Clear Sky Science · pl
SAM2-ARAFNet: adaptacja SAM2 z uwzględnieniem uwagi w resztkowej sieci fuzji ASPP do semantycznej segmentacji obrazów lotniczych o wysokiej rozdzielczości
Bardziej precyzyjne spojrzenie na zmieniającą się planetę
Od śledzenia szkód po burzach po wspieranie planowania miejskiego — zdjęcia lotnicze i satelitarne stały się jednym z najpotężniejszych narzędzi ludzkości do rozumienia świata. Przekształcenie tych szczegółowych obrazów w czytelne mapy budynków, dróg, drzew i samochodów wciąż bywa zaskakująco trudne, zwłaszcza gdy komputery muszą działać szybko na dronach lub małych urządzeniach. W artykule przedstawiono SAM2-ARAFNet, nowy system mapowania, który opiera się na wydajnym modelu wizji i ostrożnie go upraszcza, dążąc do dostarczania bardzo dokładnych map pokrycia terenu z obrazów o wysokiej rozdzielczości przy znacznie niższym zapotrzebowaniu na moc obliczeniową niż wiodące obecnie metody.
Dlaczego mapowanie miast z lotu ptaka jest takie trudne
Zdjęcia lotnicze o wysokiej rozdzielczości rejestrują miasta z niezwykłą szczegółowością: widać pojedyncze domy, korony drzew, zaparkowane samochody, a nawet wąskie chodniki. Ta bogatość informacji rodzi jednak wyzwania. Powierzchnie należące do tej samej kategorii, na przykład różne rodzaje nawierzchni, mogą wyglądać bardzo różnie, podczas gdy odrębne klasy, takie jak niskie krzewy i korony drzew, mogą sprawiać wrażenie podobnych. Obrazy mogą być rozmyte, częściowo zasłonięte przez cienie lub chmury i różnić się między regionami. Tradycyjne podejścia oparte na regułach i wcześniejsze systemy uczenia maszynowego mają problem z radzeniem sobie z taką zmiennością, a nawet nowoczesne sieci głębokie często wymagają dużych zestawów oznakowanych danych i wydajnego sprzętu, co ogranicza ich użycie na satelitach, bezzałogowych statkach powietrznych i urządzeniach brzegowych.
Dostosowanie ogólnego modelu wizji do teledetekcji
Najnowsze „modele podstawowe” dla wizji, trenowane na ogromnych zbiorach codziennych zdjęć, wykazały imponującą zdolność do segmentowania niemal dowolnych obiektów na obrazie. Jednym z najsilniejszych jest Segment Anything Model 2 (SAM2), który potrafi wyznaczać kontury obiektów bez uprzedniego wskazywania, czym te obiekty są. Jednak SAM2 jest dostrojony do obrazów naturalnych i generuje regiony niezależne od klas, co czyni go mniej odpowiednim do zadań teledetekcyjnych, które muszą przypisać konkretną etykietę pokrycia terenu do każdego piksela. Autorzy zaprojektowali więc SAM2-ARAFNet, który utrzymuje zamrożony potężny enkoder SAM2 i dodaje lekkie moduły adaptera delikatnie dostosowujące jego wewnętrzne reprezentacje do specyfiki scen lotniczych. Dzięki temu unika się ponownego trenowania ogromnego rdzenia od podstaw, jednocześnie dopasowując go do domeny teledetekcji.
Widzieć wielki obraz i drobne szczegóły jednocześnie
Aby przekształcić zakodowane cechy w pełne mapy pokrycia terenu, SAM2-ARAFNet wykorzystuje specjalnie zaprojektowany dekoder, który łączy informacje na wielu skalach. Na niższych poziomach zachowuje ostre krawędzie i małe obiekty, łącząc wczesne mapy cech przez wielowątkowe gałęzie i moduł uwagi, który uwypukla informacyjne wzorce i tłumi szumy. Na wyższych poziomach wprowadza resztkowy moduł wzmocniony uwagą, który rozszerza swoje „pole recepcyjne” na coraz większe sąsiedztwa, pomagając sieci rozumieć szerszy kontekst, na przykład relacje między budynkami, drogami i roślinnością. Blok fuzji bilateralnej łączy więc niskopoziomowe detale z wysokopoziomowym znaczeniem, tak by na przykład kontury samochodów pozostawały ostre, a jednocześnie były poprawnie odróżniane od pobliskich dachów czy asfaltu.
Nauczyć mniejszą sieć naśladować większą
Choć pełny model SAM2-ARAFNet osiąga wysoką dokładność, jego rozmiar nadal utrudnia umieszczenie go na pokładzie platform. Aby temu zaradzić, autorzy trenują zwarty „student” zbudowany na bazie EfficientNet-b0, aby naśladował przewidywania dużego modelu „nauczyciela”. Zamiast kopiować tylko końcowe etykiety, student uczy się z bogatszych wzorców wyjściowych nauczyciela, przechwytując, jak różne klasy się ze sobą wiążą i jak piksele tej samej klasy zachowują się w scenie. Ten proces destylacji wiedzy zmniejsza liczbę parametrów o około 97 procent — z około 223 milionów do 6,7 miliona — przy jednoczesnym zachowaniu ponad 99 procent dokładności nauczyciela w ujęciu ogólnym. Efektem jest znacznie lżejszy model, który nadal generuje segmentacje wysokiej jakości odpowiednie dla dronów i innych platform brzegowych.
