Clear Sky Science · it
Regolarizzazione del kernel di proiezione per la segmentazione multimodale basata su modelli di diffusione
Mappe più nitide dall'alto
Le città moderne sono osservate dall'alto da flotte di aerei e satelliti che acquisiscono non solo fotografie a colori ma anche informazioni tridimensionali sull'altezza. Trasformare questa ricchezza di dati in mappe precise di edifici, strade, alberi e automobili è fondamentale per la pianificazione, la gestione delle emergenze e il monitoraggio ambientale. Questo lavoro introduce un nuovo metodo per fondere queste diverse viste e ripulire le previsioni rumorose, producendo mappe di copertura del suolo più nette e affidabili a partire da immagini aeree.
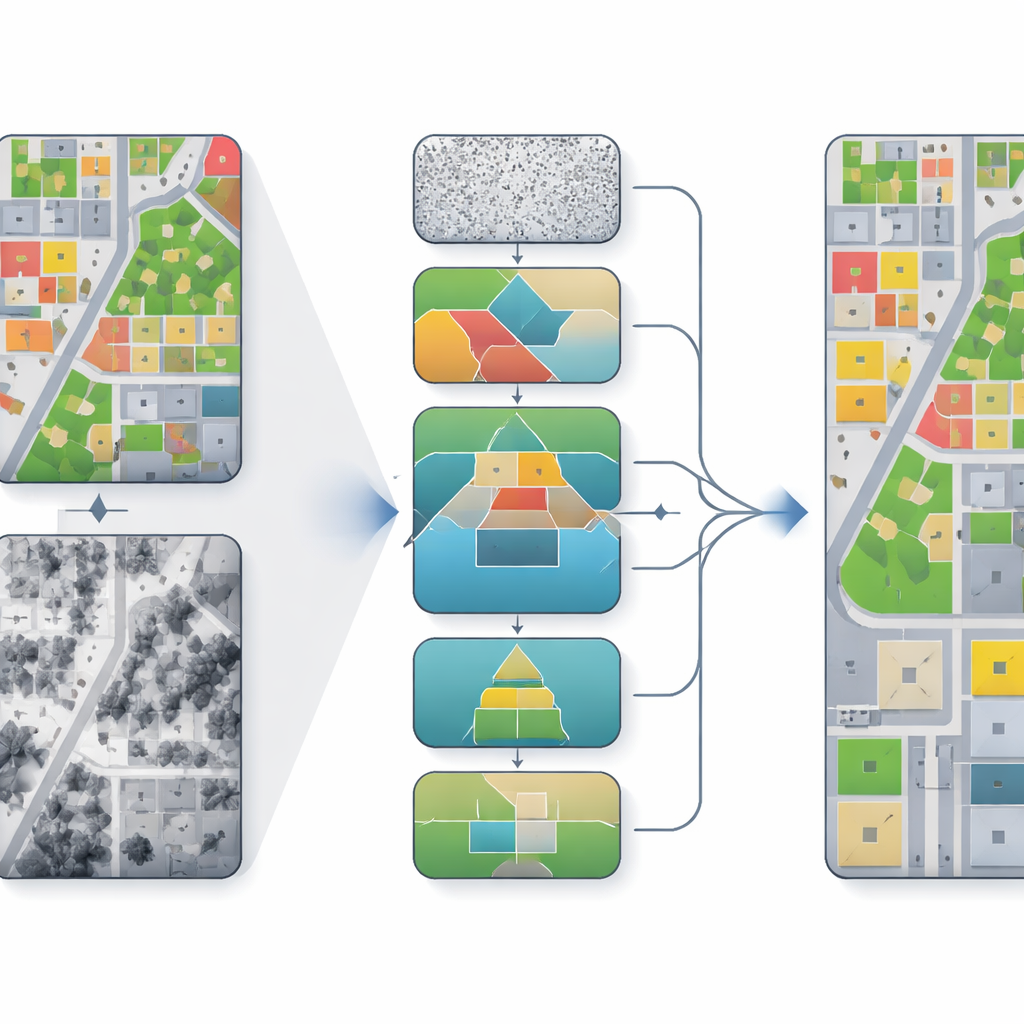
Perché è difficile combinare le viste dall'alto
I sistemi di mappatura aerea combinano spesso due tipi principali di input: ortofoto vere, che somigliano a immagini a colori dettagliate del terreno, e modelli digitali della superficie, che registrano l'altezza di ogni punto. Le foto sono ricche di texture e colore ma possono essere distorte da ombre e prospettiva. Le mappe di altezza catturano la forma di edifici e chiome degli alberi ma possono essere rumorose o a bassa risoluzione. I metodi di deep learning tradizionali o concatenano questi input o li fondono in modi semplici. Di conseguenza possono verificarsi disallineamenti tra geometria e texture, confusione ai bordi degli oggetti e la perdita di elementi piccoli come le automobili, specialmente in scene urbane dense.
