gesundheitssensoren am Handgelenk: Milliarden winziger Geräte senden jetzt kontinuierlich Daten, die irgendwo zwischen unseren Handys, nahegelegenen Edge‑Servern und entfernten Cloud‑Rechenzentren verarbeitet werden müssen. All diese digitalen Aufgaben rechtzeitig und energieeffizient zu erledigen, ist überraschend schwierig. Kommen zu viele Jobs gleichzeitig an, verpassen manche ihre zugesagten Antwortzeiten — die sogenannten Service Level Agreements (SLAs). Dieses Papier untersucht einen neuen Weg, diese konkurrierenden Anforderungen mit einem lernbasierten Scheduler in Echtzeit auszubalancieren, um Verzögerungen und Energieverbrauch zu senken und dabei die Zusagen besser einzuhalten.
Heutige Planungsregeln reichen nicht aus
Die meisten aktuellen Scheduler in Edge–Cloud‑Systemen folgen einfachen Regeln: Anfragen in Eingangsreihenfolge abarbeiten, fair zwischen Servern rotieren oder die nächste Deadline priorisieren. Diese Strategien ignorieren, wie wichtig eine Aufgabe für den Nutzer ist und wie wahrscheinlich es ist, dass sie ihre Zeit‑ oder Energieversprechen bricht. Viele neuere Methoden nutzen Deep Reinforcement Learning — Software, die durch Versuch und Irrtum lernt — um Aufgaben intelligenter zu platzieren. Aber selbst diese behandeln Aufgaben meist gleichwertig und stützen sich auf feste Schwellenwerte statt ständig zu überwachen, wie nahe jede Aufgabe einem echten Problem ist. In der Folge wirken sie im Mittel gut, lassen aber dennoch die kritischsten Jobs durchrutschen.
Aufgaben Dringlichkeit und Risiko geben
Die Autoren schlagen einen Scheduler vor, der jede eingehende Aufgabe durch die Brille ihres Serviceversprechens betrachtet. Jede Aufgabe wird in eine von drei Stufen eingeteilt — Gold, Silber oder Bronze — je nachdem, wie empfindlich sie gegenüber Verzögerungen ist und wieviel Energie sie voraussichtlich verbraucht. Das System berechnet dann eine neue Größe, den SLA Violation Risk Score (SVRS), der abschätzt, wie wahrscheinlich es ist, dass diese konkrete Aufgabe ihr Versprechen verfehlt. Dieser Wert hängt davon ab, wie nahe die Deadline liegt, wie voll die Warteschlange des Zielservers ist und wie oft ähnliche Aufgaben dort in jüngster Vergangenheit gescheitert sind. Hochriskante Aufgaben werden hervorgehoben, sodass der Scheduler ihnen besondere Aufmerksamkeit schenken kann, statt ihre Dringlichkeit erst zu bemerken, wenn sie bereits verspätet sind.
Wie der lernende Scheduler Entscheidungen trifft
Kern des Frameworks ist ein Deep Reinforcement Learning Agent, der kontinuierlich den Zustand des Edge–Cloud‑Systems beobachtet und auswählt, wohin jede Aufgabe geschickt wird. Seine Sicht umfasst Serverauslastungen, Netzwerkverzögerung, die SLA‑Stufe der Aufgabe und den SVRS. Eine leichte neuronale Netzwerkarchitektur verarbeitet sowohl den aktuellen Schnappschuss als auch die kurzfristige Historie des Systems und schlägt mögliche Platzierungsaktionen vor — etwa das Senden einer Aufgabe an einen bestimmten Edge‑Knoten oder an die zentrale Cloud. Bevor eine Entscheidung getroffen wird, sortiert ein Action‑Pruning‑Schritt Optionen aus, die eindeutig unsicher sind, etwa eine fragile Gold‑Aufgabe an einen bereits überlasteten Knoten mit hohem Risiko zu senden. Das verkleinert den Entscheidungsraum und lenkt das Lernen von offensichtlich schlechten Zügen weg, wodurch sich das System schneller stabilisiert.
