Clear Sky Science · de
Zielgerichtete Long-Read-Sequenzierung für hochauflösende Repeat-Profilierung bei Myotone Dystrophie Typ 1
Warum das für Familien und Ärztinnen/Ärzte wichtig ist
Manche vererbten Erkrankungen werden durch stotternde Abschnitte in unserer DNA verursacht—kurze Sequenzen, die hunderte oder sogar tausende Male wiederholt vorkommen. Wenn diese Repeats zu lang werden, können sie ernste Krankheiten wie die myotone Dystrophie hervorrufen, eine Erkrankung mit Muskelschwund. Trotzdem ist es mit den heute üblichen Kliniktests überraschend schwierig, die genaue Länge dieser Wiederholungen und ihre chemische Markierung zu bestimmen. Dieses Paper stellt eine schlanke Methode vor, solche schwer lesbaren DNA-Regionen innerhalb eines Tages detailliert auszulesen, was Ärzten klarere Antworten und Patientinnen und Patienten bessere Orientierung geben könnte.
Ein genauerer Blick auf eine schwierige Muskelkrankheit
Die Myotone Dystrophie Typ 1 (DM1) wird durch eine übermäßig verlängerte Abfolge von drei DNA-Bausteinen in einem Gen verursacht, das für Muskel- und andere Gewebe wichtig ist. Menschen mit mehr Wiederholungen haben tendenziell schwerere Verläufe, daher ist die genaue Bestimmung der Repeat-Länge entscheidend für Diagnose und Prognose. Standardtools in klinischen