Clear Sky Science · de
Projektionskern-Regularisierung für diffusionsbasierte multimodale Fernerkundungssegmentierung
Scharfere Karten aus der Vogelperspektive
Moderne Städte werden aus der Höhe von Flugzeugen und Satelliten beobachtet, die neben farbigen Fotos auch 3D-Höheninformationen erfassen. Aus diesem reichen Datenangebot präzise Karten von Gebäuden, Straßen, Bäumen und Fahrzeugen zu erstellen, ist entscheidend für Planung, Katastrophenreaktion und Umweltüberwachung. Dieses Papier stellt einen neuen Ansatz vor, um diese unterschiedlichen Sichtweisen zu fusionieren und verrauschte Vorhersagen zu bereinigen, sodass aus Luftbildern schärfere und verlässlichere Landbedeckungskarten entstehen.
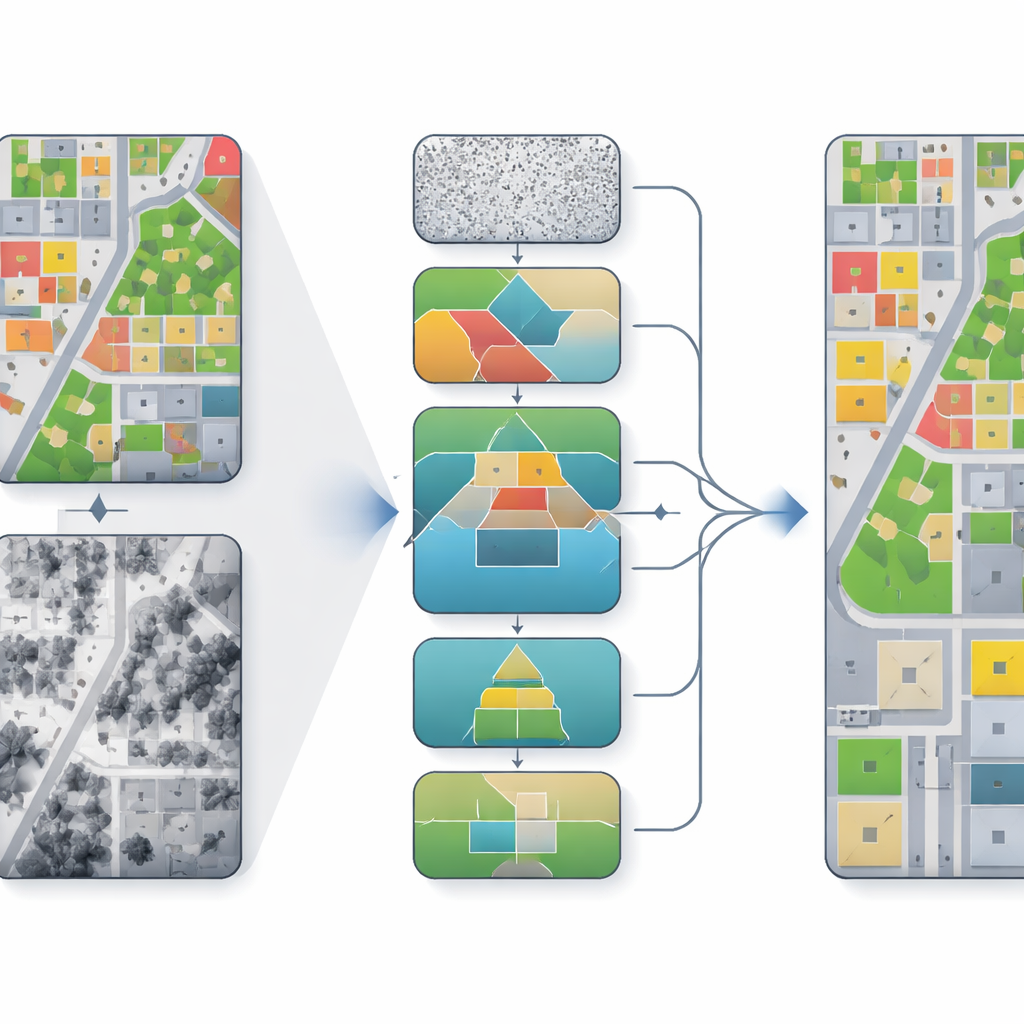
Warum das Zusammenführen von Ansichten aus der Luft schwierig ist
Systeme zur Luftbildkartierung kombinieren häufig zwei Haupttypen von Eingaben: echte Orthofotos, die wie detailreiche Farbbilder des Bodens wirken, und digitale Oberflächenmodelle, die die Höhe jedes Punkts aufzeichnen. Fotos liefern reichhaltige Textur- und Farbinformationen, können aber durch Schatten und Perspektive verzerrt sein. Höhenkarten erfassen Gebäudekonturen und Baumkronen, können jedoch verrauscht oder grob aufgelöst sein. Traditionelle Deep-Learning-Methoden legen diese Eingaben entweder einfach zusammen oder verschmelzen sie auf einfache Weise. In der Folge können Geometrie und Textur fehlanpasst werden, Kanten zwischen Objekten verschwimmen und kleine Objekte wie Autos übersehen werden, besonders in dicht bebauten Stadtbereichen.
