Clear Sky Science · pl
Regularyzacja jądra projekcji dla segmentacji wielomodalnej w oparciu o modele dyfuzji
Bardziej wyraźne mapy z lotu ptaka
Współczesne miasta obserwowane są z góry przez floty samolotów i satelitów, które rejestrują nie tylko kolorowe zdjęcia, ale także informacje o wysokości w formie 3D. Przekształcenie tego bogactwa danych w precyzyjne mapy budynków, dróg, drzew i samochodów jest kluczowe dla planowania, reagowania na katastrofy i monitoringu środowiska. W artykule przedstawiono nowy sposób łączenia tych różnych widoków i oczyszczania zaszumionych przewidywań, co daje ostrzejsze i bardziej wiarygodne mapy pokrycia terenu z obrazów lotniczych.
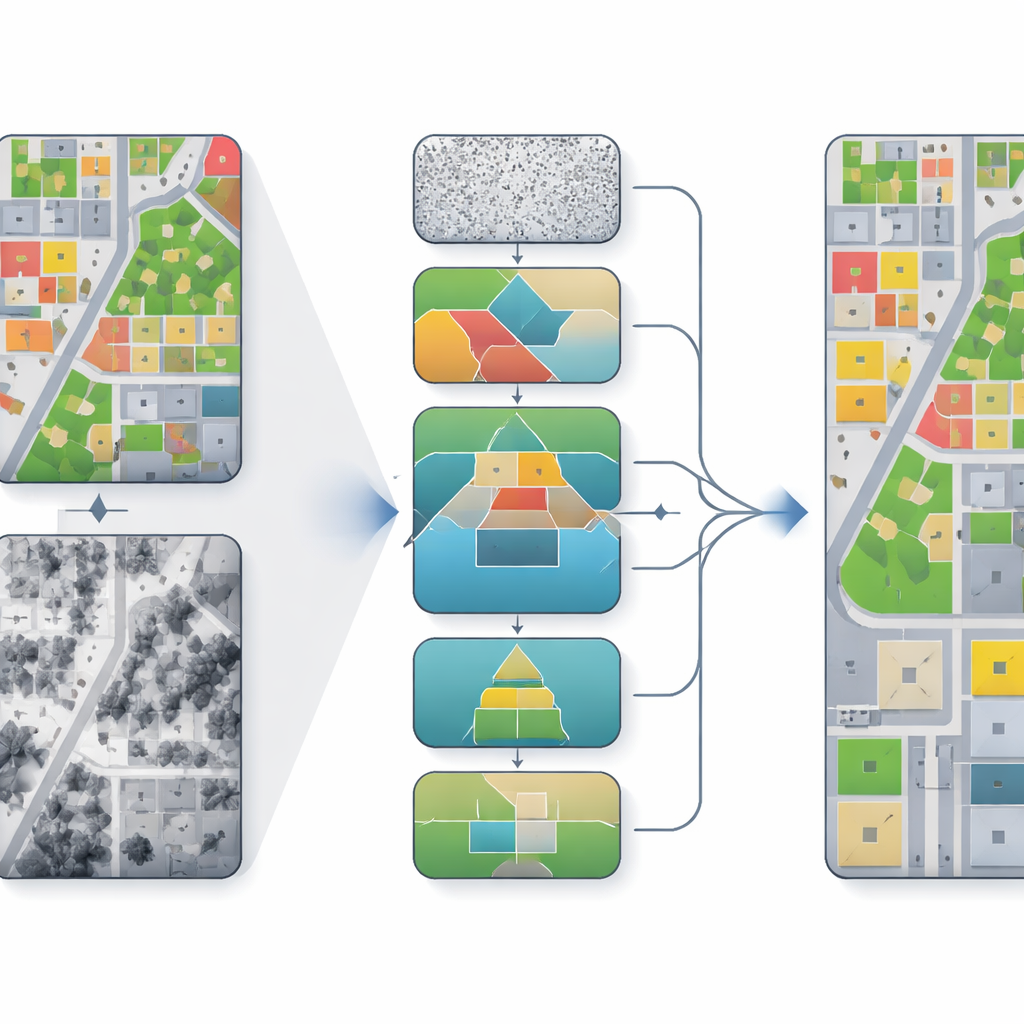
Dlaczego łączenie widoków z nieba jest trudne
Systemy mapowania lotniczego często łączą dwa główne typy wejść: ortofotomapy, które wyglądają jak szczegółowe kolorowe zdjęcia terenu, oraz cyfrowe modele powierzchni, które zapisują wysokość każdego punktu. Fotografie są bogate w teksturę i kolor, ale mogą być zniekształcone przez cienie i perspektywę. Mapy wysokości oddają kształty budynków i korony drzew, lecz bywają zaszumione lub o niskiej rozdzielczości. Tradycyjne metody głębokiego uczenia albo łączą te wejścia w sposób „nałożony”, albo fuzują je prostymi mechanizmami. W efekcie mogą źle dopasowywać geometrię i teksturę, rozmywać granice między obiektami i pomijać drobne elementy, takie jak samochody, szczególnie w gęstych scenach miejskich.