Da ipotesi rumorose a scene rifinite
Gli autori si basano sui modelli di diffusione, una famiglia di algoritmi che partono da previsioni rumorose e le raffinano ripetutamente verso un risultato più pulito. Invece di trattare la segmentazione come una decisione in un unico passo, il modello compie molti piccoli passi, migliorando gradualmente la mappa delle classi pixel per pixel. Nel loro framework, chiamato PKDiff, questo raffinamento è guidato da due idee chiave: un modo più intelligente di fondere informazione fotografica e di altezza, e una nuova modalità per assicurare che lo schema complessivo delle previsioni corrisponda a quanto ci si aspetta sull'intera immagine, non solo a livello di singolo pixel.
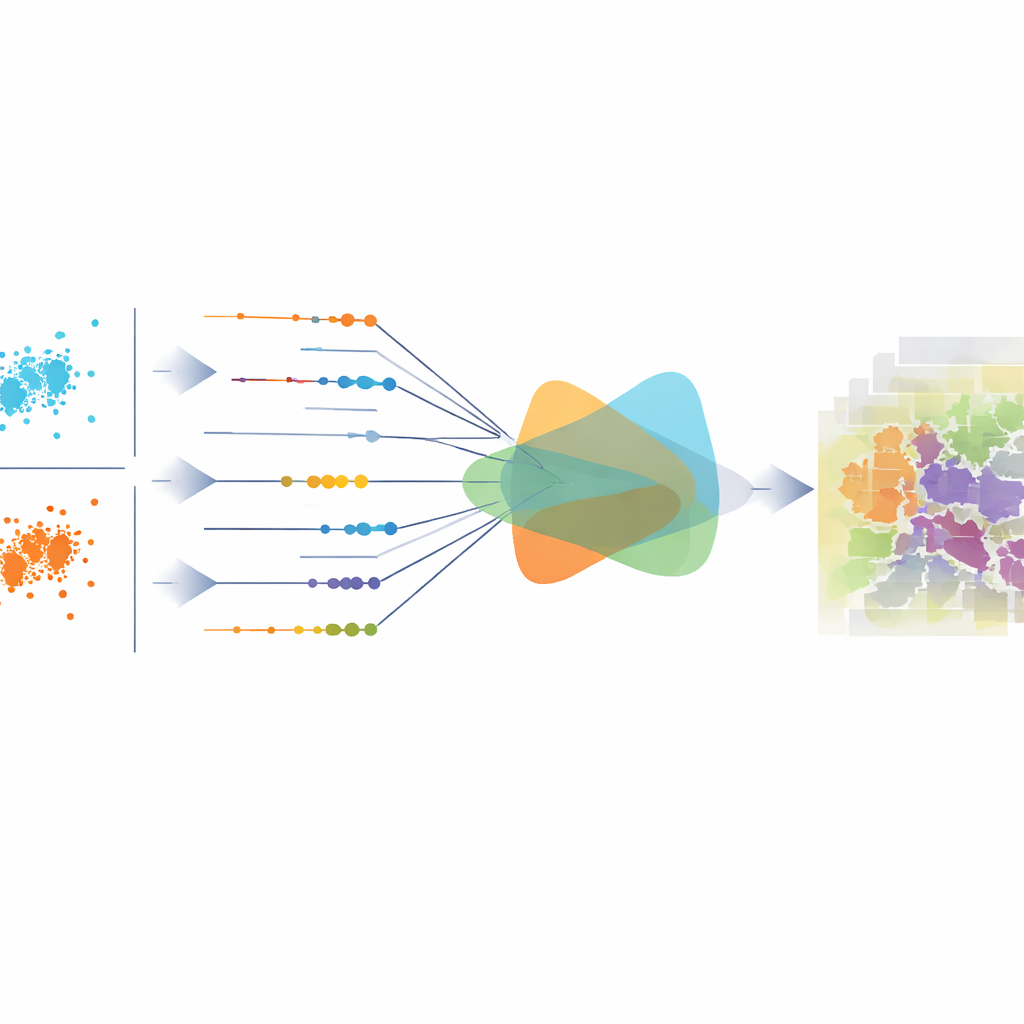
Far lavorare insieme immagini e altezze
Per combinare meglio i punti di forza di foto e dati di altezza, il modello utilizza un modulo di fusione a doppio encoder con cross-attention. Un ramo si concentra su colore e texture, l'altro su altezza e struttura. A scale grossolane, l'informazione di altezza orienta il modello verso la corretta disposizione generale — dove dovrebbero trovarsi edifici, strade e parchi. A scale più fini, le differenze di altezza lungo i bordi aiutano a definire i contorni, ad esempio nelle linee dei tetti o tra alberi e prato. Un componente di denoising separato, chiamato Hierarchical EMA-Gated Recursive Denoising, trasferisce informazioni tra scale e passaggi temporali, decidendo quanto affidarsi alle nuove correzioni rispetto alle stime precedenti. Questo riduce il rischio che errori iniziali vengano amplificati man mano che il modello itera.
Allineare il quadro generale, non solo i singoli pixel
La maggior parte dei metodi esistenti addestra i modelli con funzioni di perdita che valutano ogni pixel singolarmente, come l'entropia incrociata o l'errore quadratico medio. Queste possono migliorare l'accuratezza locale ma possono comunque produrre previsioni statisticamente sbilanciate sull'intera immagine — per esempio