Clear Sky Science · pt
Uma abordagem aprimorada para detecção de retinopatia diabética usando técnica de deep learning otimizada
Por que identificar danos oculares cedo importa
O diabetes pode danificar silenciosamente os pequenos vasos sanguíneos na parte de trás do olho, eventualmente levando a visão turva ou até cegueira. Oftalmologistas podem detectar essa condição — chamada retinopatia diabética — examinando fotografias detalhadas da retina. Mas com milhões de pessoas em risco e especialistas em número insuficiente, muitos pacientes nunca são triados a tempo. Este estudo explora como um sistema de inteligência artificial cuidadosamente projetado pode ler fotos da retina com mais precisão e confiabilidade, ajudando a detectar problemas cedo o suficiente para salvar a visão.
Imagens do olho como uma mina de ouro de dados
Fotografias da retina, conhecidas como imagens de fundo de olho (fundus), são muito mais que simples instantâneos. Elas capturam como a luz é absorvida, refletida e dispersa pelas camadas do olho, revelando vasos sanguíneos, pequenos vazamentos e cicatrizes. Esses padrões estão repletos de pistas sobre danos diabéticos, mas também são complexos: as imagens variam em brilho, foco, tipo de câmera e contexto do paciente. Programas anteriores ou dependiam de medidas manuais, que perdem alterações sutis, ou de redes de deep learning que podem ser poderosas, mas propensas a overfitting, especialmente quando a qualidade das imagens ou o ambiente clínico diferem. O desafio é construir um sistema automatizado que aprenda a partir desses dados bagunçados e de alta dimensionalidade sem se tornar frágil ou imprevisível.
Ensinando uma rede neural a ver sinais de alerta chave
Os autores usam primeiro um modelo moderno de deep learning, EfficientNet‑B0, para atuar como um “extrator de características” altamente treinado para cada imagem retiniana. Em vez de pedir que médicos marquem manualmente cada hemorragia ou depósito gorduroso, a rede aprende padrões visuais abstratos que aparecem de forma consistente em olhos doentes versus saudáveis. Para tornar o sistema mais robusto, todas as imagens são limpas e padronizadas: redimensionadas, convertidas para escala de cinza para focar na estrutura em vez da cor, e aprimoradas para realçar pequenos pontos e detalhes dos vasos. As imagens em escala de cinza são então convertidas para um formato que a rede pré‑treinada consegue processar, e as camadas finais da rede são levemente fine‑tuned para que seus filtros internos respondam fortemente às estruturas retinianas em vez de a objetos do dia a dia.
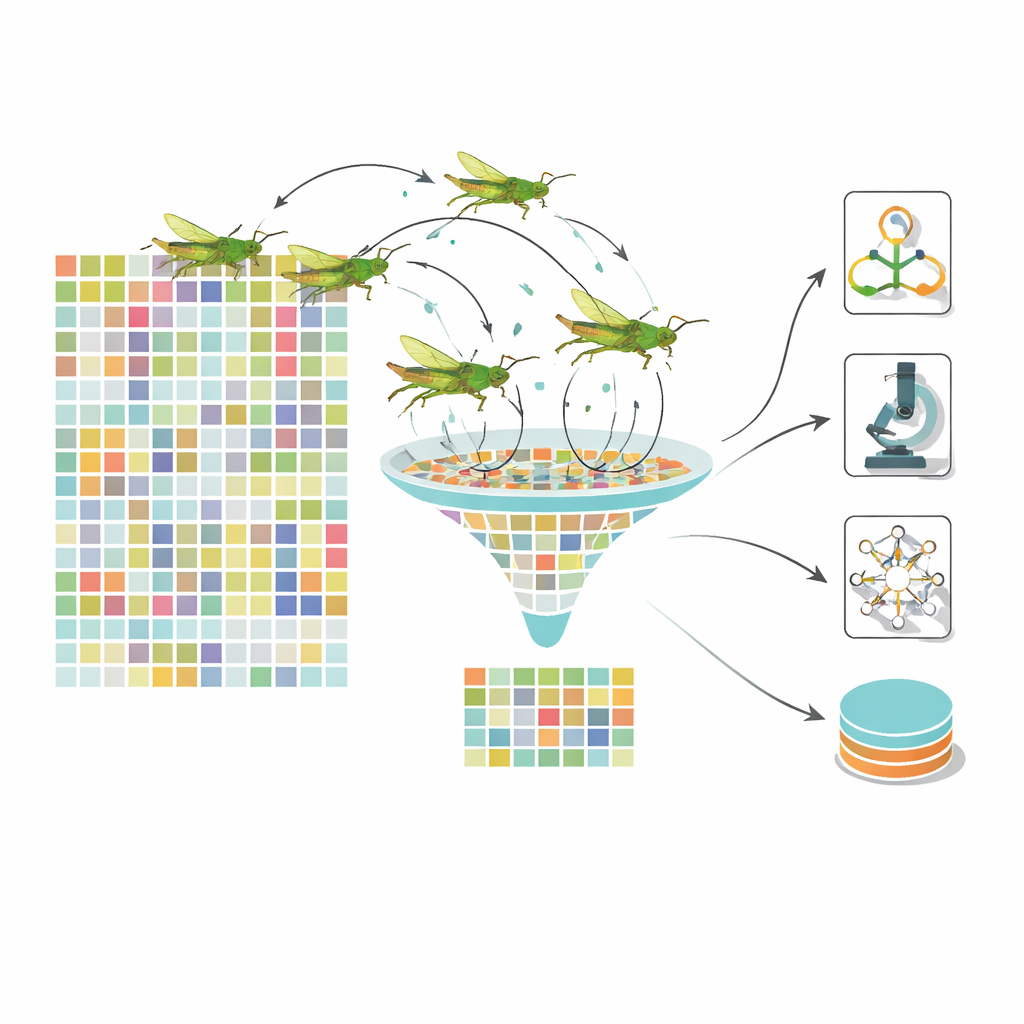
Deixando um enxame virtual escolher as pistas mais reveladoras
Mesmo após o deep learning, cada imagem é representada por mais de mil características numéricas, muitas delas redundantes. Alimentar todas essas características em um classificador torna o aprendizado mais lento e pode diluir a distinção entre estágios da doença. Para enfrentar isso, a equipe recorre a um otimizador inspirado na natureza modelado a partir do movimento dos gafanhotos. No algoritmo dinâmico de otimização por gafanhotos, cada “gafanhoto” representa um subconjunto diferente de características. Ao longo de muitas iterações, o enxame explora combinações, guiado por um equilíbrio entre ampla exploração e convergência em regiões promissoras. Crucialmente, os parâmetros de controle mudam ao longo do tempo, impedindo que o enxame fique preso muito cedo. O resultado é um conjunto muito menor de características altamente informativas — cerca de cem em vez de 1.280 — que ainda codificam sinais importantes, como aglomerados de microaneurismas, manchas de exsudatos ou padrões de inchaço dos vasos.
