Clear Sky Science · fr
Comparaison et optimisation des méthodes de préférence des voisins cellulaires pour l’analyse quantitative des tissus
Pourquoi les voisins cellulaires comptent
Nos organismes sont constitués de quartiers animés de cellules, et non de dispersions aléatoires. Le fait que certaines cellules se trouvent à côté d’autres peut influencer la croissance d’une tumeur, la cicatrisation d’une plaie ou la récupération du cœur après un infarctus. Cet article pose une question apparemment simple : lorsque les scientifiques mesurent quels types cellulaires ont tendance à se côtoyer dans des images de tissus, quelle est la fiabilité des différentes méthodes employées, et peut-on faire mieux ?
Comment les scientifiques lisent la carte de la ville cellulaire
Les technologies modernes d’imagerie et de génomique spatiale permettent d’enregistrer la position exacte et l’identité de milliers de cellules dans une coupe de tissu. Une approche répandue pour analyser ces données consiste à calculer des « préférences de voisinage » : pour un type cellulaire A donné, à quelle fréquence a‑t‑il le type cellulaire B comme voisin proche par rapport à ce qui serait attendu par hasard ? De nombreux outils logiciels existent déjà pour cette tâche, mais ils reposent sur des étapes légèrement différentes. Les auteurs décomposent ces étapes en trois choix fondamentaux : comment définir le voisinage autour de chaque cellule (par exemple en reliant par des arêtes les cellules proches ou en utilisant une distance fixe), comment compter les voisins (traiter la paire A–B de la même façon que B–A, ou distinguer la direction de A vers B et de B vers A), et comment convertir ces décomptes en un score final (comptes normalisés simples, statistiques basées sur permutations ou mesures issues de l’apprentissage automatique). Ce cadre commun permet une comparaison équitable, côte à côte, des méthodes.
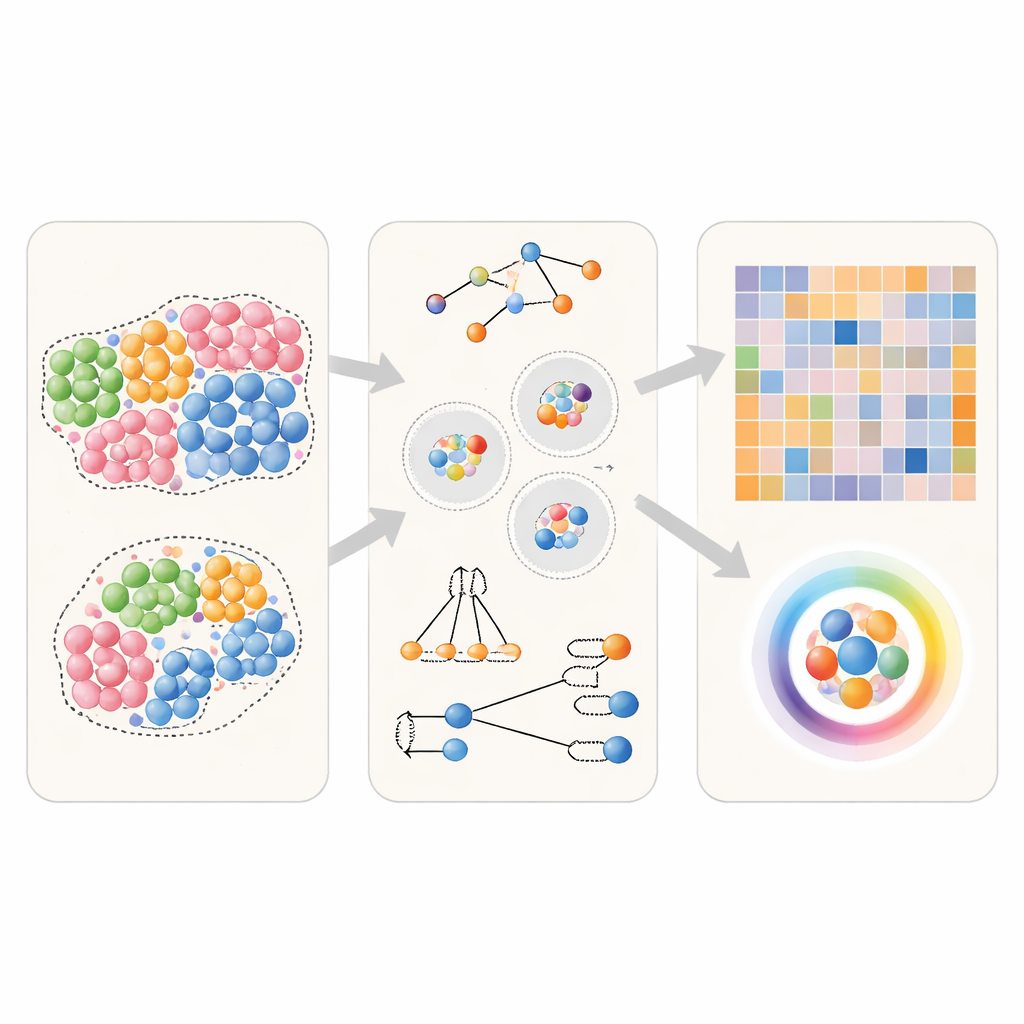
Tester les méthodes de voisinage dans des tissus virtuels
Pour évaluer la performance des différentes approches, l’équipe a d’abord utilisé des tissus générés par ordinateur où les véritables relations de voisinage sont connues à l’avance. Ils ont créé des scénarios simples dans lesquels un type cellulaire particulier n’a pas de préférence spéciale, préfère légèrement ses semblables, ou forme fortement des agrégats avec lui‑même. Ils ont aussi simulé des situations directionnelles où un type cellulaire se serre préférentiellement contre un autre, mais pas dans l’autre sens. En utilisant ces tissus virtuels, les auteurs ont fourni des données identiques à plusieurs outils largement utilisés et se sont ensuite demandé : chaque méthode peut‑elle distinguer de manière fiable ces scénarios, et peut‑elle correctement retrouver quel type cellulaire recherche quel voisin ?
