Clear Sky Science · it
Un approccio migliorato per la rilevazione della retinopatia diabetica usando una tecnica di deep learning ottimizzata
Perché è importante individuare precocemente i danni oculari
Il diabete può danneggiare silenziosamente i piccoli vasi sanguigni nella parte posteriore dell'occhio, conducendo col tempo a visione offuscata o addirittura alla cecità. Gli oculisti possono individuare questa condizione—chiamata retinopatia diabetica—esaminando fotografie dettagliate della retina. Ma con milioni di persone a rischio e pochi specialisti disponibili, molti pazienti non vengono mai sottoposti a screening in tempo. Questo studio esplora come un sistema di intelligenza artificiale progettato con cura possa leggere le foto retiniche con maggiore accuratezza e affidabilità, aiutando a individuare i problemi abbastanza presto da salvare la vista.
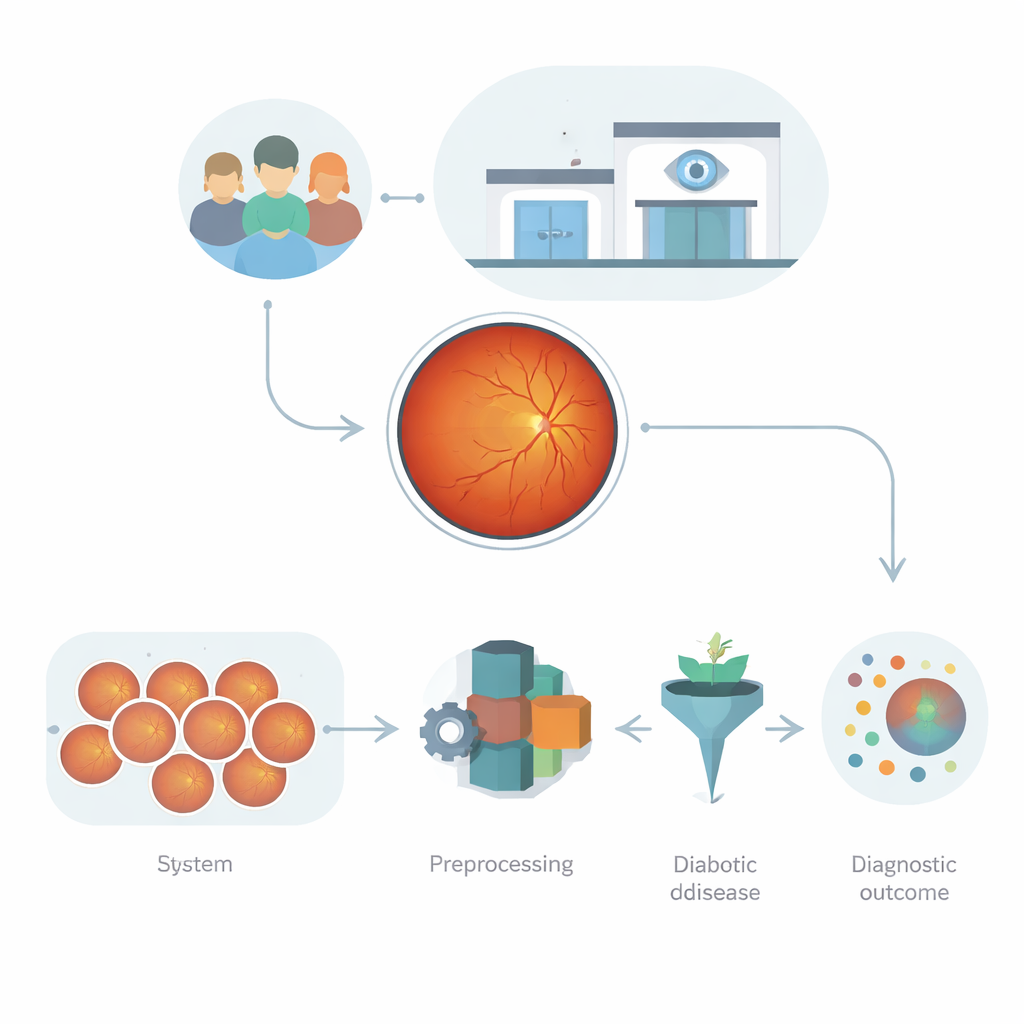
Le immagini dell'occhio come miniera di dati
Le fotografie retiniche, note come immagini del fondo oculare, sono molto più di semplici istantanee. Catturano come la luce venga assorbita, riflessa e diffusa dagli strati dell'occhio, rivelando vasi sanguigni, piccole perdite e cicatrici. Questi motivi sono ricchi di indizi sul danno diabetico, ma sono anche complessi: le immagini variano per luminosità, messa a fuoco, tipo di fotocamera e caratteristiche del paziente. I programmi informatici precedenti si affidavano o a misure progettate a mano, che possono perdere cambiamenti sottili, o a reti di deep learning che possono essere potenti ma soggette a sovradattamento, soprattutto quando varia la qualità delle immagini o il contesto clinico. La sfida è costruire un sistema automatizzato in grado di imparare da questi dati disordinati e ad alta dimensionalità senza diventare fragile o imprevedibile.
