Clear Sky Science · fr
Une approche améliorée de détection de la rétinopathie diabétique utilisant une technique d’apprentissage profond optimisée
Pourquoi il est important de repérer tôt les lésions oculaires
Le diabète peut endommager silencieusement les petits vaisseaux sanguins à l’arrière de l’œil, menant progressivement à une vision floue voire à la cécité. Les ophtalmologistes peuvent dépister cette affection — appelée rétinopathie diabétique — en examinant des photographies détaillées de la rétine. Mais avec des millions de personnes à risque et trop peu de spécialistes, de nombreux patients ne sont jamais dépistés à temps. Cette étude examine comment un système d’intelligence artificielle soigneusement conçu peut interpréter les photos rétiniennes de façon plus précise et fiable, aidant à détecter les signes précoces suffisamment tôt pour préserver la vue.
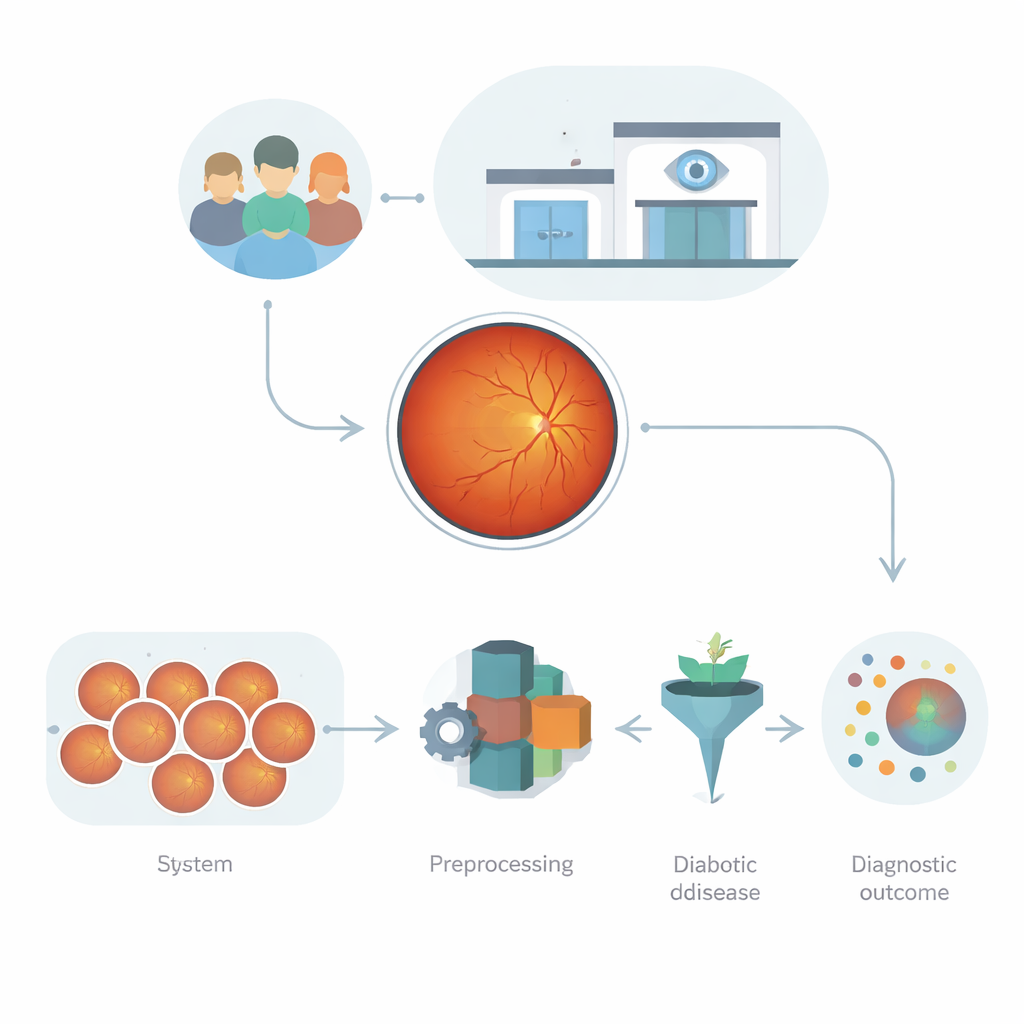
Les images de l’œil : une mine de données
Les photographies rétiniennes, appelées images du fond d’œil, sont bien plus que de simples instantanés. Elles enregistrent la façon dont la lumière est absorbée, réfléchie et diffusée par les couches de l’œil, révélant les vaisseaux sanguins, de minuscules fuites et des cicatrices. Ces motifs contiennent de précieux indices sur les lésions diabétiques, mais ils sont aussi complexes : les images varient en luminosité, netteté, type d’appareil et profil des patients. Les premières approches informatiques s’appuyaient soit sur des mesures manuelles, qui ratent les changements subtils, soit sur des réseaux profonds puissants mais susceptibles de surapprendre, surtout lorsque la qualité des images ou le contexte clinique diffèrent. Le défi est de construire un système automatisé capable d’apprendre à partir de ces données désordonnées et de haute dimension sans devenir fragile ou imprévisible.