Laboren—etwa spezielle PCR-Tests und Southern Blots—funktionieren gut bei moderater Repeat-Größe, versagen jedoch häufig oder werden sehr ungenau, sobald Expansionen einige hundert Kopien überschreiten. Das hinterlässt eine Grauzone, in der Familien wissen können, dass eine Mutation vorliegt, aber kein klares Bild davon haben, wie ausgedehnt sie ist oder wie sie sich über die Zeit verändern könnte.
Kombination aus molekularen Scheren und Long-Read-DNA-Lesung
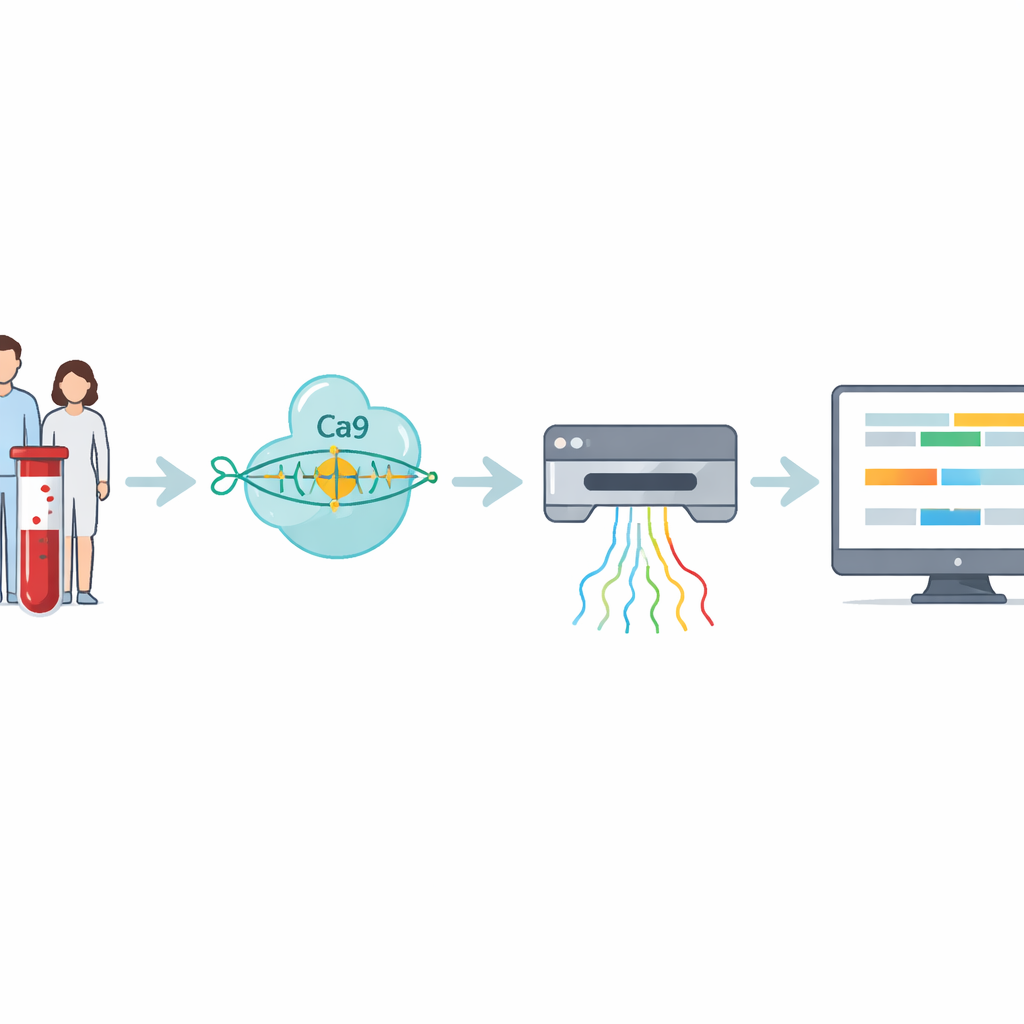
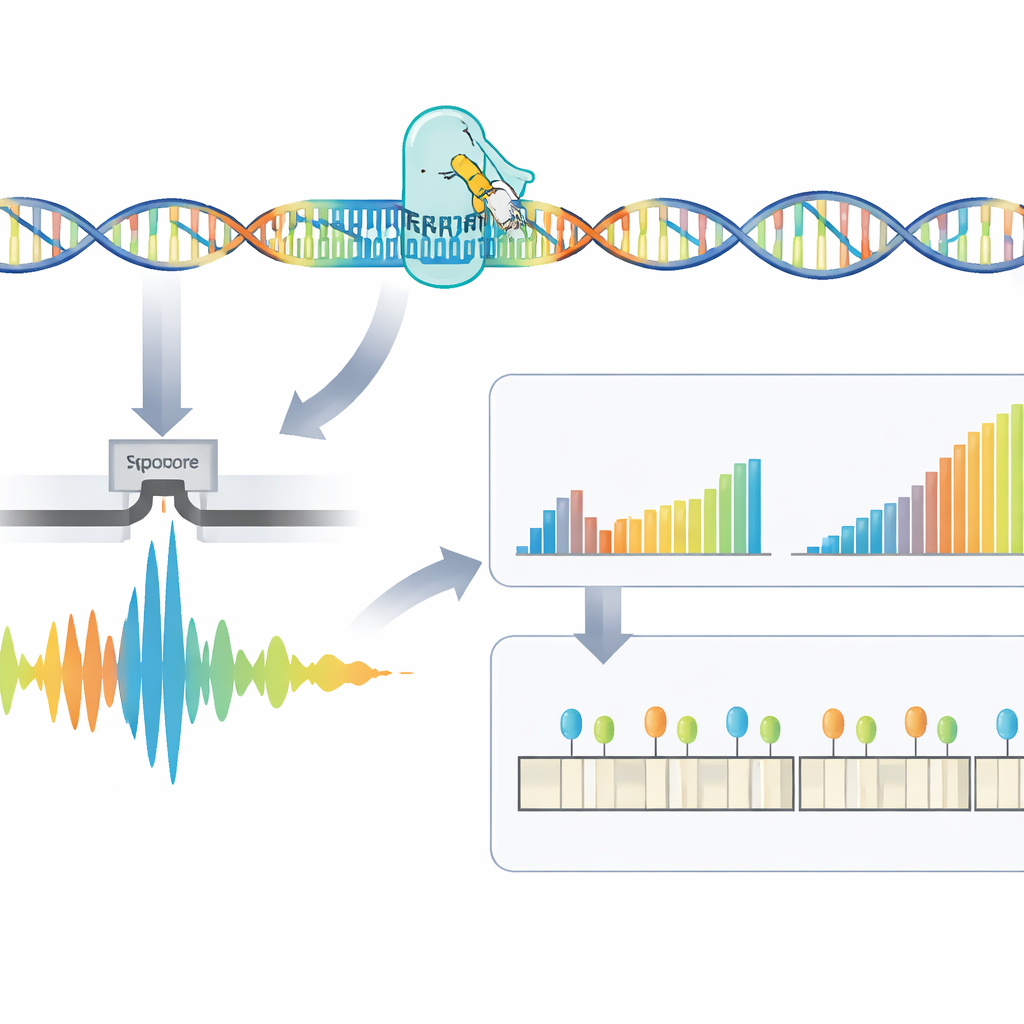
Die Forschenden entwickelten einen vierstufigen Workflow, der diese schwer lesbaren Repeats direkt angeht. Zuerst wird DNA aus Blut- oder Zellproben extrahiert. Dann setzt das Team CRISPR–Cas9 ein—molekulare Scheren, die zu einer bestimmten Adresse im Genom geführt werden—um das Stück rund um die Repeat-Region auszuschneiden. Weil nur diese ausgeschnittenen Fragmente für die Sequenzierung vorbereitet werden, reichert die Methode gezielt die Zielregion an und vermeidet die PCR-Amplifikation, die sehr große Expansionen häufig überspringt. Die vorbereitete DNA wird anschließend in einen Nanopore-Sequenzer eingespeist, ein handliches Gerät, das DNA-Stränge durch winzige Poren zieht und ihre Zusammensetzung in Echtzeit über elektrische Signale erkennt.