Insegnare a una rete neurale a riconoscere i segnali d'allarme chiave
Gli autori impiegano innanzitutto un modello di deep learning moderno, EfficientNet‑B0, come un «estrattore di caratteristiche» altamente addestrato per ogni immagine retinica. Invece di far segnare manualmente agli specialisti ogni emorragia o deposito lipidico, la rete impara pattern visivi astratti che compaiono costantemente negli occhi malati rispetto a quelli sani. Per rendere il sistema più robusto, tutte le immagini vengono ripulite e standardizzate: ridimensionate, convertite in scala di grigi per concentrarsi sulla struttura invece che sul colore, e migliorate per mettere in risalto piccole macchie e dettagli dei vasi. Le immagini in scala di grigi vengono poi convertite in un formato gestibile dal modello pre‑addestrato, e gli strati finali della rete vengono leggermente adattati in fine‑tuning in modo che i filtri interni rispondano più fortemente alle strutture retiniche anziché agli oggetti di uso quotidiano.
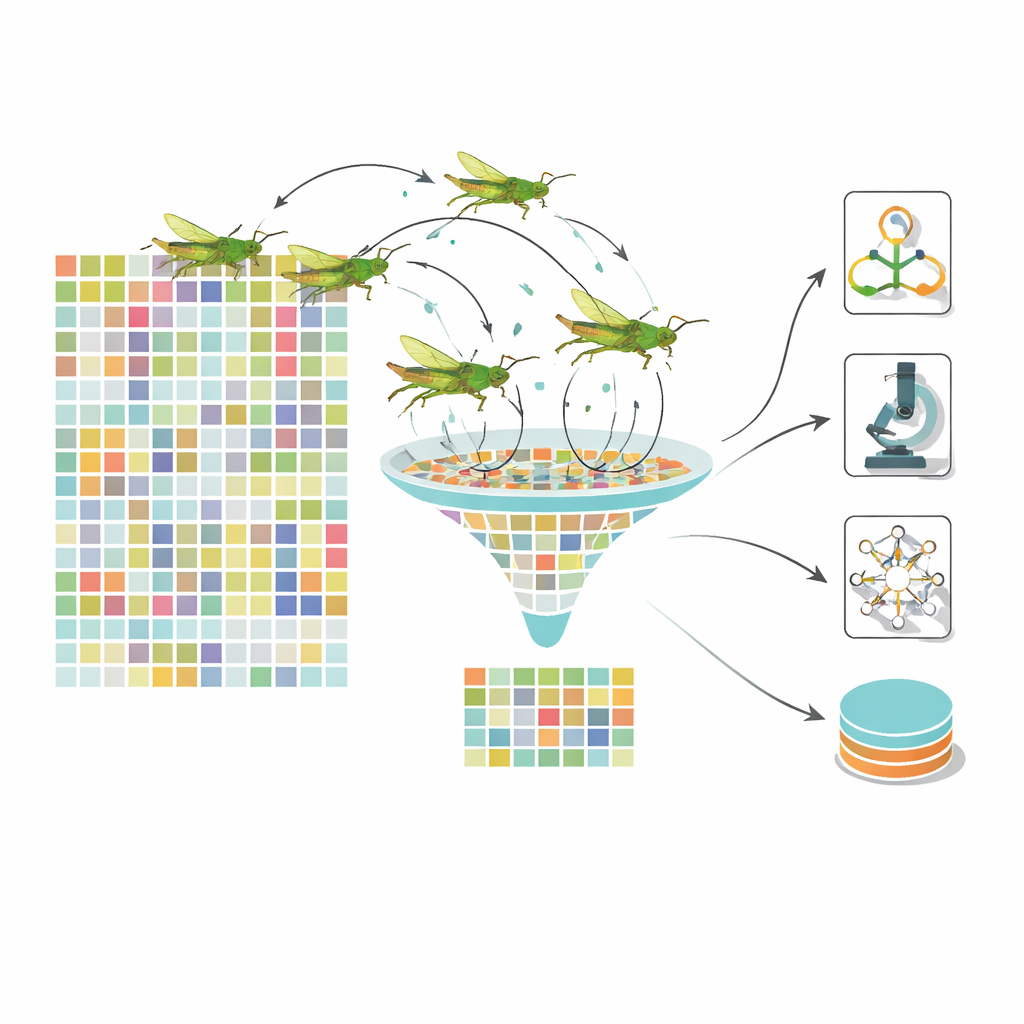
Lasciare che uno sciame virtuale scelga gli indizi più rivelatori
Anche dopo il deep learning, ogni immagine è rappresentata da oltre mille caratteristiche numeriche, molte delle quali ridondanti. Alimentare tutte queste in un classificatore rallenta l'apprendimento e può sfumare la distinzione tra stadi della malattia. Per affrontare il problema, il team ricorre a un ottimizzatore ispirato alla natura modellato sul movimento dei cavallette. Nel loro algoritmo dinamico di ottimizzazione a cavallette, ogni «cavalletta» rappresenta un diverso sottoinsieme di caratteristiche. Nel corso di molte iterazioni, lo sciame esplora combinazioni, guidato da un equilibrio tra l'esplorazione ampia e l'avvicinamento alle regioni promettenti. Cruciale è il fatto che i parametri di controllo cambiano nel tempo, evitando che lo sciame si blocchi troppo presto. Il risultato è un insieme molto più piccolo di caratteristiche altamente informative—circa cento invece di 1.280—che comunque codificano segni importanti come aggregati di microaneurismi, chiazze di essudati o pattern di rigonfiamento vascolare.
Molte opinioni semplici formano una diagnosi più solida