Apprendre au réseau neuronal à détecter les signes clés
Les auteurs commencent par utiliser un modèle d’apprentissage profond moderne, EfficientNet‑B0, comme « extracteur de caractéristiques » très entraîné pour chaque image rétinienne. Plutôt que de demander aux médecins d’annoter manuellement chaque hémorragie ou dépôt lipidique, le réseau apprend des motifs visuels abstraits qui apparaissent de façon cohérente dans les yeux malades par rapport aux yeux sains. Pour rendre le système plus robuste, toutes les images sont nettoyées et standardisées : elles sont redimensionnées, converties en niveaux de gris pour se concentrer sur la structure plutôt que sur la couleur, et améliorées pour accentuer les petites taches et les détails vasculaires. Les images en niveaux de gris sont ensuite adaptées au format requis par le réseau préentraîné, et les couches finales du modèle sont légèrement ajustées afin que ses filtres internes réagissent fortement aux structures rétiniennes plutôt qu’à des objets du quotidien.
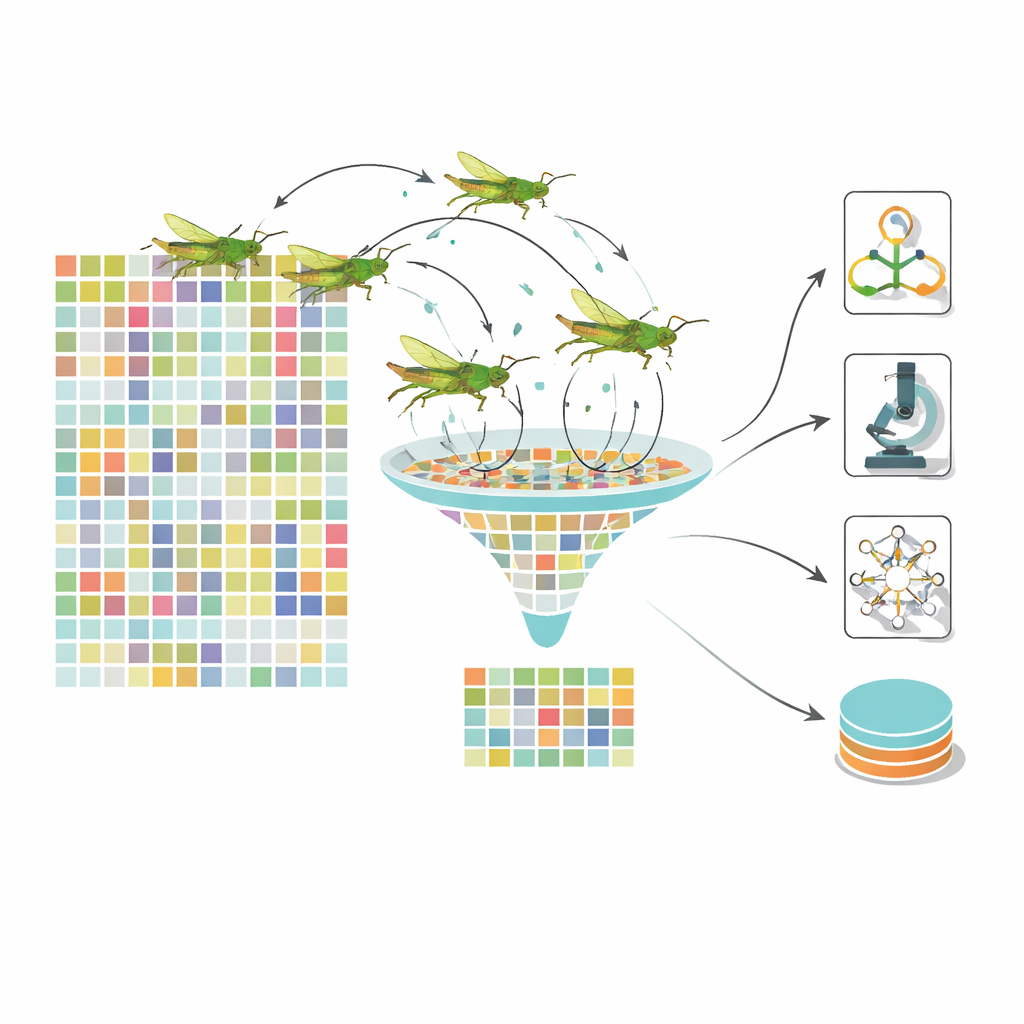
Laisser un essaim virtuel sélectionner les indices les plus pertinents
Même après l’apprentissage profond, chaque image est représentée par plus d’un millier de caractéristiques numériques, beaucoup étant redondantes. Entrer toutes ces caractéristiques dans un classificateur ralentit l’apprentissage et peut estomper la distinction entre les stades de la maladie. Pour y remédier, l’équipe recourt à un optimiseur inspiré de la nature, modélisé sur le mouvement des sauterelles. Dans leur algorithme dynamique d’optimisation par sauterelles, chaque « sauterelle » représente un sous‑ensemble différent de caractéristiques. Au fil des itérations, l’essaim explore des combinaisons, guidé par un équilibre entre exploration large et concentration sur des régions prometteuses. Crucialement, les paramètres de contrôle évoluent dans le temps, empêchant l’essaim de se bloquer trop tôt. Le résultat est un ensemble beaucoup plus réduit de caractéristiques très informatives — environ une centaine au lieu de 1 280 — qui codent néanmoins des signes importants tels que des regroupements de microanévrismes, des plages d’exsudats ou des motifs de dilatation vasculaire.
Plusieurs avis simples pour un diagnostic plus solide
Plutôt que de se fier à un seul modèle, le système utilise un empilement (stacked ensemble) de plusieurs classificateurs différents. Une machine à vecteurs de support, un réseau bayésien et un arbre de décision reçoivent chacun l’ensemble de caractéristiques optimisé et produisent leur propre probabilité qu’un œil appartienne à un stade de la maladie donné. Ces « avis » sont ensuite combinés par une méthode de gradient