Clear Sky Science · es
Aprendizaje profundo por refuerzo consciente de SLA para la programación adaptativa de tareas en EdgeCloud
Por qué importa gestionar mejor el tráfico digital
Desde cámaras inteligentes en las esquinas hasta sensores de salud en nuestras muñecas, miles de millones de pequeños dispositivos envían datos constantemente para procesarse en algún punto entre nuestros teléfonos, servidores edge cercanos y centros de datos en la nube. Cumplir con todas estas tareas digitales a tiempo, sin desperdiciar energía, es sorprendentemente difícil. Cuando llegan demasiados trabajos a la vez, algunos incumplen los tiempos de respuesta prometidos, conocidos como acuerdos de nivel de servicio o SLA. Este artículo explora una nueva forma de equilibrar estas demandas competitivas usando un planificador basado en aprendizaje que puede adaptarse en tiempo real, reduciendo retrasos y consumo energético a la vez que cumple mejor esas promesas.
Las reglas de programación actuales se quedan cortas
La mayoría de los planificadores actuales en sistemas edge–cloud siguen reglas simples: atender las solicitudes en orden de llegada, rotar de forma justa entre servidores o centrarse en la fecha límite más cercana. Estas estrategias ignoran la importancia que tiene cada tarea para el usuario y la probabilidad de que incumpla su promesa temporal o energética. Muchos métodos más nuevos usan aprendizaje profundo por refuerzo—software que aprende por ensayo y error—para colocar tareas de forma más inteligente. Pero incluso estos suelen tratar todas las tareas como si fueran iguales y dependen de umbrales fijos en lugar de leer constantemente cuán cerca está cada tarea de un problema real. Como resultado, pueden rendir bien de media pero aun así dejar que los trabajos más críticos fallen.
Dar a las tareas un sentido de urgencia y riesgo
Los autores proponen un planificador que examina cada tarea entrante desde la perspectiva de su promesa de servicio. Cada tarea se coloca en uno de tres niveles—Oro, Plata o Bronce—que reflejan su sensibilidad al retraso y cuánto puede consumir de energía. El sistema calcula entonces una nueva cantidad llamada Puntuación de Riesgo de Violación de SLA, o SVRS, que estima la probabilidad de que una tarea concreta incumpla su promesa. Esta puntuación depende de lo cerca que esté la fecha límite, de lo congestionada que esté la cola del servidor objetivo y de la frecuencia con la que tareas similares han fallado allí en el pasado reciente. Las tareas de alto riesgo se resaltan para que el planificador pueda tratarlas con especial cuidado, en lugar de descubrir su urgencia solo después de que ya lleguen tarde.
Cómo el planificador que aprende toma decisiones
En el corazón del marco hay un agente de aprendizaje profundo por refuerzo que observa continuamente el estado del sistema edge–cloud y elige dónde enviar cada tarea. Su visión del mundo incluye cargas de los servidores, latencia de red, el nivel SLA de la tarea y la SVRS. Una arquitectura de red neuronal ligera procesa tanto la instantánea actual como el historial a corto plazo del sistema y luego propone posibles acciones de colocación—como enviar una tarea a un nodo edge específico o a la nube central. Antes de tomar cualquier decisión, un paso de poda de acciones descarta opciones que son claramente inseguras, por ejemplo enviar una tarea Oro frágil a un nodo ya sobrecargado y de alto riesgo. Esto reduce el espacio de decisión y orienta el aprendizaje lejos de movimientos evidentemente malos, ayudando al sistema a estabilizarse más rápido.