Od zaszumionych zgadywań do dopracowanych obrazów
Autorzy opierają się na modelach dyfuzji — rodzinie algorytmów, które zaczynają od zaszumionych przewidywań i iteracyjnie je oczyszczają, prowadząc ku bardziej klarownemu rezultatowi. Zamiast traktować segmentację jako decyzję jednorazową, model wykonuje wiele drobnych kroków, stopniowo poprawiając mapę klas pikseli. W ich ramie, nazwanej PKDiff, proces ten jest kierowany przez dwa kluczowe pomysły: inteligentniejsze łączenie informacji z fotografii i wysokości oraz nowy sposób zapewnienia, że ogólny rozkład przewidywań odpowiada oczekiwaniom w całym obrazie, a nie tylko na poziomie pojedynczych pikseli.
Ułatwienie współpracy obrazów i map wysokości
Aby lepiej połączyć zalety danych fotograficznych i wysokościowych, model wykorzystuje moduł fuzji z podwójnym enkoderem i mechanizmem cross-attention. Jeden nurt koncentruje się na kolorze i teksturze, drugi na wysokości i strukturze. Na współrzędnych o niskiej rozdzielczości informacje o wysokości kierują modelem ku właściwemu ogólnemu układowi — gdzie powinny znajdować się budynki, drogi i parki. Na większych powiększeniach różnice wysokości wzdłuż krawędzi pomagają wyostrzyć granice, na przykład linii dachów czy przejść między drzewami a trawą. Osobny komponent odszumiający, nazwany Hierarchical EMA-Gated Recursive Denoising, przekazuje informacje między skalami i krokami czasowymi, decydując, ile ufać nowym poprawkom w stosunku do wcześniejszych estymat. Redukuje to ryzyko, że wczesne błędy będą się stopniowo wzmacniać wraz z iteracjami modelu.
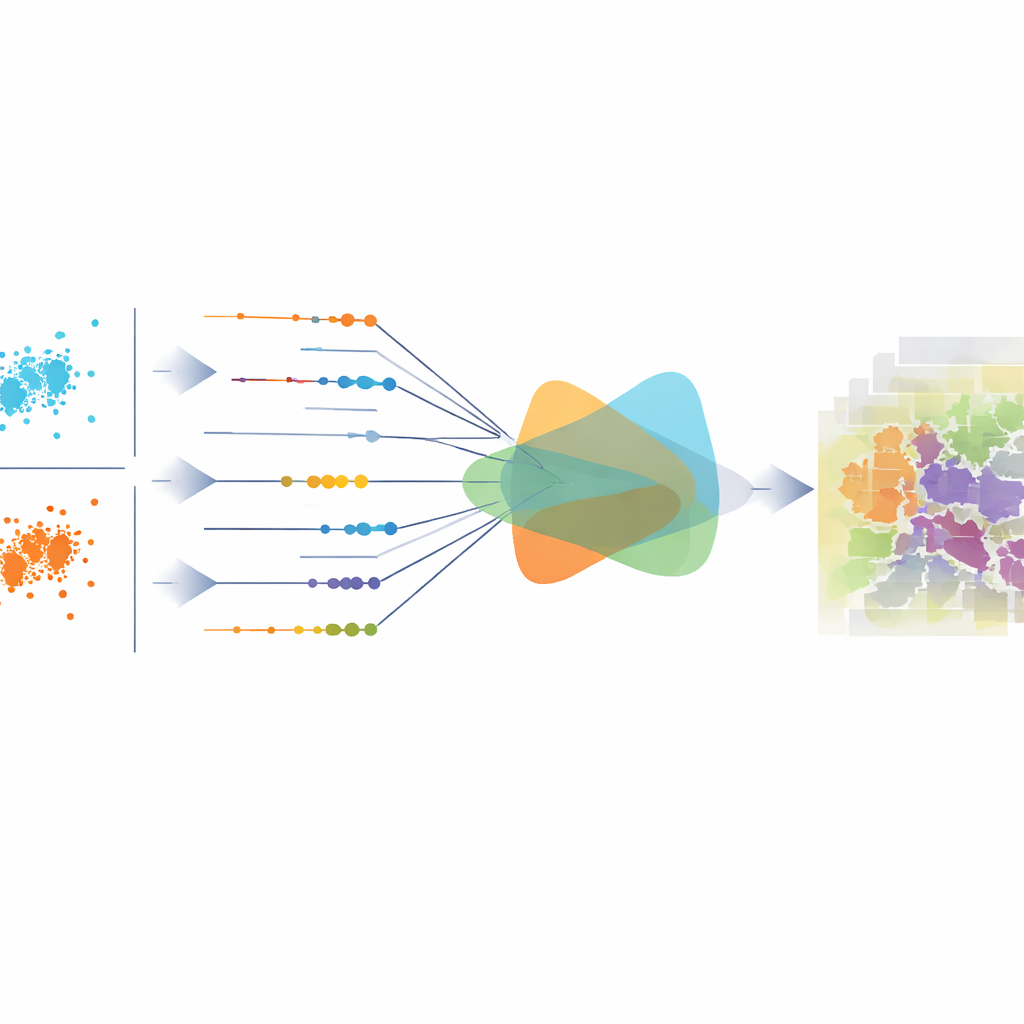
Dopasowanie obrazu jako całości, a nie tylko pojedynczych pikseli
