Clear Sky Science · pt
Aprendizado profundo por reforço consciente de SLA para escalonamento adaptativo de tarefas EdgeCloud
Por que o tráfego digital mais inteligente importa
De câmeras inteligentes em esquinas a sensores de saúde em nossos pulsos, bilhões de pequenos dispositivos agora enviam dados constantemente para serem processados em algum ponto entre nossos telefones, servidores de borda próximos e centros de dados em nuvem distantes. Concluir todas essas tarefas digitais dentro do prazo, sem desperdiçar energia, é surpreendentemente difícil. Quando muitos trabalhos chegam ao mesmo tempo, alguns perdem os tempos de resposta prometidos, conhecidos como acordos de nível de serviço, ou SLAs. Este artigo explora uma nova maneira de equilibrar essas demandas concorrentes usando um escalonador baseado em aprendizado que pode se adaptar em tempo real, reduzindo atrasos e consumo de energia enquanto cumpre melhor essas promessas.
As regras de escalonamento atuais ficam aquém
A maioria dos escalonadores atuais em sistemas edge–cloud segue regras simples: tratar solicitações na ordem de chegada, rotacionar de forma justa entre servidores ou focar no prazo mais próximo. Essas estratégias ignoram o quão importante cada tarefa é para o usuário e a probabilidade de ela violar seu tempo ou promessa de energia. Muitos métodos mais recentes usam aprendizado profundo por reforço — software que aprende por tentativa e erro — para alocar tarefas de forma mais inteligente. Mas mesmo esses geralmente tratam todas as tarefas como se fossem iguais e dependem de limiares fixos em vez de ler constantemente quão perto cada tarefa está de um problema real. Como resultado, podem parecer bons em média, mas ainda deixar escapar os trabalhos mais críticos.
Dar às tarefas um senso de urgência e risco
Os autores propõem um escalonador que observa cada tarefa que chega através da lente de sua promessa de serviço. Toda tarefa é colocada em um de três níveis — Ouro, Prata ou Bronze — refletindo quão sensível ela é ao atraso e quanta energia pode consumir. O sistema então calcula uma nova quantidade chamada Pontuação de Risco de Violação de SLA, ou SVRS, que estima a probabilidade de aquela tarefa específica não cumprir sua promessa. Essa pontuação depende de quão próximo está o prazo, de quão cheia a fila do servidor alvo se tornou e de quão frequentemente tarefas semelhantes falharam lá recentemente. Tarefas de alto risco são destacadas para que o escalonador possa tratá-las com cuidado extra em vez de descobrir sua urgência somente depois que já estão atrasadas.
Como o escalonador de aprendizado toma decisões
No coração do framework está um agente de aprendizado profundo por reforço que observa continuamente o estado do sistema edge–cloud e escolhe para onde enviar cada tarefa. Sua visão do mundo inclui cargas dos servidores, latência da rede, o nível de SLA da tarefa e a SVRS. Uma arquitetura de rede neural leve processa tanto o instantâneo atual quanto o histórico de curto prazo do sistema, e então propõe possíveis ações de alocação — como enviar uma tarefa para um nó de borda específico ou para a nuvem central. Antes de qualquer escolha, uma etapa de poda de ações elimina opções claramente inseguras, por exemplo enviar uma tarefa sensível de nível Ouro para um nó já sobrecarregado e com alto risco. Isso reduz o espaço de decisão e afasta o aprendizado de movimentos obviamente ruins, ajudando o sistema a se estabilizar mais rapidamente.