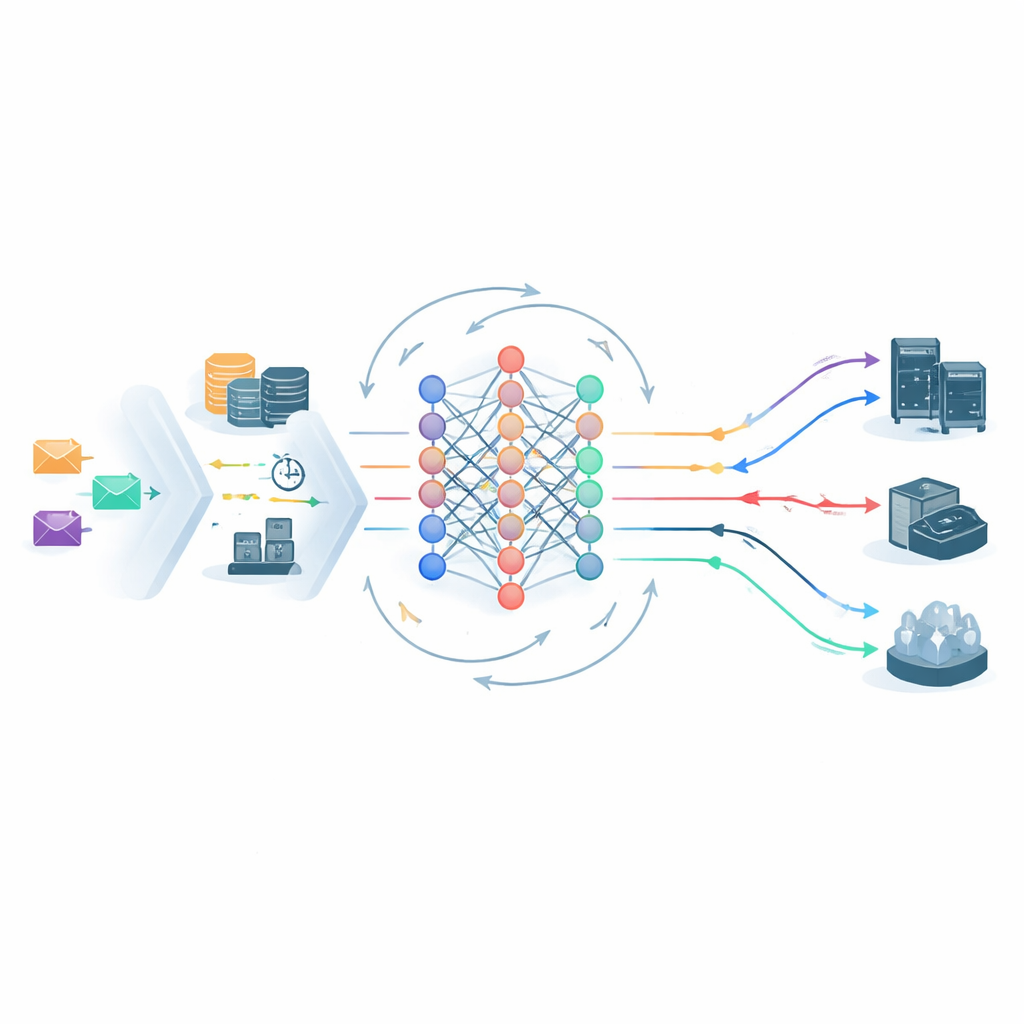
Aus eigenen Fehlern lernen
Sobald Aufgaben geplant sind, verfolgt ein Monitoring‑Modul, was tatsächlich passiert: Wurde jeder Job vor seiner Deadline beendet und wurde sein Energiebudget eingehalten? Jede Verletzung wird protokolliert, und die störungsbezogenen Raten pro Stufe werden im Zeitverlauf aktualisiert. Diese Statistiken fließen auf zweierlei Weise in die Lernschleife zurück. Erstens passen sie künftige SVRS‑Werte an und machen das System vorsichtiger gegenüber Servern oder Mustern, die sich kürzlich schlecht verhalten haben. Zweitens formen sie die Belohnungen, die der Lernagent erhält: Er bekommt zusätzlichen Bonus, wenn er hochprioritäre Aufgaben sichert, und wird stärker bestraft, wenn solche Aufgaben fehlschlagen. Steigen die Verletzungsraten in einer bestimmten Stufe, erhöht sich die Strafe automatisch und veranlasst den Scheduler so zu Verhaltensänderungen ohne manuelles Nachjustieren.
Was die Experimente in der Praxis zeigen
Zur Überprüfung bauten die Autoren einen detaillierten Simulator eines gemischten Edge–Cloud‑Clusters, das zehntausende synthetischer IoT‑Aufgaben verarbeitet, von kleinen Sensormessungen bis zur aufwendigen Videobearbeitung. Sie verglichen ihren SLA‑bewussten Scheduler mit klassischen Baselines wie First‑In‑First‑Out und Round Robin, einer energieorientierten Greedy‑Methode und einem Deep Reinforcement Learning Scheduler ohne SLA‑Informationen. Über viele Arbeitslastmischungen hinweg reduzierte der neue Ansatz SLA‑Verstöße um etwa zwei Drittel gegenüber der besten Baseline, verringerte die durchschnittliche Verzögerung um rund ein Drittel und senkte den Energieverbrauch um nahezu dreißig Prozent. Eine Ablationsstudie, bei der zentrale Bestandteile des Designs nacheinander entfernt wurden, zeigte deutliche Leistungseinbrüche und bestätigte, dass Risikobewertung, Action‑Pruning und Feedback‑basierte Belohnungen jeweils eine entscheidende Rolle spielen.
Warum das für alltägliche vernetzte Geräte wichtig ist
Für Nicht‑Spezialisten ist die wichtigste Erkenntnis: Einfach nur Computer schneller zu machen reicht nicht; wie wir entscheiden, welcher Job wo und wann ausgeführt wird, kann das Nutzungserlebnis vernetzter Geräte maßgeblich beeinflussen. Indem der Scheduler lernt, die an Nutzer gemachten Versprechen zu verstehen und vorherzusagen, welche Aufgaben wirklich in Gefahr sind, zu spät zu kommen, zeigt diese Arbeit, dass Edge–Cloud‑Systeme gleichzeitig flüssiger und effizienter laufen können. Praktisch könnte das flüssigeres Videomaterial von Straßenkameras, zuverlässigere Warnungen von medizinischen Sensoren und längere Batterielaufzeiten für Geräte bedeuten — ganz ohne neue Hardware, allein durch intelligentere, SLA‑bewusste Lernalgorithmen zur Steuerung des digitalen Verkehrs.
Zitation: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Schlüsselwörter: Edge‑Cloud‑Planung, Service Level Agreements, Deep Reinforcement Learning, IoT‑Aufgaben‑Offloading, Latenz‑ und Energieoptimierung