Clear Sky Science · nl
SLA-bewuste deep reinforcement learning voor adaptieve EdgeCloud-taakplanning
Waarom slimmer digitaal verkeer ertoe doet
Van slimme camera’s op straathoeken tot gezondheidssensoren om onze polsen: miljarden kleine apparaten sturen continu data om te worden verwerkt ergens tussen onze telefoons, nabijgelegen edge-servers en verre cloud-datacenters. Al die digitale taken op tijd afronden zonder energie te verspillen is verrassend lastig. Als er te veel taken tegelijk binnenkomen, halen sommige hun beloofde reactietijd niet, de zogenaamde service level agreements (SLA’s). Dit artikel onderzoekt een nieuwe manier om deze concurrerende eisen te verdelen met een op leren gebaseerde scheduler die zich in realtime kan aanpassen, waardoor vertragingen en energieverbruik afnemen en beloften beter worden nagekomen.
Huidige planningsregels schieten tekort
De meeste huidige schedulers in edge–cloudsystemen volgen eenvoudige regels: verwerk aanvragen in de volgorde van binnenkomst, roteer eerlijk tussen servers of focus op de dichtstbijzijnde deadline. Deze strategieën negeren hoe belangrijk elke taak voor de gebruiker is en hoe waarschijnlijk het is dat ze hun tijds- of energiebelofte schenden. Veel nieuwere methoden gebruiken deep reinforcement learning — software die leert door proef en fout — om taken slimmer te plaatsen. Maar zelfs deze behandelen meestal alle taken alsof ze gelijk zijn en vertrouwen op vaste drempels in plaats van voortdurend te lezen hoe dicht elke taak bij echte problemen zit. Daardoor kunnen ze gemiddeld goed lijken terwijl de meest kritieke taken toch door de mazen glippen.
Taken urgentie en risico geven
De auteurs stellen een scheduler voor die elke binnenkomende taak bekijkt door de bril van zijn servicebelofte. Elke taak wordt in een van drie niveaus geplaatst — Gold, Silver of Bronze — die aangeven hoe gevoelig de taak is voor vertraging en hoeveel energie ze kan verbruiken. Het systeem berekent vervolgens een nieuwe grootheid: de SLA Violation Risk Score, of SVRS, die inschat hoe waarschijnlijk het is dat die specifieke taak zijn belofte niet waarmaakt. Deze score hangt af van hoe dicht de deadline is, hoe druk de wachtrij van de doelserver is geworden en hoe vaak vergelijkbare taken daar recent zijn mislukt. Taken met hoog risico worden uitgelicht zodat de scheduler ze met extra zorg kan behandelen in plaats van hun urgentie pas te ontdekken als ze al te laat zijn.
Hoe de leer-scheduler beslissingen neemt
In het hart van het kader staat een deep reinforcement learning-agent die continu de toestand van het edge–cloudsysteem observeert en kiest waar iedere taak naartoe te sturen. Zijn wereldbeeld omvat serverbelastingen, netwerkvertraging, het SLA-niveau van de taak en de SVRS. Een lichte neurale netwerkarchitectuur verwerkt zowel de huidige momentopname als de korte-termijngeschiedenis van het systeem en stelt vervolgens mogelijke plaatsingsacties voor — zoals het sturen van een taak naar een specifiek edge-knooppunt of de centrale cloud. Voordat een keuze wordt gemaakt, gooit een actie-pruningstap opties weg die duidelijk onveilig zijn, bijvoorbeeld het sturen van een kwetsbare Gold-taak naar een al overbelast knooppunt met hoog risico. Dit verkleint de beslissingsruimte en stuurt het leerproces weg van voor de hand liggend slechte zetten, waardoor het systeem sneller stabiliseert.