sovrastimando le strade o sottostimando la vegetazione. Il contributo centrale di questo lavoro è un regolarizzatore a kernel di proiezione che misura quanto la distribuzione complessiva delle classi previste corrisponda a quella reale. Lo fa considerando le probabilità di classe di ogni pixel come un punto in uno spazio a dimensione elevata, proiettando quei punti in molte direzioni unidimensionali e confrontando come differiscono i due insiemi di proiezioni. Invece di campionare queste direzioni in modo casuale, gli autori ricavano una elegante formula in forma chiusa che aggrega efficacemente le differenze su tutte le direzioni, rendendo la misura sia stabile sia sensibile a spostamenti sottili.
Confini migliori e mappe più coerenti
Gli autori valutano il loro metodo su due noti benchmark urbani delle città tedesche di Vaihingen e Potsdam, che includono immagini ad altissima risoluzione e mappe di altezza insieme a etichette di verità a terra per superfici, edifici, vegetazione bassa, alberi, automobili e elementi vari. Su diverse misure di accuratezza standard, PKDiff supera una serie di forti modelli convoluzionali, basati su Transformer e altri modelli basati su diffusione. I miglioramenti sono particolarmente evidenti per le categorie in cui la geometria è cruciale, come edifici, vegetazione bassa e automobili di piccola dimensione: i confini sono più netti, gli oggetti meno frammentati e regioni ampie come le strade sono etichettate in modo più coerente. In termini semplici, fondendo con cura texture e altezza e imponendo inoltre che le previsioni appaiano corrette in aggregato, l'approccio proposto produce mappe più pulite e affidabili da dati aerei complessi.
Citazione: Tong, X., Yang, F., Yang, Q. et al. Projection Kernel regularization for diffusion-based multimodal remote sensing segmentation. Sci Rep 16, 14385 (2026). https://doi.org/10.1038/s41598-026-44603-4
Parole chiave: segmentazione telerilevamento, fusione multimodale, modelli di diffusione, mappatura urbana, immagini aeree