Clear Sky Science · en
SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling
Why smarter digital traffic matters
From smart cameras on street corners to health sensors on our wrists, billions of tiny devices now constantly send data to be processed somewhere between our phones, nearby edge servers, and distant cloud data centers. Getting all of these digital chores done on time, without wasting energy, is surprisingly hard. When too many jobs arrive at once, some miss their promised response times, known as service level agreements, or SLAs. This paper explores a new way to juggle these competing demands using a learning-based scheduler that can adapt in real time, cutting delays and energy use while better keeping those promises.
Today’s scheduling rules fall short
Most current schedulers in edge–cloud systems follow simple rules: handle requests in the order they arrive, rotate fairly among servers, or focus on the nearest deadline. These strategies ignore how important each task is to the user and how likely it is to break its time or energy promise. Many newer methods use deep reinforcement learning—software that learns by trial and error—to place tasks more cleverly. But even these usually treat all tasks as if they were equal and rely on fixed thresholds rather than constantly reading how close each task is to real trouble. As a result, they may look good on average while still letting the most critical jobs slip.
Giving tasks a sense of urgency and risk
The authors propose a scheduler that looks at each incoming task through the lens of its service promise. Every task is placed into one of three tiers—Gold, Silver, or Bronze—reflecting how sensitive it is to delay and how much energy it may consume. The system then computes a new quantity called the SLA Violation Risk Score, or SVRS, which estimates how likely that specific task is to miss its promise. This score depends on how close the deadline is, how crowded the target server’s queue has become, and how often similar tasks have failed there in the recent past. High-risk tasks are highlighted so the scheduler can treat them with extra care instead of discovering their urgency only after they are already late.
How the learning scheduler makes decisions
At the heart of the framework is a deep reinforcement learning agent that continually observes the state of the edge–cloud system and chooses where to send each task. Its view of the world includes server loads, network delay, the task’s SLA tier, and the SVRS. A lightweight neural network architecture processes both the current snapshot and short-term history of the system, then proposes possible placement actions—such as sending a task to a specific edge node or the central cloud. Before any choice is made, an action-pruning step throws out options that are clearly unsafe, for example sending a fragile Gold task to an already overloaded node with high risk. This shrinks the decision space and steers learning away from obviously bad moves, helping the system stabilize more quickly.
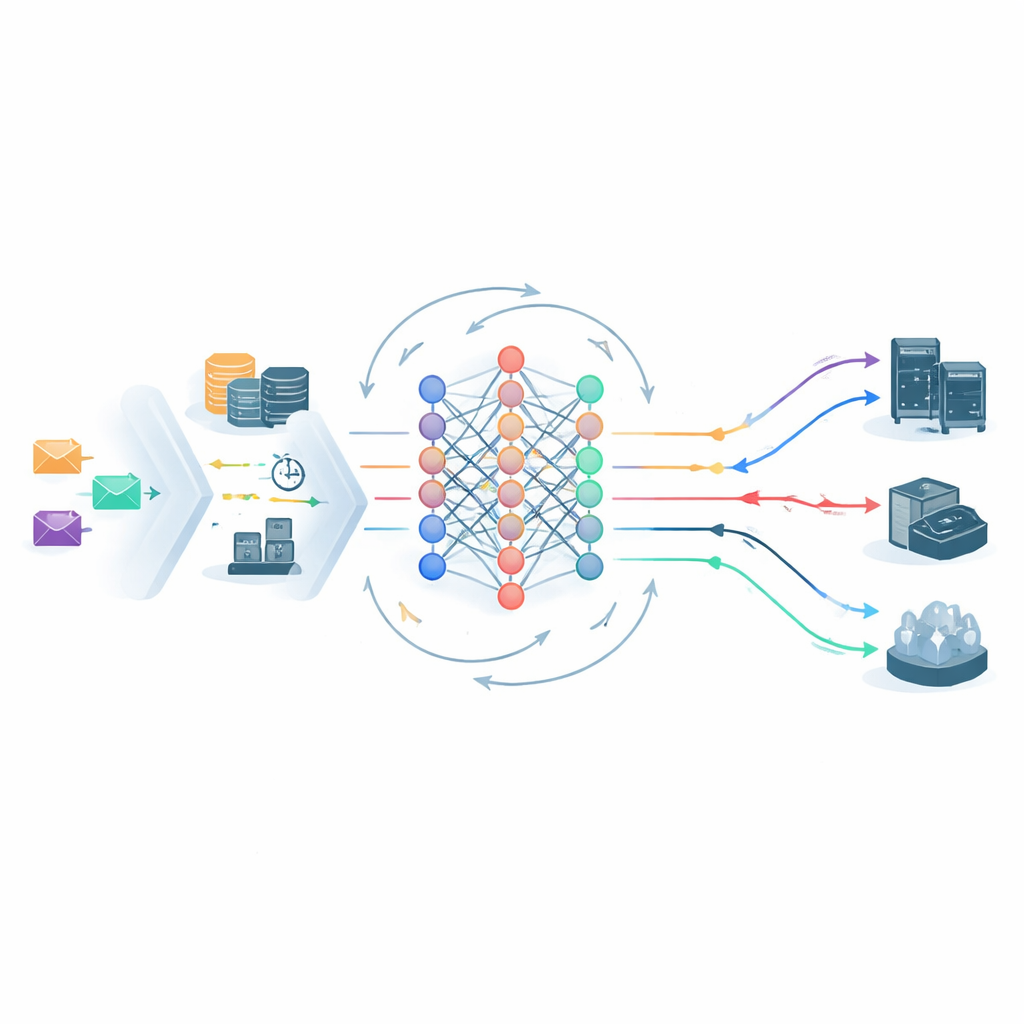
Learning from its own mistakes
Once tasks are scheduled, a monitoring module tracks what actually happens: did each job finish before its deadline, and was its energy budget respected? Any violation is recorded, and tier-specific violation rates are updated over time. These statistics feed back into the learning loop in two ways. First, they adjust future SVRS values, making the system more cautious about servers or patterns that have recently misbehaved. Second, they reshape the rewards that the learning agent receives: it is given extra credit for keeping high-priority tasks safe and penalized more harshly when those tasks fail. If violation rates in a particular tier start to climb, the penalty automatically increases, nudging the scheduler to change its behavior without human retuning.
What the experiments show in practice
To test the idea, the authors built a detailed simulator of a mixed edge–cloud cluster handling tens of thousands of synthetic Internet of Things tasks, from small sensor readings to heavy video processing. They compared their SLA-aware scheduler to classic baselines such as First-In-First-Out and Round Robin, an energy-focused greedy method, and a deep reinforcement learning scheduler that does not use SLA information. Across many workload mixes, the new approach cut SLA violations by about two thirds relative to the best baseline, reduced average delay by roughly one third, and lowered energy use by nearly thirty percent. An ablation study, where key pieces of the design were removed one by one, showed sharp drops in performance, confirming that risk scoring, action pruning, and feedback-based rewards each play a crucial role.
Why this matters for everyday connected devices
For a non-specialist, the main takeaway is that simply making computers faster is not enough; how we decide which job runs where and when can make or break the experience of using connected devices. By teaching the scheduler to understand promises made to users and to predict which tasks are in real danger of being late, this work shows that edge–cloud systems can run more smoothly and more efficiently at the same time. In practical terms, that could mean smoother video from street cameras, more reliable alerts from medical sensors, and longer battery life for devices, all without adding new hardware—just by using smarter, SLA-aware learning algorithms to steer the digital traffic.
Citation: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Keywords: edge cloud scheduling, service level agreements, deep reinforcement learning, IoT task offloading, latency and energy optimization