Intelligente Software zum Ablesen von Länge und chemischen Markierungen
Die Rohsignale des Sequenzierers müssen erst in DNA-Code und dann in aussagekräftige Messwerte übersetzt werden. Hier stellen die Autorinnen und Autoren RepeatLab vor, eine automatisierte Analyse-Pipeline, die sogar auf einem gewöhnlichen Cloud-Notebook betrieben werden kann. RepeatLab führt zunächst einen schnellen Durchlauf durch, um Reads zu finden, die das angestrebte Gen abdecken, und verarbeitet diese Reads dann mit einer anspruchsvolleren, hochpräzisen Einstellung, die auf lange, repetitive Abschnitte zugeschnitten ist. Es verwendet eine angepasste statistische Strategie, um Einzelmolekül-Messungen in der Regel in zwei Gruppen zu clustern—typischerweise die normale und die expandierte Kopie des Gens bei jeder Person—und erreicht zuverlässige Längenabschätzungen bereits mit etwa einem Dutzend Reads. Dasselbe Framework kann viele Proben oder mehrere Gene in einem Lauf analysieren und hält die Kosten damit in etwa auf dem Niveau vorhandener klinischer Tests.
Blick auf Unterbrechungen und epigenetische Signale
Über das bloße Zählen von Repeats hinaus untersucht die Methode die feine Struktur der wiederholten Region und ihre chemische Ausstattung. Manche Patientinnen und Patienten tragen Unterbrechungen—kleine Abschnitte mit abweichender Sequenz innerhalb des Repeats—die mit milderen Verläufen verbunden sein können. Das Team fand, dass viele scheinbare Unterbrechungen tatsächlich Artefakte der Rohsignalverarbeitung waren, und zeigte, dass die Verwendung größerer Analysefenster beim Decodieren diese falsch-positiven Befunde deutlich reduzierte. RepeatLab verfügt zudem über einen Spezialmodus zur Bestimmung von DNA-Methylierung, einer chemischen Markierung, die Gene an- oder ausschalten kann. Rund um das DM1-Gen kartierten die Autorinnen und Autoren Methylierungsmuster auf Einzelallel-Ebene und identifizierten mehrere Schlüsselzonen, in denen stärkere Methylierung mit längeren Repeat-Expansionen korreliert—was die Vorstellung stützt, dass diese chemischen Markierungen die Krankheitsentwicklung beeinflussen.
Ein schnellerer, aussagekräftigerer Test für schwer zu messende Repeats
In der Summe zeigt diese Arbeit, dass CRISPR-geführte Anreicherung, Nanopore-Long-Read-Sequenzierung und benutzerfreundliche Software ein detailliertes Profil krankheitsverursachender DNA-Repeats in unter 24 Stunden liefern können. Für DM1 und verwandte Erkrankungen misst der Ansatz nicht nur die Repeat-Länge, sondern erfasst auch subtile Sequenzvarianten und epigenetische Muster, die von heutigen Kliniktests weitgehend übersehen werden. Obwohl weitere Validierungen und Anpassungen an neue Sequenzierchemien noch nötig sind, weist diese integrierte Plattform den Weg zu genetischen Tests der Zukunft, die schneller, informativer und leichter in der Routineanwendung einzusetzen sind.
Zitation: Han, Y., Jang, JH. & Chang, H. Targeted long-read sequencing for high-resolution repeat profiling in myotonic dystrophy type 1. Exp Mol Med 58, 1203–1215 (2026). https://doi.org/10.1038/s12276-026-01683-6
Schlüsselwörter: myotone Dystrophie, Tandem-Repeat-Expansion, Nanopore-Sequenzierung, CRISPR-Cas9-Anreicherung, DNA-Methylierung