Clear Sky Science · ar
تعلم التعزيز العميق الواعي باتفاقيات الخدمة لجدولة المهام التكيفية في الحافة والسحابة
لماذا تهم حركة البيانات الرقمية الأذكى
من الكاميرات الذكية على زوايا الشوارع إلى حسّاسات الصحة على معاصمنا، ترسل الآن مليارات الأجهزة الصغيرة بيانات باستمرار ليتم معالجتها في مكان ما بين هواتفنا وخوادم الحافة القريبة ومراكز البيانات السحابية البعيدة. إن إنجاز كل هذه المهام الرقمية في الوقت المناسب، دون إهدار الطاقة، أمر أصعب مما يبدو. عندما تصل العديد من الوظائف دفعة واحدة، يفشل بعضها في تحقيق أوقات الاستجابة الموعودة، والمعروفة باتفاقيات مستوى الخدمة أو SLAs. تستكشف هذه الورقة طريقة جديدة لإدارة هذا التنافس بين المتطلبات باستخدام مجدول يعتمد على التعلم يمكنه التكيف في الزمن الحقيقي، ما يقلل التأخيرات واستهلاك الطاقة وفي الوقت نفسه يحافظ على تلك الوعود بشكل أفضل.
لماذا القواعد الحالية للجدولة تقصر
يتبع معظم المجدولات الحالية في أنظمة الحافة–السحابة قواعد بسيطة: معالجة الطلبات بترتيب وصولها، التناوب العادل بين الخوادم، أو التركيز على أقرب مهلة زمنية. تتجاهل هذه الاستراتيجيات مدى أهمية كل مهمة للمستخدم واحتمال أن تفشل في الوفاء بوعد الزمن أو الطاقة. تستخدم العديد من الأساليب الأحدث التعلم المعزز العميق—برمجيات تتعلم بالتجربة والخطأ—لوضع المهام بذكاء أكبر. لكن حتى هذه الطرق عادة ما تعامل جميع المهام على أنها متساوية وتعتمد على عتبات ثابتة بدلاً من قراءة دائمة لمدى اقتراب كل مهمة من الوقوع في مشكلة حقيقية. نتيجة لذلك، قد تبدو النتائج جيدة بالمعدل العام بينما تسمح للمهام الأكثر حساسية بالتعثر.
منح المهام إحساسًا بالعجلة والمخاطرة
يقترح المؤلفون مجدولًا ينظر إلى كل مهمة واردة من منظور وعد الخدمة الخاص بها. تُصنَّف كل مهمة في أحد المستويات الثلاثة—ذهبي، فضي، أو برونزي—مما يعكس مدى حساسيتها للتأخير وكمية الطاقة التي قد تستهلكها. ثم يُحسب مقدار جديد يسمى درجة مخاطر انتهاك اتفاقية الخدمة (SLA Violation Risk Score, SVRS)، والذي يقدّر احتمال أن تفشل هذه المهمة المحددة في الوفاء بوعدها. تعتمد هذه الدرجة على قرب الموعد النهائي، وازدحام طابور الخادم المستهدف، ومدى تكرار فشل مهام مماثلة هناك في الماضي القريب. تُسلط المهام عالية المخاطر الضوء عليها حتى يعاملها المجدول بعناية إضافية بدلاً من اكتشاف ضرورتها بعد فوات الأوان.
كيف يتخذ مجدول التعلم قراراته
في قلب الإطار وُكِّل وكيل تعلم معمق معزز يراقب باستمرار حالة نظام الحافة–السحابة ويختار إلى أين يرسل كل مهمة. تتضمن رؤيته للعالم أحمال الخوادم، تأخير الشبكة، فئة اتفاقية الخدمة للمهمة، ودرجة SVRS. تعالج بنية شبكية عصبية خفيفة الوزن كل من لقطة الحالة الحالية والتاريخ قصير الأمد للنظام، ثم تقترح إجراءات وضع محتملة—مثل إرسال مهمة إلى عقدة حافة محددة أو إلى السحابة المركزية. قبل اتخاذ أي خيار، تطرح خطوة تقليص الإجراءات الخيارات الواضحة غير الآمنة، على سبيل المثال إرسال مهمة ذهبية حساسة إلى عقدة مثقلة بالفعل ذات مخاطر عالية. هذا يقلص فضاء القرار ويوجه التعلم بعيدًا عن التحركات السيئة الواضحة، مما يساعد النظام على الاستقرار أسرع.
