Clear Sky Science · it
Apprendimento profondo sensibile agli SLA per il scheduling adattivo di task EdgeCloud
Perché il traffico digitale più intelligente conta
Dalle telecamere intelligenti agli angoli delle strade ai sensori di salute ai nostri polsi, miliardi di piccoli dispositivi inviano continuamente dati da elaborare da qualche parte tra i nostri telefoni, server edge vicini e data center cloud remoti. Completare tutti questi compiti digitali in tempo, senza sprecare energia, è sorprendentemente difficile. Quando troppi lavori arrivano contemporaneamente, alcuni non rispettano i tempi di risposta promessi, noti come accordi sul livello di servizio, o SLA. Questo articolo esplora un nuovo modo di gestire queste richieste in competizione utilizzando uno scheduler basato sull'apprendimento che può adattarsi in tempo reale, riducendo ritardi e consumo energetico mantenendo meglio quelle promesse.
Le regole di scheduling attuali non bastano
La maggior parte degli scheduler odierni nei sistemi edge–cloud segue regole semplici: gestire le richieste nell'ordine di arrivo, ruotare equamente tra i server, o concentrarsi sulla scadenza più vicina. Queste strategie ignorano quanto ogni task sia importante per l'utente e quanto sia probabile che violi il suo vincolo temporale o energetico. Molti metodi più recenti usano il deep reinforcement learning — software che impara per tentativi ed errori — per collocare i task in modo più intelligente. Ma anche questi solitamente trattano tutti i task come se fossero uguali e si affidano a soglie fisse anziché misurare continuamente quanto ogni task sia vicino a un reale pericolo. Di conseguenza, possono sembrare efficaci in media pur lasciando scivolare via i lavori più critici.
Attribuire urgenza e rischio ai task
Gli autori propongono uno scheduler che valuta ogni task in ingresso dalla prospettiva della promessa di servizio. Ogni task è collocato in uno dei tre livelli — Gold, Silver o Bronze — che riflettono la sua sensibilità al ritardo e il consumo energetico previsto. Il sistema calcola quindi una nuova quantità chiamata SLA Violation Risk Score, o SVRS, che stima la probabilità che quel task specifico non rispetti la promessa. Questo punteggio dipende da quanto è vicina la scadenza, da quanto la coda del server di destinazione è affollata e da quante volte task simili hanno fallito lì nel passato recente. I task ad alto rischio sono evidenziati in modo che lo scheduler possa trattarli con cura extra invece di scoprirne l'urgenza solo dopo che sono già in ritardo.
Come lo scheduler basato sull'apprendimento prende decisioni
Al centro del framework c'è un agente di deep reinforcement learning che osserva continuamente lo stato del sistema edge–cloud e sceglie dove inviare ogni task. La sua visione include i carichi dei server, la latenza di rete, il livello SLA del task e lo SVRS. Un'architettura di rete neurale leggera elabora sia l'istantanea corrente sia una breve storia recente del sistema, quindi propone possibili azioni di collocamento — ad esempio inviare un task a un nodo edge specifico o al cloud centrale. Prima che venga presa qualsiasi decisione, un passaggio di potatura delle azioni scarta le opzioni chiaramente non sicure, per esempio inviare un task Gold fragile a un nodo già sovraccarico e ad alto rischio. Questo restringe lo spazio delle decisioni e indirizza l'apprendimento lontano da mosse evidentemente sbagliate, aiutando il sistema a stabilizzarsi più rapidamente.