Muitas opiniões simples tornam o diagnóstico mais forte
Em vez de confiar em um único modelo, o sistema usa um ensemble empilhado de vários classificadores diferentes. Uma máquina de vetores de suporte, uma rede bayesiana e uma árvore de decisão recebem o conjunto de características otimizado e produzem sua própria probabilidade de que um olho pertença a um determinado estágio da doença. Essas “opiniões” são então combinadas por um método de gradient boosting rápido chamado LightGBM, que aprende a ponderar cada modelo base dependendo da situação. Esse desenho em camadas reduz a chance de que os pontos cegos de um único modelo dominem. Os autores testam seu arcabouço em grandes conjuntos de dados públicos de imagens retinianas, incluindo as coleções amplamente usadas EyePACS e APTOS, e comparam com pipelines de deep learning de ponta e outros otimizadores inspirados na biologia.
Quão bem o sistema se sai em testes que simulam o mundo real
Ao longo dos experimentos, o arcabouço dinâmico de gafanhotos com ensemble supera consistentemente métodos concorrentes. Em benchmarks-chave, alcança cerca de 94–95% de acurácia, uma alta pontuação F1 (que equilibra casos perdidos e falsos positivos) e uma área sob a curva ROC de 0,96, indicando forte separação entre olhos saudáveis e doentes. Também generaliza bem entre diferentes divisões treino–teste e conjuntos de dados adicionais, e mantém a maior parte de seu desempenho quando as imagens são artificialmente mais ruidosas ou distorcidas — condições que simulam a variabilidade de clínicas reais. Por contraste, algoritmos de enxame anteriores com configurações fixas tendem a convergir cedo demais, manter mais características redundantes e apresentar sensibilidade e especificidade menores, especialmente em dados desafiadores ou desbalanceados.
O que isso significa para pacientes e clínicas
Em termos práticos, o estudo mostra que combinar uma rede moderna de análise de imagens com um enxame inteligente de seleção de características e um conjunto de classificadores simples pode produzir um “segundo leitor” rápido, preciso e comparativamente robusto para doença ocular diabética. Uma ferramenta assim não substituirá oftalmologistas, mas pode ajudar a sinalizar pacientes em risco mais cedo, especialmente em clínicas movimentadas ou com poucos recursos, onde especialistas são escassos. Os autores observam que validação adicional em dados locais de hospitais e trabalho contínuo para reduzir o custo computacional ainda são necessários, mas sua abordagem consciente à física da imagem e dirigida por otimização aproxima a triagem automatizada de uma implantação confiável no mundo real.
Citação: Darwish, S.M., Milad, K.G. & Ibrahim, R.E.ED. An enhanced diabetic retinopathy detection approach using optimized deep learning technique. Sci Rep 16, 9825 (2026). https://doi.org/10.1038/s41598-026-41998-y
Palavras-chave: retinopatia diabética, imagens da retina, deep learning, seleção de características, IA médica