Większość istniejących metod trenuje modele przy użyciu funkcji straty, które patrzą na każdy piksel z osobna, takich jak cross-entropy czy średni błąd kwadratowy. Mogą one poprawić lokalną dokładność, ale nadal generować przewidywania statystycznie niewyważone w skali całego obrazu — na przykład przeszacowując drogi lub niedoszacowując roślinność. Główny wkład tej pracy to regularizator jądra projekcji, który mierzy, jak dobrze ogólny rozkład przewidywanych klas odpowiada prawdziwemu rozkładowi. Robi to, traktując wektor prawdopodobieństw klasy każdego piksela jako punkt w przestrzeni o wysokim wymiarze, rzutując te punkty w wiele jednowymiarowych kierunków i porównując, jak różnią się zbiory projekcji. Zamiast losowo wybierać kierunki, autorzy wyprowadzają elegancką formułę w zamkniętej postaci, która efektywnie agreguje różnice po wszystkich kierunkach, dzięki czemu miara jest zarówno stabilna, jak i czuła na subtelne przesunięcia.
Lepsze granice i spójniejsze mapy
Autorzy testują swoją metodę na dwóch znanych miejskich benchmarkach z niemieckich miast Vaihingen i Potsdam, które zawierają obrazy o bardzo wysokiej rozdzielczości i mapy wysokości oraz etykiety referencyjne dla powierzchni, budynków, roślinności, drzew, samochodów i elementów nieistotnych. W kilku standardowych miarach dokładności PKDiff przewyższa różne silne modele konwolucyjne, oparte na Transformatorach oraz inne metody oparte na dyfuzji. Korzyści są szczególnie widoczne w kategoriach, gdzie geometria ma kluczowe znaczenie, takich jak budynki, niska roślinność i małe samochody: granice są ostrzejsze, obiekty mniej pofragmentowane, a duże obszary, jak drogi, mają bardziej spójne etykietowanie. Mówiąc prościej: dzięki starannemu łączeniu tekstury i wysokości oraz wymuszaniu, by przewidywania „wyglądały poprawnie” w agregacie, proponowane podejście daje czystsze i bardziej wiarygodne mapy złożonych danych lotniczych.
Cytowanie: Tong, X., Yang, F., Yang, Q. et al. Projection Kernel regularization for diffusion-based multimodal remote sensing segmentation. Sci Rep 16, 14385 (2026). https://doi.org/10.1038/s41598-026-44603-4
Słowa kluczowe: segmentacja teledetekcyjna, fuzja multimodalna, modele dyfuzji, mapowanie miejskie, fotografie lotnicze