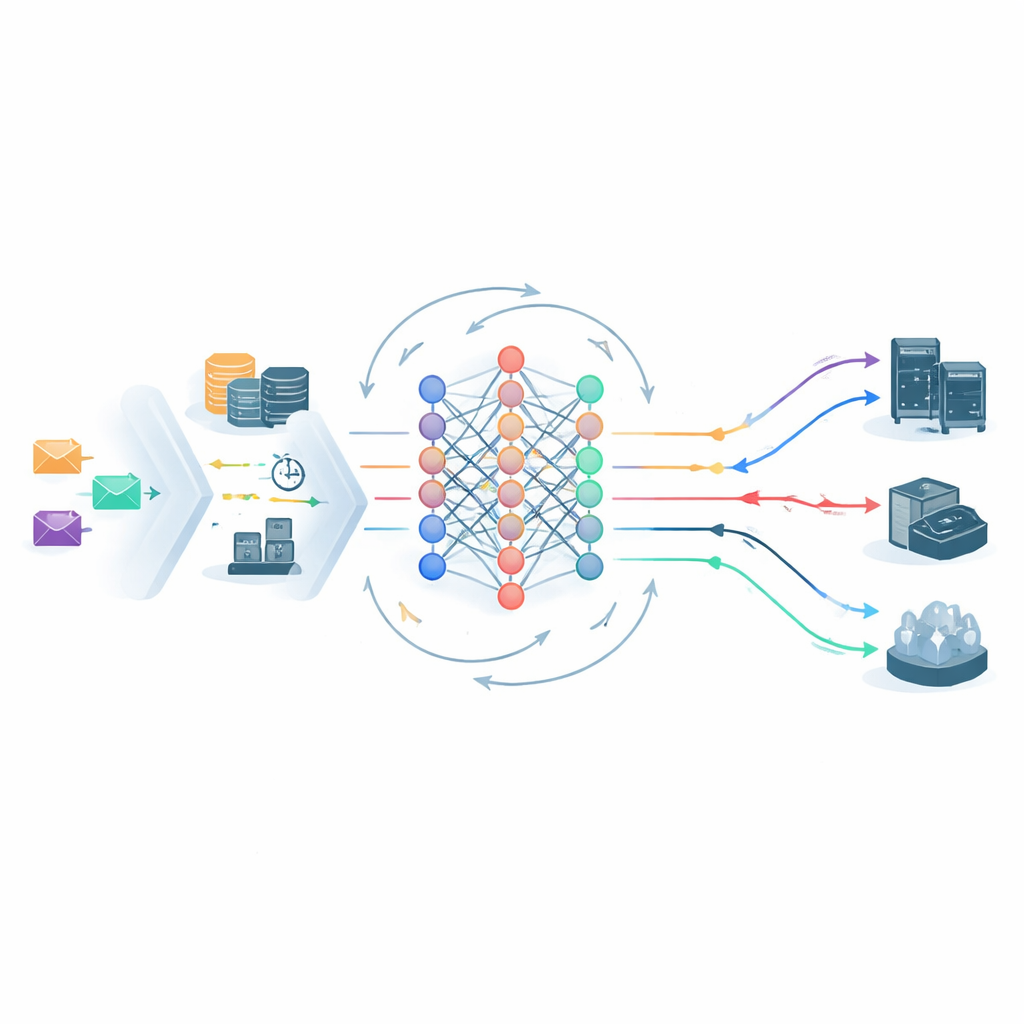
Aprendendo com seus próprios erros
Depois que as tarefas são escalonadas, um módulo de monitoramento rastreia o que realmente acontece: cada trabalho terminou antes do prazo e respeitou seu orçamento de energia? Qualquer violação é registrada, e as taxas de violação específicas por nível são atualizadas ao longo do tempo. Essas estatísticas retroalimentam o ciclo de aprendizado de duas maneiras. Primeiro, ajustam os valores futuros da SVRS, tornando o sistema mais cauteloso em relação a servidores ou padrões que se comportaram mal recentemente. Segundo, remodelam as recompensas que o agente de aprendizado recebe: ele ganha crédito extra por manter seguras as tarefas de alta prioridade e é penalizado com mais rigor quando essas tarefas falham. Se as taxas de violação em um nível particular começarem a subir, a penalidade aumenta automaticamente, empurrando o escalonador a mudar seu comportamento sem necessidade de retreinamento humano.
O que os experimentos mostram na prática
Para testar a ideia, os autores construíram um simulador detalhado de um cluster misto edge–cloud lidando com dezenas de milhares de tarefas sintéticas de Internet das Coisas, desde pequenas leituras de sensores até pesado processamento de vídeo. Eles compararam seu escalonador consciente de SLA com bases clássicas como Primeiro a Entrar, Primeiro a Sair e Round Robin, um método ganancioso focado em energia e um escalonador de aprendizado profundo por reforço que não usa informação de SLA. Em muitos perfis de carga, a nova abordagem reduziu as violações de SLA em cerca de dois terços em relação à melhor baseline, diminuiu o atraso médio em aproximadamente um terço e reduziu o consumo de energia em quase trinta por cento. Um estudo de ablação, no qual peças-chave do projeto foram removidas uma a uma, mostrou quedas acentuadas no desempenho, confirmando que a pontuação de risco, a poda de ações e as recompensas baseadas em feedback desempenham cada uma um papel crucial.
Por que isso importa para dispositivos conectados do dia a dia
Para um leitor não especialista, a lição principal é que simplesmente tornar os computadores mais rápidos não basta; como decidimos qual trabalho roda onde e quando pode fazer ou quebrar a experiência de usar dispositivos conectados. Ao ensinar o escalonador a entender as promessas feitas aos usuários e a prever quais tarefas estão realmente em risco de atraso, este trabalho mostra que sistemas edge–cloud podem funcionar de forma mais suave e eficiente ao mesmo tempo. Em termos práticos, isso pode significar vídeo mais fluido de câmeras de rua, alertas mais confiáveis de sensores médicos e maior vida útil da bateria dos dispositivos, tudo sem adicionar novo hardware — apenas usando algoritmos de aprendizado mais inteligentes e conscientes de SLA para direcionar o tráfego digital.
Citação: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Palavras-chave: escalonamento edge cloud, acordos de nível de serviço, aprendizado profundo por reforço, deslocamento de tarefas IoT, otimização de latência e energia