Invece di affidarsi a un singolo modello, il sistema usa un ensemble impilato di diversi classificatori. Una support vector machine, una rete bayesiana e un albero decisionale ricevono ciascuno il set di caratteristiche ottimizzato e producono la propria probabilità che un occhio appartenga a un dato stadio della malattia. Queste «opinioni» vengono poi combinate da un metodo di gradient‑boosting rapido chiamato LightGBM, che impara a pesare ciascun modello di base a seconda della situazione. Questo design a strati riduce la probabilità che i punti ciechi di un singolo modello prevalgano. Gli autori testano il loro framework su ampi dataset pubblici di immagini retiniche, incluse le ben note collezioni EyePACS e APTOS, e lo confrontano con pipeline di deep learning all'avanguardia e altri ottimizzatori ispirati alla natura.
Quanto bene il sistema si comporta in test simili al mondo reale
Negli esperimenti, il framework dinamico cavalletta‑ensemble supera costantemente i metodi concorrenti. Su benchmark chiave raggiunge circa il 94–95% di accuratezza, un alto punteggio F1 (che bilancia casi mancati e falsi allarmi) e un'area sotto la curva ROC di 0,96, indicando una forte separazione tra occhi sani e malati. Generalizza inoltre bene attraverso diverse suddivisioni train–test e dataset aggiuntivi, mantenendo la maggior parte delle prestazioni quando le immagini sono rese artificialmente più rumorose o distorte—condizioni pensate per imitare la variabilità delle cliniche reali. Per contro, i precedenti algoritmi swarm con impostazioni fisse tendono a convergere troppo presto, conservano più caratteristiche ridondanti e forniscono sensibilità e specificità inferiori, soprattutto su dati difficili o sbilanciati.
Cosa significa questo per pazienti e cliniche
In termini pratici, lo studio mostra che combinare una moderna rete di analisi delle immagini con uno sciame intelligente per la selezione delle caratteristiche e una squadra di classificatori semplici può produrre un «secondo lettore» veloce, accurato e relativamente robusto per le malattie retiniche diabetiche. Uno strumento del genere non sostituirà gli oculisti, ma può aiutare a segnalare i pazienti a rischio prima, specialmente in cliniche affollate o con risorse limitate dove gli specialisti scarseggiano. Gli autori osservano che sono ancora necessari ulteriori validazioni su dati ospedalieri locali e lavoro continuo per ridurre i costi computazionali, ma il loro approccio consapevole della fisica e guidato dall'ottimizzazione avvicina lo screening automatizzato a un'implementazione affidabile nel mondo reale.
Citazione: Darwish, S.M., Milad, K.G. & Ibrahim, R.E.ED. An enhanced diabetic retinopathy detection approach using optimized deep learning technique. Sci Rep 16, 9825 (2026). https://doi.org/10.1038/s41598-026-41998-y
Parole chiave: retinopatia diabetica, imaging retinico, deep learning, selezione delle caratteristiche, IA medica