Clear Sky Science · pl
SLA świadome uczenie głębokie wzmacniające do adaptacyjnego planowania zadań w EdgeCloud
Dlaczego inteligentniejszy ruch cyfrowy ma znaczenie
Od inteligentnych kamer na rogach ulic po czujniki zdrowotne na nadgarstkach — miliardy niewielkich urządzeń stale przesyłają dane do przetworzenia gdzieś między naszymi telefonami, pobliskimi serwerami brzegowymi a odległymi centrami danych w chmurze. Wykonanie wszystkich tych cyfrowych zadań na czas, bez marnowania energii, okazuje się zaskakująco trudne. Gdy zbyt wiele zleceń pojawia się naraz, część nie dotrzymuje obiecanych czasów reakcji, zwanych umowami o poziomie usług (SLA). Artykuł prezentuje nowy sposób godzenia tych konkurujących wymagań, wykorzystując oparty na uczeniu się scheduler, który może adaptować się w czasie rzeczywistym, skracając opóźnienia i zużycie energii, a jednocześnie lepiej dotrzymując tych zobowiązań.
Obowiązujące dziś reguły planowania zawodzą
Większość obecnych schedulerów w systemach edge–cloud stosuje proste reguły: obsługa żądań w kolejności przybycia, rotacja sprawiedliwa między serwerami lub fokus na najbliższy termin. Strategie te ignorują, jak ważne jest każde zadanie dla użytkownika i jak prawdopodobne jest, że złamie swoje zobowiązanie czasowe lub energetyczne. Wiele nowszych metod wykorzystuje głębokie uczenie ze wzmocnieniem — oprogramowanie uczące się metodą prób i błędów — by umieszczać zadania sprytniej. Nawet one jednak zwykle traktują wszystkie zadania jak równorzędne i polegają na stałych progach zamiast ciągle oceniać, jak blisko każde zadanie jest rzeczywistego zagrożenia. W rezultacie mogą wypadać dobrze średnio, a mimo to dopuścić do poślizgu najważniejszych zadań.
Nadanie zadaniom poczucia pilności i ryzyka
Autorzy proponują scheduler, który postrzega każde przychodzące zadanie przez pryzmat jego obietnicy serwisowej. Każde zadanie przypisywane jest do jednej z trzech klas — Gold, Silver lub Bronze — odzwierciedlających wrażliwość na opóźnienia i przewidywane zużycie energii. System oblicza następnie nową wielkość nazwaną Wskaźnikiem Ryzyka Naruszenia SLA (SLA Violation Risk Score, SVRS), który szacuje, jak prawdopodobne jest, że konkretne zadanie nie dotrzyma swojej obietnicy. Wynik zależy od bliskości terminu, stopnia zatłoczenia kolejki docelowego serwera oraz tego, jak często podobne zadania zawodziły tam w niedawnej przeszłości. Zadania o wysokim ryzyku są wyróżniane, aby scheduler mógł potraktować je z dodatkową ostrożnością, zamiast dowiadywać się o ich pilności dopiero wtedy, gdy są już spóźnione.
Jak decyduje uczący się scheduler
W sercu ram działa agent głębokiego uczenia ze wzmocnieniem, który nieustannie obserwuje stan systemu edge–cloud i wybiera, gdzie wysłać każde zadanie. Jego obraz świata obejmuje obciążenia serwerów, opóźnienia sieciowe, klasę SLA zadania oraz SVRS. Lekka architektura sieci neuronowej przetwarza zarówno bieżący stan, jak i krótkoterminową historię systemu, a następnie proponuje możliwe akcje umieszczenia — na przykład wysłanie zadania do konkretnego węzła brzegowego lub do centralnej chmury. Zanim zostanie podjęty wybór, krok przycinania akcji odrzuca opcje ewidentnie niebezpieczne, na przykład wysłanie wrażliwego zadania Gold do już przeciążonego węzła o wysokim ryzyku. To zmniejsza przestrzeń decyzji i kieruje proces uczenia z dala od oczywiście złych ruchów, pomagając systemowi szybciej się ustabilizować.
