Clear Sky Science · fr
Apprentissage par renforcement profond sensible aux SLA pour l'ordonnancement adaptatif des tâches EdgeCloud
Pourquoi un trafic numérique plus intelligent compte
Des caméras intelligentes aux coins de rue aux capteurs de santé portés au poignet, des milliards de petits appareils envoient désormais en permanence des données à traiter quelque part entre nos téléphones, des serveurs edge proches et des centres de données cloud éloignés. Faire en sorte que toutes ces tâches numériques soient effectuées à temps, sans gaspiller d'énergie, est étonnamment difficile. Lorsque trop de travaux arrivent en même temps, certains manquent leurs temps de réponse promis, appelés accords de niveau de service, ou SLA. Cet article explore une nouvelle façon de jongler avec ces demandes concurrentes en utilisant un ordonnanceur basé sur l'apprentissage capable de s'adapter en temps réel, réduisant les délais et la consommation d'énergie tout en respectant mieux ces promesses.
Les règles d'ordonnancement actuelles sont insuffisantes
La plupart des ordonnanceurs actuels dans les systèmes edge–cloud suivent des règles simples : traiter les requêtes dans l'ordre d'arrivée, tourner équitablement entre les serveurs ou privilégier l'échéance la plus proche. Ces stratégies négligent l'importance de chaque tâche pour l'utilisateur et la probabilité qu'elle viole sa contrainte de temps ou d'énergie. De nombreuses méthodes récentes utilisent l'apprentissage par renforcement profond — un logiciel qui apprend par essais et erreurs — pour placer les tâches plus intelligemment. Mais même celles-ci traitent généralement toutes les tâches comme si elles étaient égales et reposent sur des seuils fixes plutôt que de mesurer en continu à quel point chaque tâche est proche du danger. En conséquence, elles peuvent donner de bons résultats en moyenne tout en laissant échapper les tâches les plus critiques.
Donner aux tâches un sens de l'urgence et du risque
Les auteurs proposent un ordonnanceur qui évalue chaque tâche entrante à travers le prisme de sa promesse de service. Chaque tâche est placée dans l'un des trois niveaux — Or, Argent ou Bronze — reflétant sa sensibilité au délai et sa consommation énergétique potentielle. Le système calcule ensuite une nouvelle quantité appelée Score de Risque de Violation du SLA, ou SVRS, qui estime la probabilité que cette tâche manque sa promesse. Ce score dépend de la proximité de l'échéance, de l'état d'encombrement de la file du serveur cible et de la fréquence des échecs de tâches similaires sur ce serveur récemment. Les tâches à haut risque sont mises en évidence afin que l'ordonnanceur puisse leur accorder une attention particulière au lieu de découvrir leur urgence uniquement lorsqu'elles sont déjà en retard.
Comment l'ordonnanceur apprenant prend ses décisions
Au cœur du cadre se trouve un agent d'apprentissage par renforcement profond qui observe en continu l'état du système edge–cloud et choisit où envoyer chaque tâche. Sa vision inclut les charges des serveurs, la latence réseau, le niveau SLA de la tâche et le SVRS. Une architecture de réseau neuronal légère traite à la fois l'instantané courant et l'historique à court terme du système, puis propose des actions de placement possibles — par exemple envoyer une tâche vers un nœud edge spécifique ou vers le cloud central. Avant toute décision, une étape d'élagage des actions supprime les options manifestement dangereuses, par exemple envoyer une tâche Or fragile vers un nœud déjà surchargé et à haut risque. Cela réduit l'espace de décision et oriente l'apprentissage loin des choix clairement mauvais, aidant le système à se stabiliser plus rapidement.