Pourquoi la direction et la subtilité sont difficiles à capter
La comparaison a révélé que presque toutes les méthodes détectent des différences importantes et évidentes dans l’organisation tissulaire. Cependant, deux faiblesses clés sont apparues. D’une part, certains outils compressent leur sortie en scores grossiers à trois niveaux (par exemple « en dessous du hasard », « pas de différence » ou « au‑dessus du hasard »), ce qui rend difficile la distinction entre une faible préférence de voisinage et une préférence forte. D’autre part, beaucoup de méthodes moyennent les comptes de voisins sur toutes les cellules d’un type donné, indépendamment du fait qu’une cellule particulière rencontre ou non l’autre type. Cette « moyenne totale » a tendance à estomper la directionnalité, faisant apparaître la relation de A vers B similaire à celle de B vers A, même lorsqu’une seule direction montre réellement une préférence. En conséquence, les outils existants peuvent sous‑estimer ou même inverser la direction apparente de l’infiltration cellulaire, en particulier lorsqu’un type cellulaire est rare et l’autre abondant.
Une nouvelle façon de scorer les voisins directionnels
Pour remédier à ces problèmes, les auteurs présentent un nouveau schéma de notation appelé score z conditionnel, ou COZI. COZI conserve l’idée de comparer les décomptes observés de voisins à de nombreuses versions aléatoires du tissu, mais modifie la manière dont les comptes sont moyennés : il ne prend en compte que les cellules de type A qui touchent effectivement au moins une cellule de type B. Cet accent « conditionnel » s’avère crucial pour retrouver la directionnalité. COZI convertit ensuite le résultat en un z‑score continu, qui reflète à quel point le motif observé dévie de l’attente aléatoire. Pour faciliter l’interprétation des scores, les auteurs ajoutent une mesure complémentaire, le ratio cellulaire conditionnel (CCR), qui indique simplement quelle fraction des cellules de type A participe au moins une fois au voisinage A–B. Ensemble, le z‑score et le CCR révèlent non seulement la force d’une relation spatiale, mais aussi si elle est portée par quelques cellules spécialisées ou par un changement large dans l’organisation du tissu.