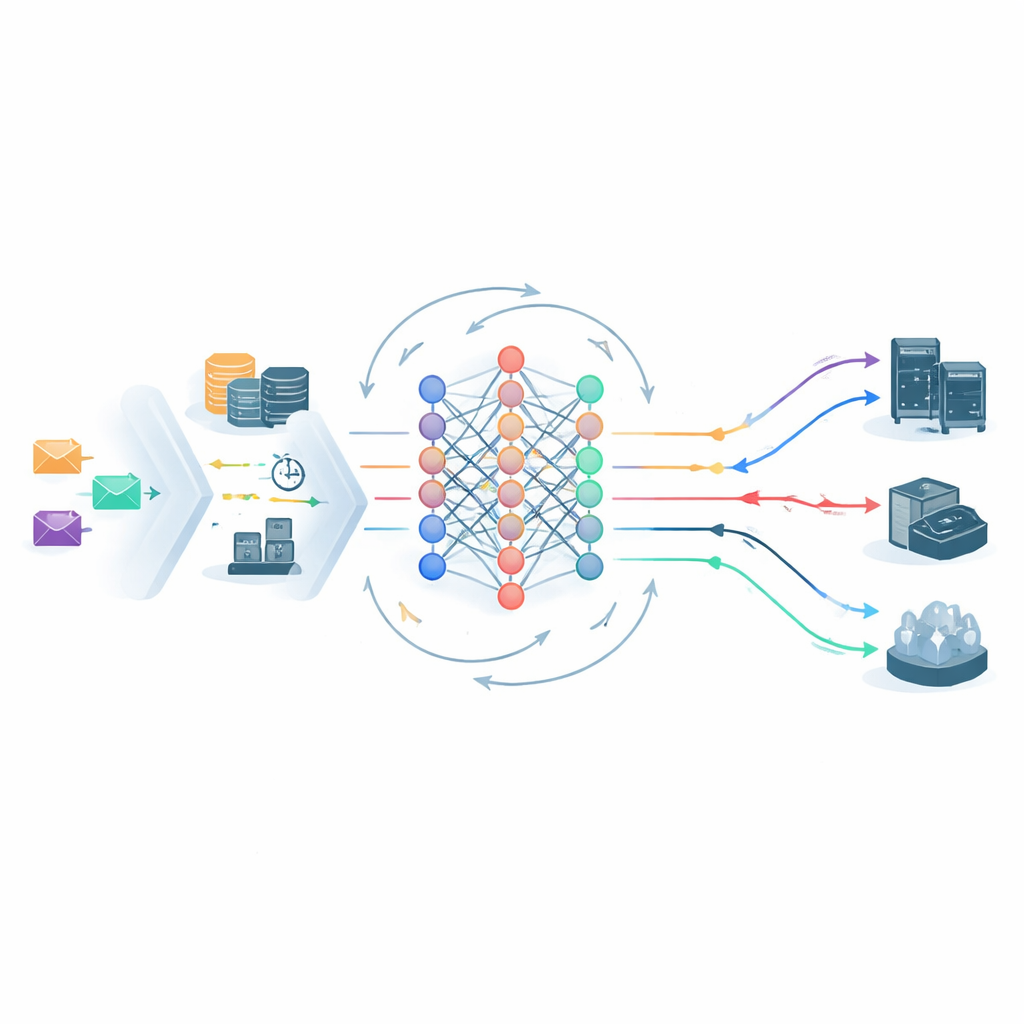
Aprender de sus propios errores
Una vez que se programan las tareas, un módulo de monitorización sigue lo que ocurre en la práctica: ¿terminó cada trabajo antes de su fecha límite y se respetó su presupuesto energético? Cualquier violación se registra y las tasas de incumplimiento por nivel se actualizan con el tiempo. Estas estadísticas retroalimentan el bucle de aprendizaje de dos maneras. Primero, ajustan los valores futuros de la SVRS, haciendo que el sistema sea más cauteloso respecto a servidores o patrones que han fallado recientemente. Segundo, remodelan las recompensas que recibe el agente de aprendizaje: obtiene crédito extra por mantener seguras las tareas de alta prioridad y es penalizado más severamente cuando esas tareas fallan. Si las tasas de incumplimiento en un nivel particular empiezan a subir, la penalización aumenta automáticamente, empujando al planificador a cambiar su comportamiento sin necesidad de reajustes manuales.
Qué muestran los experimentos en la práctica
Para probar la idea, los autores construyeron un simulador detallado de un clúster mixto edge–cloud que maneja decenas de miles de tareas sintéticas de Internet de las Cosas, desde pequeñas lecturas de sensores hasta procesamiento de vídeo intensivo. Compararon su planificador consciente de SLA con baselines clásicos como Primero en Entrar Primero en Salir y Round Robin, un método codicioso enfocado en la energía y un planificador por aprendizaje profundo por refuerzo que no utiliza información de SLA. En una amplia variedad de mezclas de carga, el nuevo enfoque redujo las violaciones de SLA en aproximadamente dos tercios respecto al mejor baseline, disminuyó la latencia media en torno a un tercio y redujo el consumo energético casi un treinta por ciento. Un estudio de ablación, en el que se eliminaron piezas clave del diseño una por una, mostró caídas pronunciadas en el rendimiento, confirmando que la puntuación de riesgo, la poda de acciones y las recompensas basadas en retroalimentación juegan cada una un papel crucial.
Por qué esto importa para los dispositivos conectados cotidianos
Para un público no especialista, la conclusión principal es que simplemente hacer las computadoras más rápidas no basta; la forma en que decidimos qué trabajo se ejecuta dónde y cuándo puede hacer o deshacer la experiencia de usar dispositivos conectados. Al enseñar al planificador a entender las promesas hechas a los usuarios y a predecir qué tareas corren un riesgo real de llegar tarde, este trabajo demuestra que los sistemas edge–cloud pueden funcionar de manera más fluida y eficiente a la vez. En términos prácticos, eso podría significar vídeo más fluido de cámaras de calle, alertas más fiables de sensores médicos y mayor duración de la batería de los dispositivos, todo sin añadir nuevo hardware—simplemente mediante algoritmos de aprendizaje más inteligentes y conscientes de los SLA para dirigir el tráfico digital.
Cita: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Palabras clave: planificación en edge cloud, acuerdos de nivel de servicio, aprendizaje profundo por refuerzo, desvío de tareas IoT, optimización de latencia y energía