Clear Sky Science · en
Projection Kernel regularization for diffusion-based multimodal remote sensing segmentation
Sharper Maps from Overhead
Modern cities are watched from above by fleets of planes and satellites, capturing not only colorful photos but also 3D height information. Turning this wealth of data into precise maps of buildings, roads, trees, and cars is vital for planning, disaster response, and environmental monitoring. This paper introduces a new way to fuse these different views and to clean up noisy predictions, producing crisper, more reliable land-cover maps from aerial imagery.
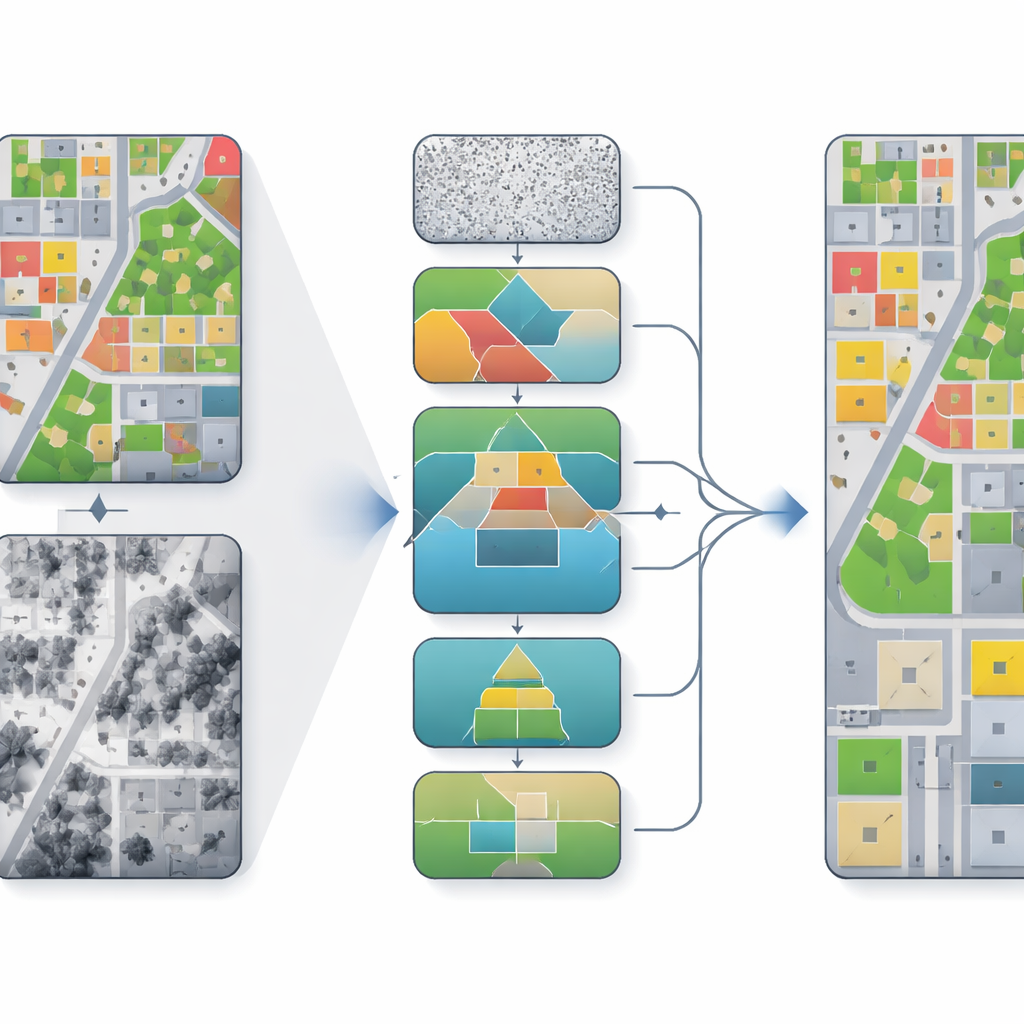
Why Mixing Views From the Sky Is Hard
Aerial mapping systems often combine two main types of inputs: true orthophotos, which look like detailed color images of the ground, and digital surface models, which record how high each point is. Photos are rich in texture and color but can be distorted by shadows and perspective. Height maps capture building shapes and tree canopies but can be noisy or coarse. Traditional deep learning methods either stack these inputs together or fuse them in simple ways. As a result, they can misalign geometry and texture, blur the borders between objects, and miss small features like cars, especially in dense urban scenes.
From Noisy Guesses to Refined Scenes
The authors build on diffusion models, a family of algorithms that start from noisy predictions and repeatedly refine them toward a cleaner result. Instead of treating segmentation as a one-shot decision, the model takes many small steps, gradually improving the map of which pixel belongs to which class. In their framework, called PKDiff, this refinement is guided by two key ideas: a smarter way of fusing photo and height information, and a new way of making sure the overall pattern of predictions matches what is expected across an entire image, not just pixel by pixel.