Von verrauschten Vermutungen zu verfeinerten Szenen
Die Autoren bauen auf Diffusionsmodellen auf, einer Algorithmusfamilie, die von verrauschten Vorhersagen startet und diese schrittweise zu einem saubereren Ergebnis verfeinert. Anstatt Segmentierung als einmalige Entscheidung zu behandeln, nimmt das Modell viele kleine Schritte und verbessert nach und nach die Zuordnung, welcher Pixel zu welcher Klasse gehört. In ihrem Rahmen, PKDiff genannt, wird diese Verfeinerung von zwei Schlüsselideen geleitet: einer intelligenteren Methode zur Fusion von Foto- und Höheninformationen und einer neuen Art sicherzustellen, dass das Gesamtmuster der Vorhersagen dem über das ganze Bild erwarteten Muster entspricht — nicht nur pixelweise.
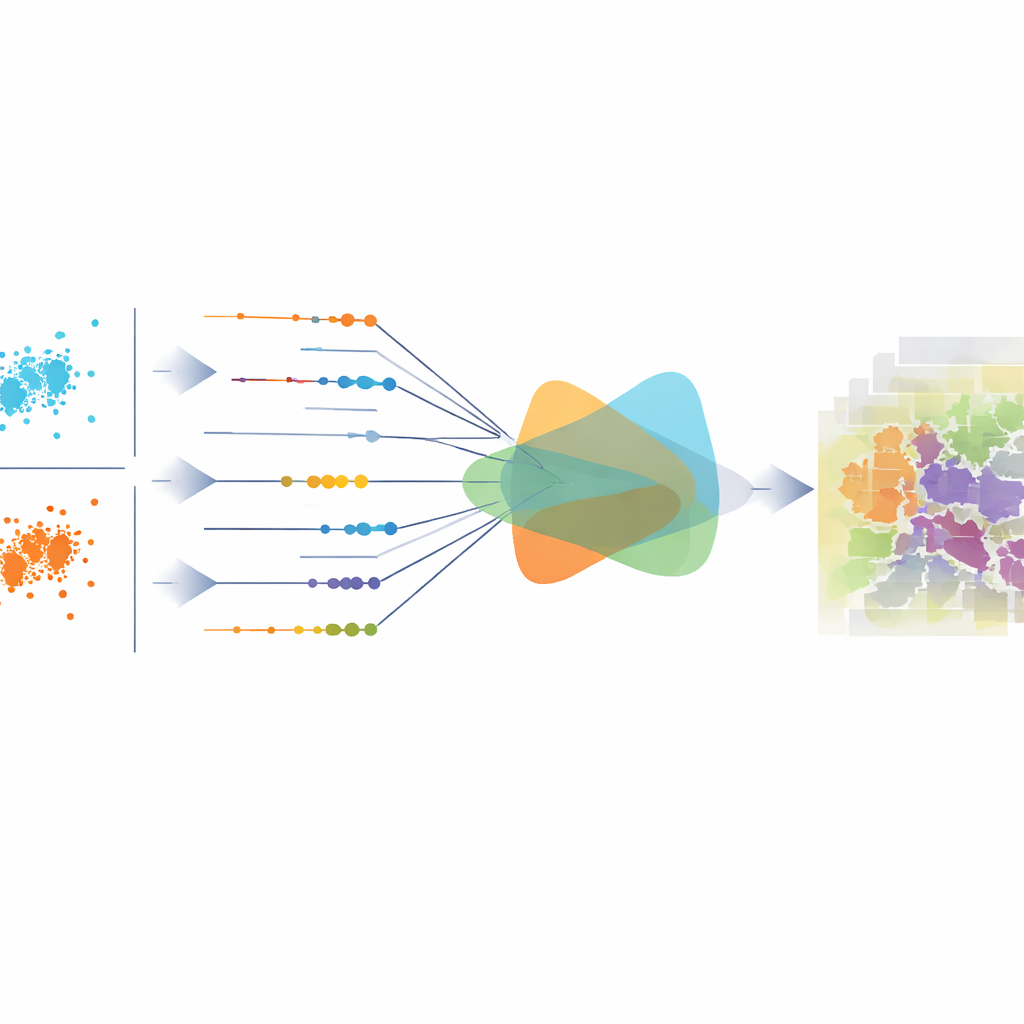
Foto- und Höheninformationen besser zusammenbringen
Um die Stärken von Foto- und Höhendaten besser zu kombinieren, verwendet das Modell ein Cross-Attention Dual-Encoder Fusion-Modul. Ein Zweig konzentriert sich auf Farbe und Textur, der andere auf Höhe und Struktur. Auf groben Skalen lenkt die Höheninformation das Modell zur richtigen Gesamtstruktur — wo sich Gebäude, Straßen und Parks befinden sollten. Auf feineren Skalen helfen Höhendifferenzen entlang von Kanten, Grenzen zu schärfen, etwa an Dachkanten oder zwischen Bäumen und Gras. Eine separate Rauschminderungs-Komponente, genannt Hierarchical EMA-Gated Recursive Denoising, überträgt Informationen über Skalen und Zeitschritte hinweg und entscheidet, wie sehr neue Verfeinerungen gegenüber früheren Schätzungen vertraut werden sollte. Das verringert das Risiko, dass frühe Fehler durch fortlaufende Iterationen verstärkt werden.
Das große Ganze ausrichten, nicht nur einzelne Pixel
Die meisten bestehenden Methoden trainieren ihre Modelle mit Verlusten, die jeden Pixel für sich betrachten, etwa Kreuzentropie oder mittlere quadratische Abweichung. Diese können die lokale Genauigkeit verbessern, liefern aber möglicherweise Vorhersagen, die statistisch über das ganze Bild hinweg unausgewogen sind — zum Beispiel