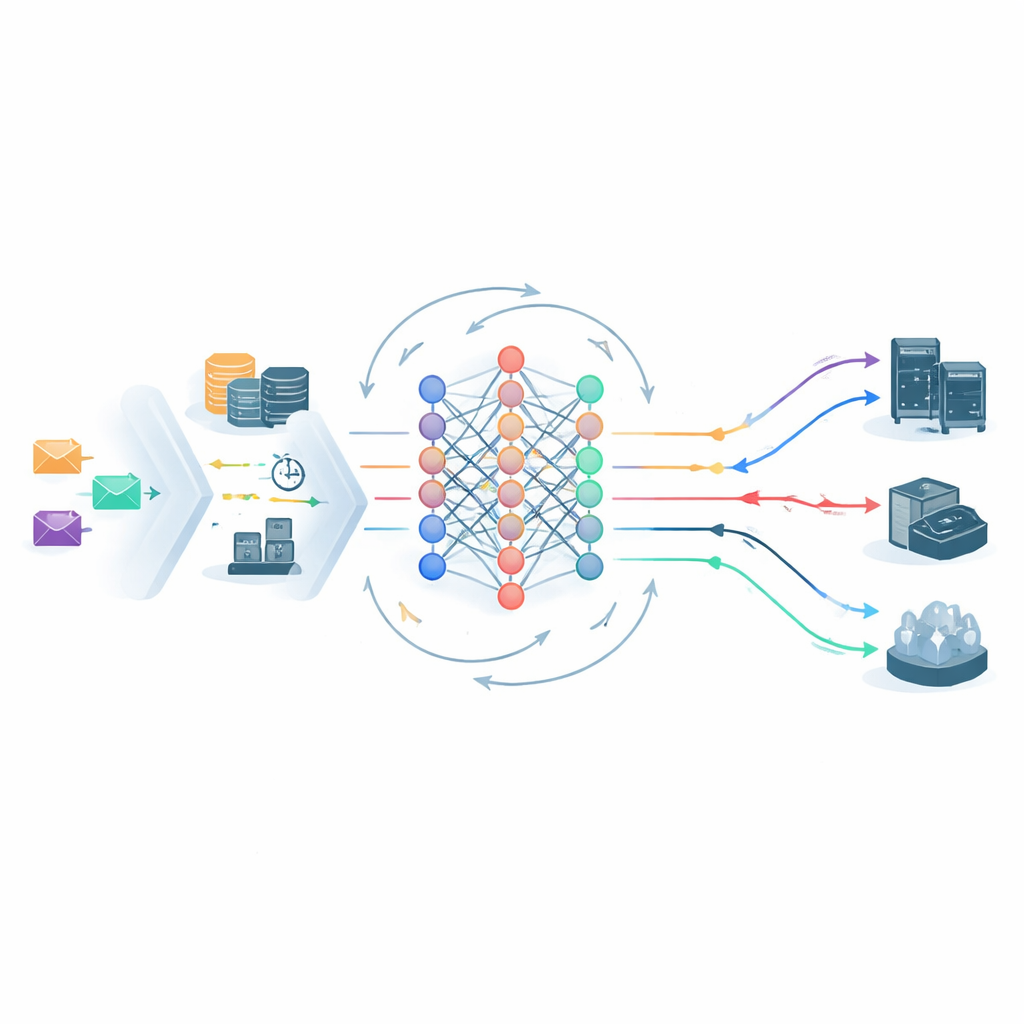
Leren van eigen fouten
Nadat taken gepland zijn, volgt een monitoringsmodule wat er daadwerkelijk gebeurt: is elke taak vóór de deadline voltooid en is het energiebudget gerespecteerd? Elke schending wordt vastgelegd en de schendingpercentages per niveau worden in de tijd bijgewerkt. Deze statistieken voeden de leerlus op twee manieren. Ten eerste passen ze toekomstige SVRS-waarden aan, waardoor het systeem voorzichtiger wordt ten opzichte van servers of patronen die recent slecht hebben gepresteerd. Ten tweede vormen ze de beloningen voor de leeragent: die krijgt extra krediet voor het veilig houden van taken met hoge prioriteit en wordt zwaarder gestraft wanneer die taken falen. Als de schendingspercentages in een bepaald niveau beginnen te stijgen, verhoogt de straf automatisch, wat de scheduler ertoe aanzet zijn gedrag aan te passen zonder handmatige bijstelling.
Wat de experimenten in de praktijk laten zien
Om het idee te testen bouwden de auteurs een gedetailleerde simulator van een gemengde edge–cloudcluster die tienduizenden synthetische Internet of Things-taken verwerkt, van kleine sensormetingen tot zware videobewerking. Ze vergeleken hun SLA-bewuste scheduler met klassieke basismethoden zoals First-In-First-Out en Round Robin, een energiegerichte gretige methode en een deep reinforcement learning-scheduler die geen SLA-informatie gebruikt. Over veel workload-mixen verminderde de nieuwe aanpak SLA-schendingen met ongeveer twee derde ten opzichte van de beste baseline, verlaagde de gemiddelde vertraging met ongeveer een derde en verminderde het energieverbruik met bijna dertig procent. Een ablatiestudie, waarin sleutelonderdelen van het ontwerp één voor één werden verwijderd, liet scherpe prestatieverminderingen zien en bevestigde dat risicoscoring, actie-pruning en feedbackgebaseerde beloningen elk een cruciale rol spelen.
Waarom dit ertoe doet voor alledaagse verbonden apparaten
Voor de niet-specialist is de belangrijkste conclusie dat het simpelweg sneller maken van computers niet genoeg is; hoe we beslissen welke taak waar en wanneer draait kan het gebruik van verbonden apparaten maken of breken. Door de scheduler te leren de aan gebruikers gegeven beloften te begrijpen en te voorspellen welke taken echt gevaar lopen te laat te komen, toont dit werk aan dat edge–cloudsystemen zowel soepeler als efficiënter kunnen draaien. In de praktijk kan dat betekenen: vloeiender beeldmateriaal van straatcamera’s, betrouwbaardere meldingen van medische sensoren en langere batterijduur voor apparaten — alles zonder nieuwe hardware toe te voegen, maar door slimmer, SLA-bewust leren te gebruiken om het digitale verkeer te sturen.
Bronvermelding: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Trefwoorden: edge cloud scheduling, service level agreements, deep reinforcement learning, IoT task offloading, latency and energy optimization