boosting rapide appelée LightGBM, qui apprend à pondérer chaque modèle de base en fonction du contexte. Cette conception en couches réduit le risque qu’un angle mort d’un seul modèle n’emporte la décision. Les auteurs testent leur architecture sur de larges jeux de données publics d’images rétiniennes, incluant les collections largement utilisées EyePACS et APTOS, et la comparent aux principaux pipelines d’apprentissage profond et à d’autres optimiseurs inspirés du vivant.
Performance du système dans des tests proches du monde réel
Dans les expériences, l’architecture dynamique sauterelle‑essaim obtient systématiquement de meilleurs résultats que les méthodes concurrentes. Sur des benchmarks clés, elle atteint environ 94–95 % de précision, un score F1 élevé (qui équilibre cas manqués et fausses alertes), et une aire sous la courbe ROC de 0,96, indiquant une forte séparation entre yeux sains et malades. Elle généralise également bien sur différentes partitions entraînement‑test et jeux de données additionnels, et conserve la majeure partie de sa performance lorsque les images sont rendues artificiellement plus bruitées ou dégradées — conditions destinées à simuler la variabilité des cliniques réelles. En revanche, les anciens algorithmes d’essaim à paramètres fixes tendent à converger trop tôt, à conserver davantage de caractéristiques redondantes et à fournir une sensibilité et une spécificité inférieures, surtout sur des données difficiles ou déséquilibrées.
Ce que cela signifie pour les patients et les cliniques
En termes concrets, l’étude montre que combiner un réseau d’analyse d’images moderne avec un essaim intelligent de sélection de caractéristiques et une équipe de classificateurs simples peut produire un « second lecteur » rapide, précis et relativement robuste pour la maladie oculaire diabétique. Un tel outil ne remplacera pas les ophtalmologistes, mais il peut aider à repérer plus tôt les patients à risque, notamment dans les cliniques surchargées ou sous‑équipées où les spécialistes sont rares. Les auteurs notent qu’une validation complémentaire sur des données hospitalières locales et des efforts pour réduire le coût computationnel restent nécessaires, mais leur approche consciente de la physique de l’image et guidée par l’optimisation rapproche le dépistage automatisé d’un déploiement fiable en conditions réelles.
Citation: Darwish, S.M., Milad, K.G. & Ibrahim, R.E.ED. An enhanced diabetic retinopathy detection approach using optimized deep learning technique. Sci Rep 16, 9825 (2026). https://doi.org/10.1038/s41598-026-41998-y
Mots-clés: rétinopathie diabétique, imagerie rétinienne, apprentissage profond, séléction de caractéristiques, IA médicale