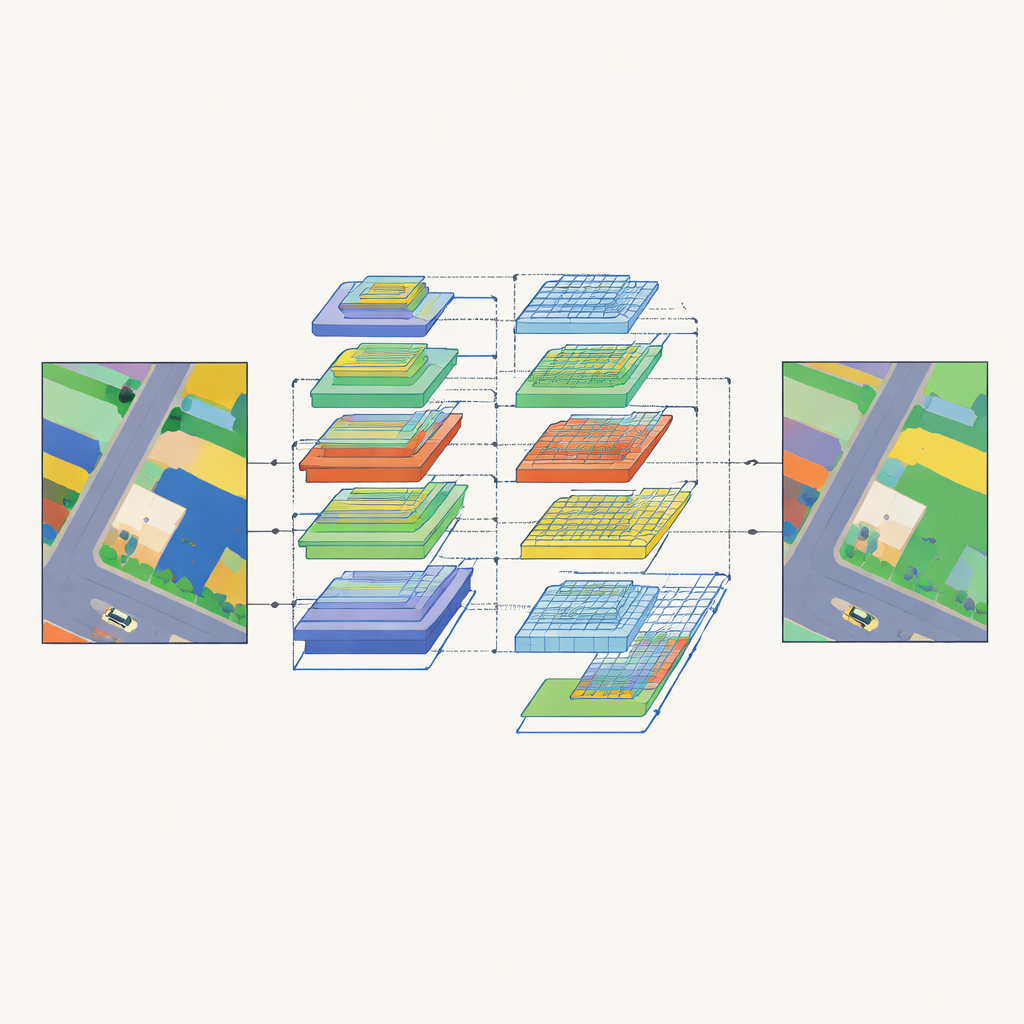
Jak dobrze działa w rzeczywistych miastach?
Zespół ocenił zarówno model nauczyciela, jak i studenta na dwóch szeroko stosowanych benchmarkach miejskich obrazów lotniczych: zestawach danych ISPRS Vaihingen i Potsdam. W porównaniu z szerokim zestawem silnych konkurentów opartych na sieciach splotowych, transformatorach i konstrukcjach hybrydowych, SAM2-ARAFNet osiąga konsekwentnie wyższe wyniki w standardowych miarach jakości segmentacji. Jest szczególnie skuteczny w radzeniu sobie z trudnymi sytuacjami, takimi jak pojazdy częściowo zasłonięte przez budynki czy subtelne przejścia między niską roślinnością, drzewami i zanieczyszczeniem wokół elewacji budynków. Porównania wizualne pokazują, że jego wyniki mają czyściejsze granice obiektów i mniej błędnie sklasyfikowanych fragmentów, podkreślając korzyści płynące z wieloskalowej uwagi i projektu fuzji.
Inteligentniejsze mapy dla świata o ograniczonych zasobach
Mówiąc prościej, praca ta pokazuje, jak potężny, lecz masywny model wizji można dostosować i odchudzić, aby tworzyć dokładne, wydajne mapy z obrazów lotniczych. Dzięki ponownemu użyciu silnego enkodera SAM2, starannemu projektowaniu modułów uwagi wieloskalowej i destylacji tej wiedzy do lekkiego studenta, SAM2-ARAFNet dostarcza szczegółowe miejskie mapy pokrycia terenu przy znacznie mniejszych kosztach obliczeniowych. To połączenie precyzji i efektywności czyni go obiecującym narzędziem do monitoringu środowiskowego, oceny szkód i zarządzania miastem bezpośrednio na satelitach, dronach lub innych urządzeniach, które nie mogą polegać na stałym połączeniu z chmurą.
Cytowanie: Shi, W., Ding, J., Lei, J. et al. SAM2-ARAFNet: adapting SAM2 with an attention-enhanced residual ASPP fusion network for high-resolution remote sensing semantic segmentation. Sci Rep 16, 10225 (2026). https://doi.org/10.1038/s41598-026-38047-z
Słowa kluczowe: teledetekcja, segmentacja semantyczna, obrazy satelitarne, uczenie głębokie, destylacja wiedzy