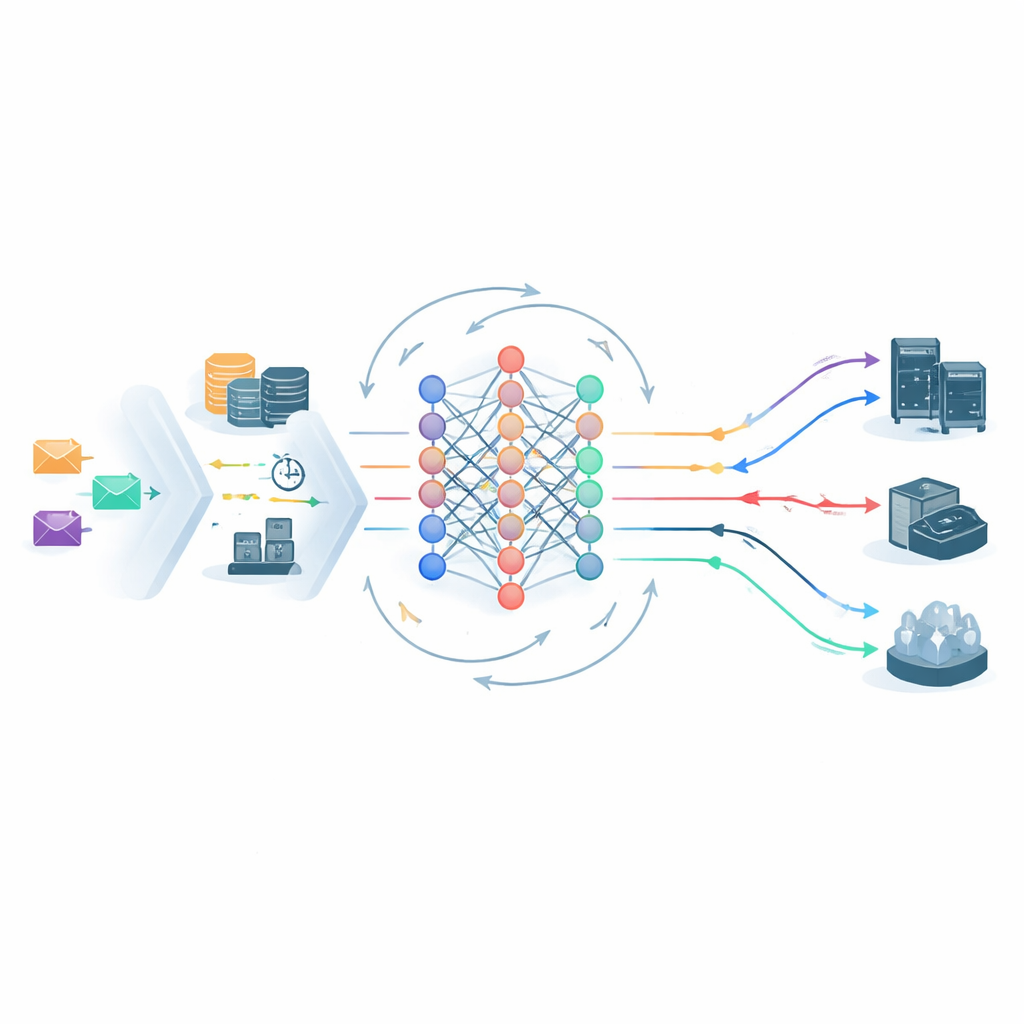
التعلم من أخطائه
بعد جدولة المهام، يتتبع وحد مراقبة ما يحدث فعليًا: هل أنهى كل عمل قبل الموعد النهائي، وهل احترم ميزانية الطاقة الخاصة به؟ يُسجل أي انتهاك، وتُحدَّث معدلات الانتهاك الخاصة بكل مستوى مع مرور الوقت. تغذي هذه الإحصاءات حلقة التعلم بطريقتين. أولاً، تعدل قيم SVRS المستقبلية، مما يجعل النظام أكثر حذرًا تجاه خوادم أو أنماط أخفقت مؤخرًا. ثانيًا، تعيد تشكيل المكافآت التي يتلقاها وكيل التعلم: يُمنح ائتمانًا إضافيًا للحفاظ على سلامة المهام ذات الأولوية العالية ويُعاقب بقوة أكبر عندما تفشل تلك المهام. إذا بدأت معدلات الانتهاك في مستوى معين في الارتفاع، تزداد العقوبة تلقائيًا، مما يدفع المجدول إلى تغيير سلوكه دون إعادة ضبط بشرية.