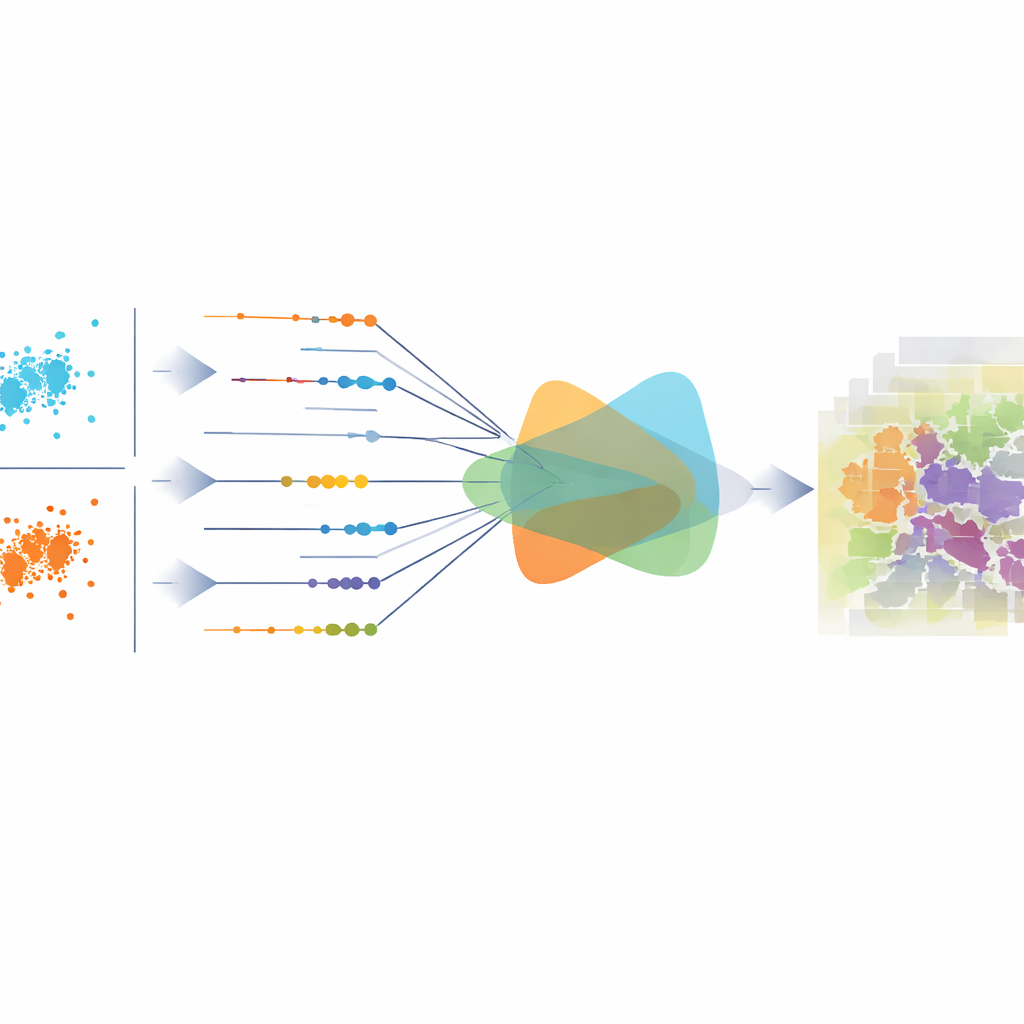
Helping Images and Heights Work Together
To better combine the strengths of the photo and height data, the model uses a Cross-Attention Dual-Encoder Fusion module. One branch focuses on color and texture, the other on height and structure. At coarse scales, height information steers the model toward the right overall layout—where buildings, roads, and parks should be. At finer scales, height differences along edges help sharpen borders, for example at rooflines or between trees and grass. A separate denoising component, called Hierarchical EMA-Gated Recursive Denoising, passes information across scales and time steps, deciding how much to trust new refinements versus past estimates. This reduces the risk that early mistakes will keep getting amplified as the model iterates.
Aligning the Big Picture, Not Just Individual Pixels
Most existing methods train their models with losses that look at each pixel on its own, such as cross-entropy or mean squared error. These can improve local accuracy but may still produce predictions that are statistically out of balance over the whole image—for example, overestimating roads or underestimating vegetation. The central contribution of this work is a projection-kernel regularizer that measures how well the overall distribution of predicted classes matches the true one. It does this by viewing each pixel’s class probabilities as a point in a high-dimensional space, projecting those points into many one-dimensional directions, and comparing how the two sets of projections differ. Instead of sampling these directions randomly, the authors derive a neat closed-form formula that efficiently aggregates differences across all directions, making the measure both stable and sensitive to subtle shifts.
Better Boundaries and More Consistent Maps
The authors test their method on two well-known urban benchmarks from the German towns of Vaihingen and Potsdam, which include very high resolution images and height maps along with ground-truth labels for surfaces, buildings, vegetation, trees, cars, and clutter. Across several standard accuracy measures, PKDiff outperforms a range of strong convolutional, Transformer-based, and other diffusion-based models. The gains are especially clear on categories where geometry matters most, such as buildings, low vegetation, and small cars: boundaries are sharper, objects are less fragmented, and large regions like roads are more consistently labeled. In simple terms, by carefully fusing texture and height while also enforcing that its predictions "look right" in aggregate, the proposed approach yields cleaner, more trustworthy maps from complex aerial data.
Citation: Tong, X., Yang, F., Yang, Q. et al. Projection Kernel regularization for diffusion-based multimodal remote sensing segmentation. Sci Rep 16, 14385 (2026). https://doi.org/10.1038/s41598-026-44603-4
Keywords: remote sensing segmentation, multimodal fusion, diffusion models, urban mapping, aerial imagery