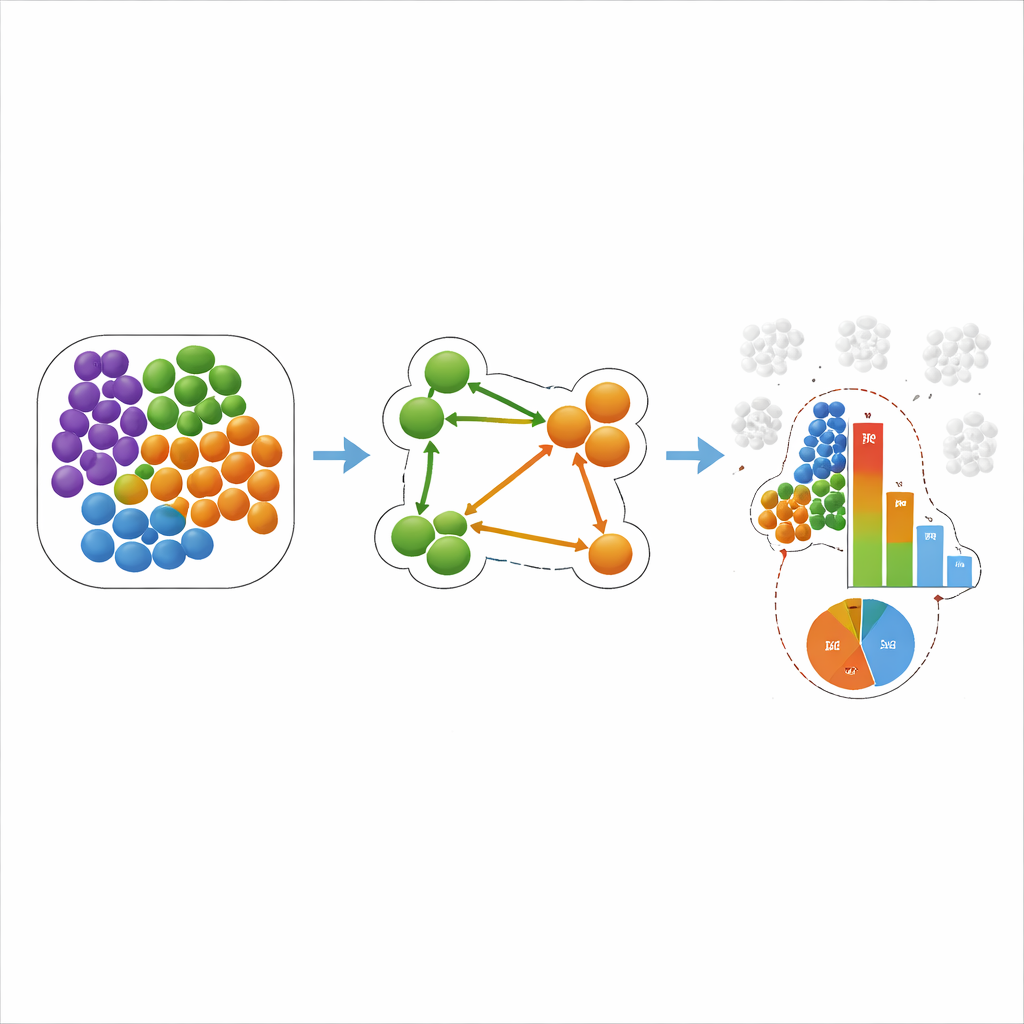
Ce que cela signifie pour le cancer et les maladies cardiaques
L’équipe a ensuite appliqué COZI et d’autres méthodes à deux jeux de données réels. Dans une étude sur le cancer du sein triple‑négatif, des travaux antérieurs avaient regroupé les tumeurs en « froides », « mixtes » et « compartimentalisées » en fonction de la façon dont les cellules immunitaires et tumorales s’emmêlaient. COZI a non seulement reproduit ces regroupements, mais a aussi mis au jour des motifs directionnels : par exemple, dans certaines tumeurs, les cellules immunitaires avaient tendance à se regrouper entre elles tandis qu’un sous‑ensemble de cellules tumorales s’immisçait dans ces poches, alors que dans d’autres, ce sont les cellules immunitaires qui infiltraient les régions tumorales. Dans un modèle murin d’infarctus du myocarde, COZI a suivi comment les neutrophiles et les monocytes entraient progressivement dans le muscle cardiaque endommagé, d’abord par la paroi interne du ventricule puis plus profondément dans la zone lésée. De façon importante, il a dissocié les variations globales du nombre de cellules des véritables changements de qui côtoie qui et dans quelle direction.
Message à retenir
Cette étude montre que tous les outils d’analyse des voisinages cellulaires ne se valent pas, et que de petits choix algorithmiques peuvent fortement orienter les conclusions biologiques. En clarifiant le fonctionnement des méthodes existantes et en introduisant COZI ainsi que le ratio cellulaire conditionnel, les auteurs fournissent une feuille de route pour choisir et interpréter les analyses de voisinage dans les données tissulaires spatiales. Pour les non‑spécialistes, l’idée clé est que comprendre qui vit à côté de qui dans la « ville » tissulaire — et qui empiète sur le territoire de qui — peut révéler des signes précoces de maladie, des réponses au traitement et des voies pour des thérapies ciblées, à condition que ces motifs soient mesurés avec les bons outils.
Citation: Schiller, C., Ibarra-Arellano, M.A., Bestak, K. et al. Comparison and optimization of cellular neighbor preference methods for quantitative tissue analysis. Nat Commun 17, 3514 (2026). https://doi.org/10.1038/s41467-026-71699-z
Mots-clés: omiques spatiales, voisinages cellulaires, microenvironnement tumoral, infiltration des cellules immunitaires, pathologie computationnelle