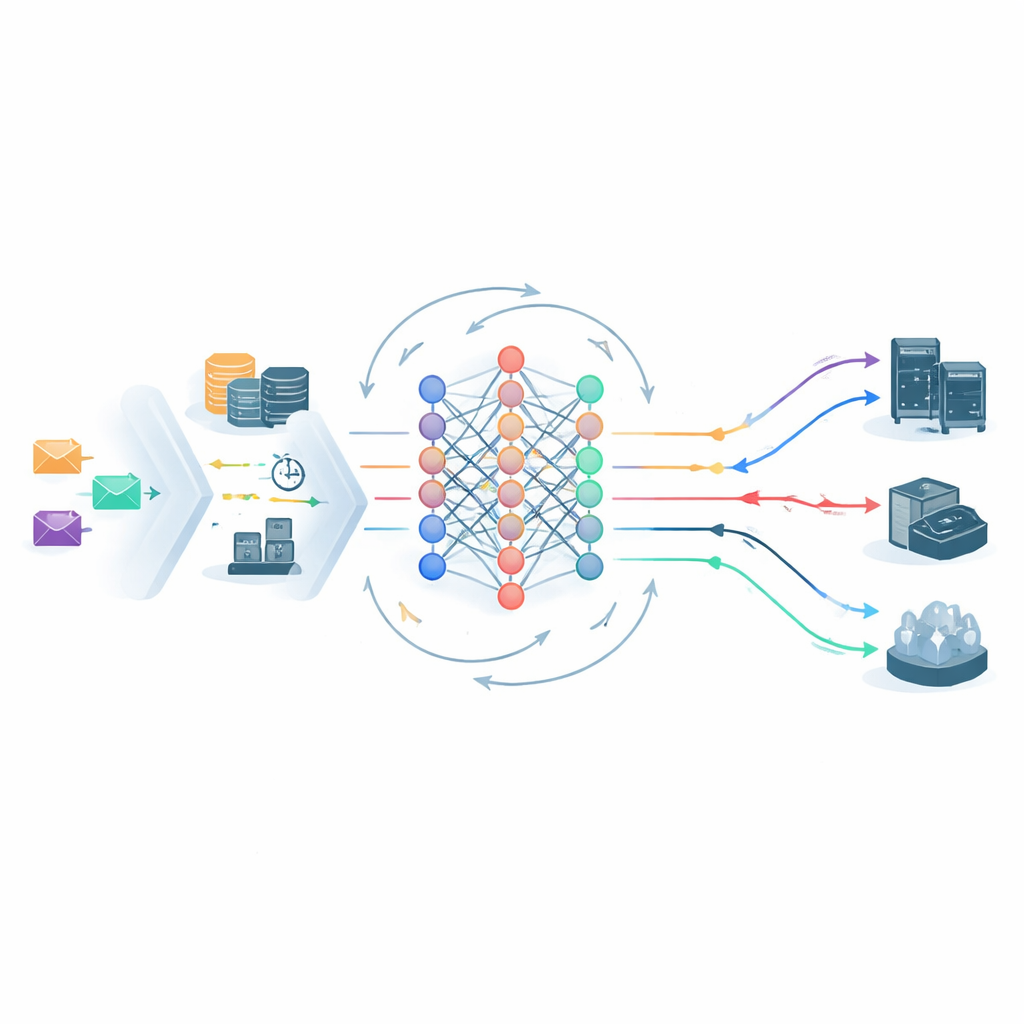
Nauka na własnych błędach
Po zaplanowaniu zadań moduł monitorujący śledzi, co rzeczywiście się wydarzyło: czy każde zadanie zakończyło się przed terminem i czy dotrzymano jego budżetu energetycznego? Każde naruszenie jest rejestrowane, a wskaźniki naruszeń dla poszczególnych klas są aktualizowane w czasie. Te statystyki sprzężone są z pętlą uczenia na dwa sposoby. Po pierwsze, korygują przyszłe wartości SVRS, czyniąc system bardziej ostrożnym wobec serwerów lub wzorców, które ostatnio się nie sprawdzały. Po drugie, przekształcają nagrody przyznawane agentowi uczącemu się: otrzymuje on dodatkowe punkty za zabezpieczanie zadań o wysokim priorytecie i surowsze kary, gdy te zadania zawiodą. Jeśli wskaźniki naruszeń w danej klasie zaczną rosnąć, kara automatycznie się zwiększa, skłaniając scheduler do zmiany zachowania bez potrzeby ręcznego dostrajania.
Co pokazały eksperymenty w praktyce
Aby przetestować pomysł, autorzy zbudowali szczegółowy symulator mieszanej chmury edge–cloud obsługującej dziesiątki tysięcy syntetycznych zadań Internetu Rzeczy, od małych odczytów czujników po ciężkie przetwarzanie wideo. Porównali swój scheduler uwzględniający SLA z klasycznymi metodami bazowymi, takimi jak FIFO i Round Robin, z metodą zachłanną ukierunkowaną na energię oraz z agentem głębokiego uczenia ze wzmocnieniem, który nie używa informacji o SLA. W różnych mieszankach obciążeń nowe podejście zmniejszyło naruszenia SLA o około dwie trzecie względem najlepszego baseline’u, skróciło średnie opóźnienie o około jedną trzecią i obniżyło zużycie energii prawie o trzydzieści procent. Badanie ablacjne, polegające na usunięciu kluczowych elementów projektu po kolei, wykazało ostre spadki wydajności, potwierdzając, że ocena ryzyka, przycinanie akcji i nagrody oparte na sprzężeniu zwrotnym każda odgrywają istotną rolę.
Dlaczego to ma znaczenie dla codziennych urządzeń połączonych w sieć
Dla osoby niebędącej specjalistą główny wniosek jest taki, że samo zwiększenie szybkości komputerów nie wystarcza; sposób, w jaki decydujemy, która praca ma być wykonana gdzie i kiedy, może przesądzić o jakości korzystania z urządzeń połączonych w sieć. Ucząc scheduler rozumienia obietnic składanych użytkownikom i przewidywania, które zadania są rzeczywiście zagrożone opóźnieniem, praca ta pokazuje, że systemy edge–cloud mogą działać jednocześnie płynniej i wydajniej. W praktyce może to oznaczać płynniejszy obraz z kamer ulicznych, bardziej niezawodne powiadomienia z czujników medycznych i dłuższy czas pracy baterii urządzeń — wszystko bez dodawania nowego sprzętu, jedynie dzięki inteligentniejszym algorytmom uczącym się uwzględniającym SLA do kierowania ruchem cyfrowym.
Cytowanie: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Słowa kluczowe: planowanie w edge cloud, umowy o poziomie usług, głębokie uczenie ze wzmocnieniem, przesyłanie zadań IoT, optymalizacja opóźnień i energii