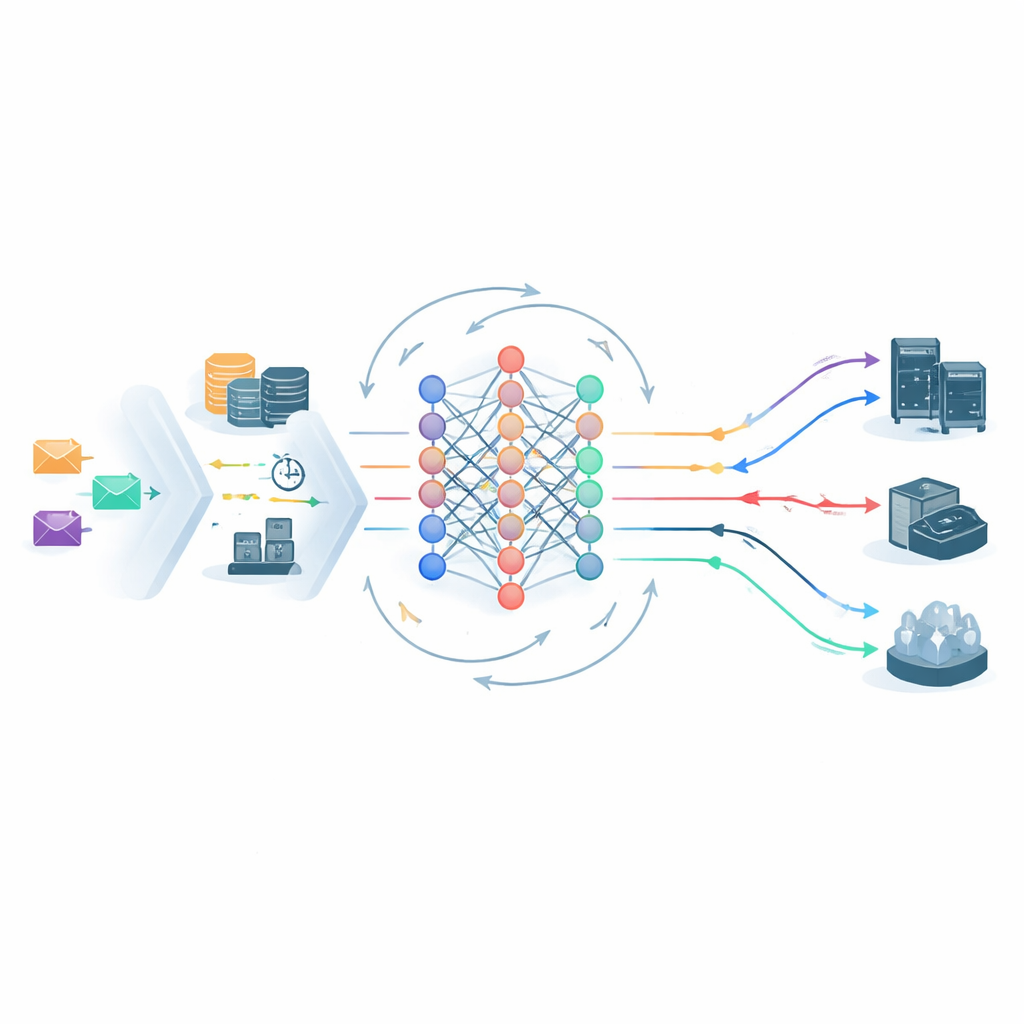
Apprendre de ses propres erreurs
Une fois les tâches ordonnancées, un module de surveillance suit ce qui se passe réellement : chaque tâche a‑t‑elle été terminée avant son échéance, et son budget énergétique a‑t‑il été respecté ? Toute violation est enregistrée, et les taux de violation par niveau sont mis à jour au fil du temps. Ces statistiques alimentent la boucle d'apprentissage de deux façons. Premièrement, elles ajustent les valeurs futures du SVRS, rendant le système plus prudent vis‑à‑vis des serveurs ou des schémas qui ont récemment mal fonctionné. Deuxièmement, elles remodèlent les récompenses reçues par l'agent d'apprentissage : il reçoit un bonus pour la protection des tâches haute priorité et est pénalisé plus sévèrement lorsque ces tâches échouent. Si les taux de violation d'un niveau particulier commencent à augmenter, la pénalité augmente automatiquement, incitant l'ordonnanceur à changer de comportement sans réajustement humain.
Ce que montrent les expériences en pratique
Pour tester l'idée, les auteurs ont construit un simulateur détaillé d'un cluster mixte edge–cloud traitant des dizaines de milliers de tâches synthétiques d'Internet des objets, allant de petites lectures de capteurs à des traitements vidéo lourds. Ils ont comparé leur ordonnanceur sensible aux SLA à des baselines classiques comme Premier Entré–Premier Sorti et Round Robin, une méthode gourmande axée sur l'énergie, et un ordonnanceur par apprentissage profond qui n'utilise pas l'information SLA. Sur de nombreux mélanges de charge, la nouvelle approche a réduit les violations de SLA d'environ deux tiers par rapport au meilleur baseline, réduit le délai moyen d'environ un tiers et diminué la consommation d'énergie de près de trente pour cent. Une étude d'ablation, où des éléments clés du design ont été retirés un par un, a montré des baisses nettes de performance, confirmant que le scorage du risque, l'élagage d'actions et les récompenses basées sur le retour jouent chacun un rôle crucial.
Pourquoi cela compte pour les objets connectés du quotidien
Pour un non‑spécialiste, la principale conclusion est que simplement rendre les ordinateurs plus rapides ne suffit pas ; la façon dont nous décidons quelle tâche s'exécute où et quand peut faire ou défaire l'expérience des utilisateurs d'appareils connectés. En apprenant à l'ordonnanceur à comprendre les promesses faites aux utilisateurs et à prédire quelles tâches risquent réellement d'être en retard, ce travail montre que les systèmes edge–cloud peuvent fonctionner plus fluidement et plus efficacement en même temps. En termes pratiques, cela pourrait signifier des vidéos plus fluides provenant des caméras de rue, des alertes médicales plus fiables et une durée de batterie plus longue pour les appareils, le tout sans ajouter de nouveau matériel — simplement en utilisant des algorithmes d'apprentissage plus intelligents et sensibles aux SLA pour orienter le trafic numérique.
Citation: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Mots-clés: ordonnancement edge cloud, accords de niveau de service, apprentissage par renforcement profond, déchargement de tâches IoT, optimisation latence et énergie