Clear Sky Science · fr
SAM2-ARAFNet : adaptation de SAM2 avec un réseau de fusion ASPP résiduel amélioré par attention pour la segmentation sémantique en télédétection haute résolution
Un regard plus net sur notre planète en mutation
Qu’il s’agisse de suivre les dégâts causés par les tempêtes ou d’orienter l’urbanisme, les images aériennes et satellitaires sont devenues l’un des outils les plus puissants pour comprendre le monde. Mais transformer ces images détaillées en cartes claires des bâtiments, routes, arbres et véhicules reste étonnamment difficile, surtout lorsque les ordinateurs doivent fonctionner rapidement sur des drones ou des appareils peu puissants. Cet article présente SAM2-ARAFNet, un nouveau système de cartographie qui s’appuie sur un modèle de vision performant et l’allège soigneusement, visant à produire des cartes d’occupation du sol très précises à partir d’images haute résolution tout en utilisant beaucoup moins de puissance de calcul que les méthodes leaders actuelles.
Pourquoi cartographier les villes depuis les airs est si difficile
Les photos aériennes haute résolution capturent les villes avec un niveau de détail remarquable : maisons individuelles, houppes d’arbres, voitures stationnées et même trottoirs étroits sont visibles. Mais cette richesse pose des défis. Des surfaces appartenant à la même catégorie, comme différents types de revêtement, peuvent paraître très différentes, tandis que des classes distinctes comme les buissons bas et les couronnes d’arbres peuvent sembler confondantes. Les images peuvent être floues, partiellement masquées par des ombres ou des nuages, et varier d’une région à l’autre. Les approches traditionnelles basées sur des règles et les premiers systèmes d’apprentissage automatique peinent à gérer cette variété, et même les réseaux profonds modernes nécessitent souvent de grands jeux de données annotés et du matériel puissant, limitant leur usage sur satellites, véhicules aériens sans pilote et dispositifs en périphérie.
Adapter un modèle de vision général à la télédétection
Les récents « modèles fondamentaux » pour la vision, entraînés sur d’immenses collections de photos du quotidien, montrent une capacité impressionnante à segmenter presque n’importe quel élément dans une image. L’un des plus puissants est Segment Anything Model 2 (SAM2), capable de dessiner des contours d’objets sans connaître au préalable la nature de ces objets. Cependant, SAM2 est optimisé pour des images naturelles et produit des régions agnostiques vis-à-vis des classes, ce qui le rend moins adapté aux tâches de télédétection qui exigent d’attribuer un label d’occupation du sol précis à chaque pixel. Les auteurs conçoivent donc SAM2-ARAFNet, qui laisse l’encodeur robuste de SAM2 gelé et ajoute des modules adaptateurs légers qui ajustent en douceur ses représentations internes pour correspondre à l’aspect particulier des scènes aériennes. Cela évite de réentraîner l’énorme backbone depuis zéro tout en l’adaptant au domaine de la télédétection.
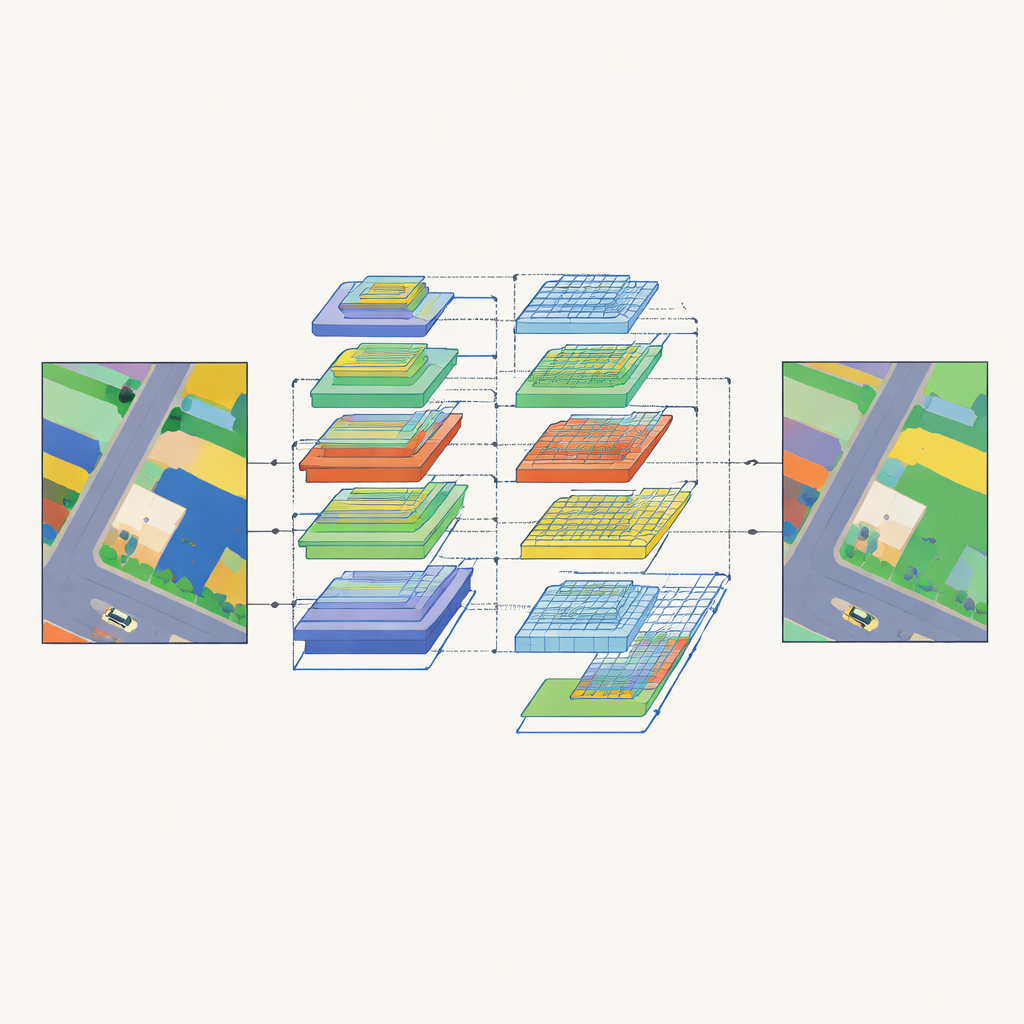
Voir la grande image et les fines détails en même temps
Pour transformer les caractéristiques encodées en cartes d’occupation du sol complètes, SAM2-ARAFNet utilise un décodeur spécialement conçu qui combine l’information à plusieurs échelles. Aux niveaux bas, il préserve les contours nets et les petits objets en fusionnant des cartes de caractéristiques précoces via plusieurs branches et un module d’attention qui met en valeur les motifs informatifs et supprime le bruit. Aux niveaux supérieurs, il introduit un module résiduel amélioré par attention qui étend son « champ réceptif » sur des voisinages de plus en plus larges, aidant le réseau à comprendre un contexte plus vaste — par exemple les relations entre bâtiments, routes et végétation. Un bloc de fusion bilatérale rapproche ensuite le détail de bas niveau et la sémantique de haut niveau de sorte que, par exemple, les contours de voitures restent nets tout en étant correctement distingués des toits ou de l’asphalte à proximité.