ماذا أظهرت التجارب عمليًا
لاختبار الفكرة، بنى المؤلفون محاكيًا مفصلًا لعنقود مختلط من الحافة–السحابة يتعامل مع عشرات الآلاف من مهام إنترنت الأشياء الاصطناعية، من قراءات حسّاسات صغيرة إلى معالجة فيديو ثقيلة. قارنوا مجدولهم الواعي باتفاقية الخدمة مع قواعد أساسية كلاسيكية مثل من يأتي أولاً يُخدم أولاً (FIFO) والتناوب الدائري (Round Robin)، وطريقة طماعة تركز على الطاقة، ومجدول تعلم معزز عميق لا يستخدم معلومات SLA. عبر العديد من خلطات الأحمال، خفّض النهج الجديد انتهاكات اتفاقية الخدمة بنحو ثلثي نسبةً إلى أفضل قاعدة مقارنة، وقلّص التأخير المتوسط بنحو ثلث، وخفّض استهلاك الطاقة بنحو ثلاثين بالمئة. أظهرت دراسة إزالة المكونات (ablation)، حيث حُذفت أجزاء رئيسية من التصميم واحدًا تلو الآخر، انخفاضات حادة في الأداء، مؤكدة أن تسجيل المخاطر، وتقليص الإجراءات، والمكافآت القائمة على التغذية الراجعة كل منها يلعب دورًا حاسمًا.
لماذا يهم ذلك لأجهزة متصلة في الحياة اليومية
بالنسبة لغير المتخصص، الخلاصة الأساسية أن جعل الحواسيب أسرع وحده لا يكفي؛ فطريقة اتخاذنا قرار أي مهمة تعمل أين ومتى يمكن أن تصنع فارقًا في تجربة استخدام الأجهزة المتصلة أو تكسرها. من خلال تعليم المجدول فهم الوعود المقدمة للمستخدمين والتنبؤ بأي المهام في خطر حقيقي من التأخير، يبيّن هذا العمل أن أنظمة الحافة–السحابة يمكن أن تعمل بسلاسة وكفاءة أكبر في آنٍ واحد. عمليًا، قد يعني ذلك فيديو أكثر سلاسة من كاميرات الشوارع، وتنبيهات أكثر موثوقية من حسّاسات طبية، وعمر بطارية أطول للأجهزة، وكل ذلك دون إضافة أجهزة جديدة—بل باستخدام خوارزميات تعلم أذكى وواعية باتفاقيات الخدمة لتوجيه حركة البيانات الرقمية.
الاستشهاد: Yamsani, N., P, C.R. SLA aware deep reinforcement learning for adaptive EdgeCloud task scheduling. Sci Rep 16, 10037 (2026). https://doi.org/10.1038/s41598-026-40237-8
الكلمات المفتاحية: جدولة الحافة والسحابة, اتفاقيات مستوى الخدمة, التعلم المعزز العميق, إرسال مهام إنترنت الأشياء, تحسين الكمون والطاقة