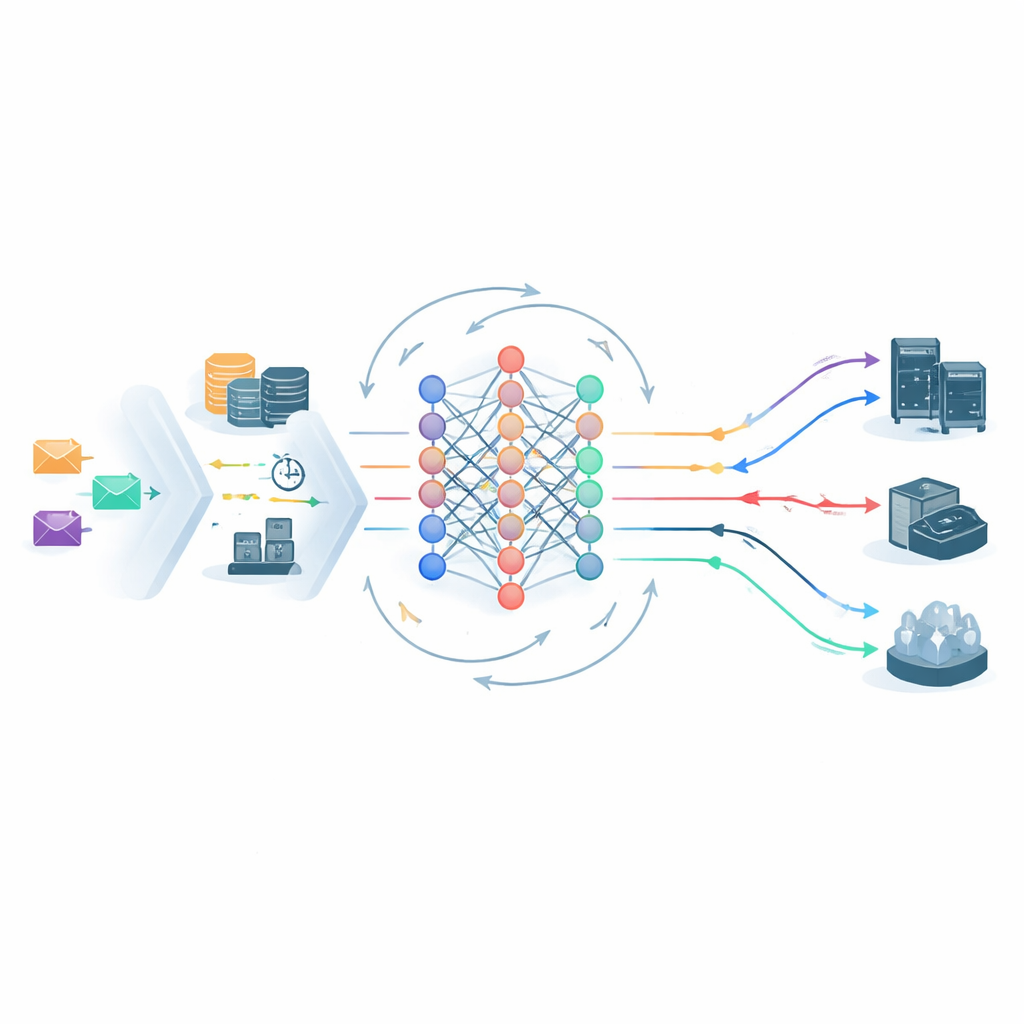
Imparare dai propri errori
Una volta che i task sono schedulati, un modulo di monitoraggio traccia ciò che accade davvero: ogni lavoro è terminato prima della scadenza e il suo budget energetico è stato rispettato? Qualsiasi violazione viene registrata e i tassi di violazione specifici per livello vengono aggiornati nel tempo. Queste statistiche rientrano nel ciclo di apprendimento in due modi. Primo, aggiustano i valori futuri di SVRS, rendendo il sistema più cauto riguardo a server o pattern che si sono comportati male di recente. Secondo, rimodellano le ricompense che l'agente di apprendimento riceve: ottiene credito extra per mantenere al sicuro i task ad alta priorità ed è penalizzato più severamente quando questi falliscono. Se i tassi di violazione in un particolare livello iniziano a salire, la penalità aumenta automaticamente, spingendo lo scheduler a modificare il suo comportamento senza rituning umano.
Cosa mostrano gli esperimenti nella pratica
Per testare l'idea, gli autori hanno costruito un simulatore dettagliato di un cluster misto edge–cloud che gestisce decine di migliaia di task sintetici Internet of Things, da piccole letture di sensori a pesanti elaborazioni video. Hanno confrontato il loro scheduler sensibile agli SLA con baseline classiche come First-In-First-Out e Round Robin, un metodo greedy focalizzato sull'energia e uno scheduler deep reinforcement learning che non usa informazioni sugli SLA. Su molte combinazioni di carico, il nuovo approccio ha ridotto le violazioni degli SLA di circa due terzi rispetto alla migliore baseline, ridotto il ritardo medio di circa un terzo e diminuito il consumo energetico di quasi il trenta percento. Uno studio di ablazione, in cui i componenti chiave del progetto sono stati rimossi uno per uno, ha mostrato nette cadute di prestazioni, confermando che la valutazione del rischio, la potatura delle azioni e le ricompense basate sul feedback giocano ciascuna un ruolo cruciale.
Perché questo è importante per i dispositivi connessi di tutti i giorni
Per un pubblico non specialista, la conclusione principale è che non basta semplicemente rendere i computer più veloci; il modo in cui decidiamo quale lavoro eseguire dove e quando può fare la differenza nell'esperienza d'uso dei dispositivi connessi. Insegnando allo scheduler a comprendere le promesse fatte agli utenti e a prevedere quali task sono davvero in pericolo di ritardo, questo lavoro mostra che i sistemi edge–cloud possono funzionare in modo più fluido ed efficiente allo stesso tempo. In termini pratici, ciò potrebbe significare video più fluidi dalle telecamere di strada, avvisi più affidabili dai sensori medici e una maggiore durata della batteria dei dispositivi, il tutto senza aggiungere nuovo hardware — semplicemente usando algoritmi di apprendimento più intelligenti e sensibili agli SLA per dirigere il traffico digitale.
Citazione: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
Parole chiave: scheduling edge cloud, accordi sul livello di servizio, apprendimento profondo per rinforzo, offload di task IoT, ottimizzazione di latenza ed energia