Straßen zu überschätzen oder Vegetation zu unterschätzen. Der zentrale Beitrag dieser Arbeit ist ein Projektionskern-Regularisierer, der misst, wie gut die Gesamtverteilung der vorhergesagten Klassen der wahren Verteilung entspricht. Er betrachtet dazu die Klassenwahrscheinlichkeiten jedes Pixels als Punkt in einem hochdimensionalen Raum, projiziert diese Punkte in viele eindimensionale Richtungen und vergleicht, wie sich die beiden Mengen von Projektionen unterscheiden. Anstatt diese Richtungen zufällig zu sampeln, leiten die Autoren eine elegante geschlossene Formel her, die Unterschiede effizient über alle Richtungen aggregiert und das Maß sowohl stabil als auch empfindlich gegenüber subtilen Verschiebungen macht.
Bessere Grenzen und konsistentere Karten
Die Autoren testen ihre Methode an zwei bekannten städtischen Benchmarks aus den deutschen Städten Vaihingen und Potsdam, die sehr hochauflösende Bilder und Höhenkarten sowie Ground-Truth-Labels für Oberflächen, Gebäude, Vegetation, Bäume, Autos und Sonstiges enthalten. Über mehrere gängige Genauigkeitsmaße hinweg übertrifft PKDiff eine Reihe starker konvolutionaler, Transformer-basierter und anderer diffusionsbasierter Modelle. Die Verbesserungen sind besonders deutlich bei Kategorien, bei denen Geometrie entscheidend ist, wie Gebäude, niedrige Vegetation und kleine Autos: Grenzen sind schärfer, Objekte weniger fragmentiert und große Regionen wie Straßen konsistenter beschriftet. Einfach ausgedrückt: Durch die sorgfältige Fusion von Textur und Höhe und die gleichzeitige Durchsetzung, dass die Vorhersagen im Ganzen "richtig aussehen", liefert der vorgeschlagene Ansatz aus komplexen Luftdaten sauberere und vertrauenswürdigere Karten.
Zitation: Tong, X., Yang, F., Yang, Q. et al. Projection Kernel regularization for diffusion-based multimodal remote sensing segmentation. Sci Rep 16, 14385 (2026). https://doi.org/10.1038/s41598-026-44603-4
Schlüsselwörter: Fernerkundungssegmentierung, multimodale Fusion, Diffusionsmodelle, Stadtkartierung, Luftbildaufnahmen