Apprendre à un réseau plus petit à imiter un réseau plus grand
Alors que le modèle complet SAM2-ARAFNet offre une grande précision, sa taille le rend encore lourd pour un déploiement embarqué. Pour remédier à cela, les auteurs entraînent un réseau « étudiant » compact, construit sur le backbone EfficientNet-b0, pour imiter les prédictions du grand modèle « enseignant ». Plutôt que de copier seulement les étiquettes finales, l’étudiant apprend à partir des schémas de sortie plus riches de l’enseignant, capturant la manière dont les classes se relient entre elles et le comportement des pixels appartenant à une même classe dans la scène. Ce processus de distillation de connaissances réduit le nombre de paramètres d’environ 97 % — d’environ 223 millions à 6,7 millions — tout en conservant plus de 99 % de la précision globale de l’enseignant. Le résultat est un modèle beaucoup plus léger qui produit néanmoins des segmentations de haute qualité, adaptées aux drones et autres plateformes en périphérie.
Quelle est son efficacité dans des villes réelles ?
L’équipe évalue les modèles enseignant et étudiant sur deux benchmarks largement utilisés d’imagerie aérienne urbaine : les jeux de données ISPRS Vaihingen et Potsdam. Par rapport à une large gamme de concurrents puissants basés sur des réseaux convolutionnels, des Transformers et des architectures hybrides, SAM2-ARAFNet obtient des scores systématiquement supérieurs selon les mesures standard de qualité de la segmentation. Il s’avère particulièrement efficace pour gérer des situations délicates, comme des véhicules partiellement masqués par des bâtiments, ou les transitions subtiles entre basse végétation, arbres et encombrements autour des façades. Les comparaisons visuelles montrent que ses sorties présentent des frontières d’objets plus nettes et moins de régions mal classées, soulignant les avantages de sa conception de fusion et d’attention multi‑échelle.
Des cartes plus intelligentes pour un monde aux ressources limitées
En termes pratiques, ce travail montre comment un modèle de vision puissant mais volumineux peut être adapté et allégé pour produire des cartes précises et efficaces à partir d’images aériennes. En réutilisant l’encodeur performant de SAM2, en concevant soigneusement des modules d’attention multi‑échelle, puis en distillant ce savoir dans un étudiant léger, SAM2-ARAFNet fournit des cartes d’occupation du sol urbaines détaillées avec un coût computationnel nettement réduit. Cet équilibre entre précision et efficacité en fait un outil prometteur pour la surveillance environnementale, l’évaluation des catastrophes et la gestion urbaine directement sur satellites, drones ou autres appareils incapables de dépendre d’une connexion cloud permanente.
Citation: Shi, W., Ding, J., Lei, J. et al. SAM2-ARAFNet: adapting SAM2 with an attention-enhanced residual ASPP fusion network for high-resolution remote sensing semantic segmentation. Sci Rep 16, 10225 (2026). https://doi.org/10.1038/s41598-026-38047-z
Mots-clés: télédétection, segmentation sémantique, imagerie satellite, apprentissage profond, distillation de connaissances