Clear Sky Science · zh
将视觉-语言模型用于高能物理中的中微子事件分类
为什么微小粒子与智能机器很重要
中微子是如幽灵般的粒子,不断穿过宇宙且极少与物质相互作用,但它们蕴含着关于物质与宇宙演化的线索。现代中微子实验使用巨大的探测器,将这些罕见碰撞记录为精细图像,产生的数据量远超人力可逐一审阅。本研究探讨了一种新型人工智能——视觉语言模型,如何帮助科学家更准确且以更贴近人类的方式对这些事件进行分类和理解。
把粒子轨迹变成图片
当中微子撞击液氩探测器内的原子时,会留下带电粒子的轨迹,有点像飞机在天空中留下的凝结尾迹。探测器将这些轨迹从不同视角转换为详细的黑白图像。研究人员构建了一个逼真的模拟数据集,包含不同类型中微子相互作用的图像,以及一个中微子类型无法被清晰识别的背景类别。这些图像构成了教计算机区分不同相互作用类型的原始材料,这是研究中微子在传播过程中如何发生味道转换的关键步骤。
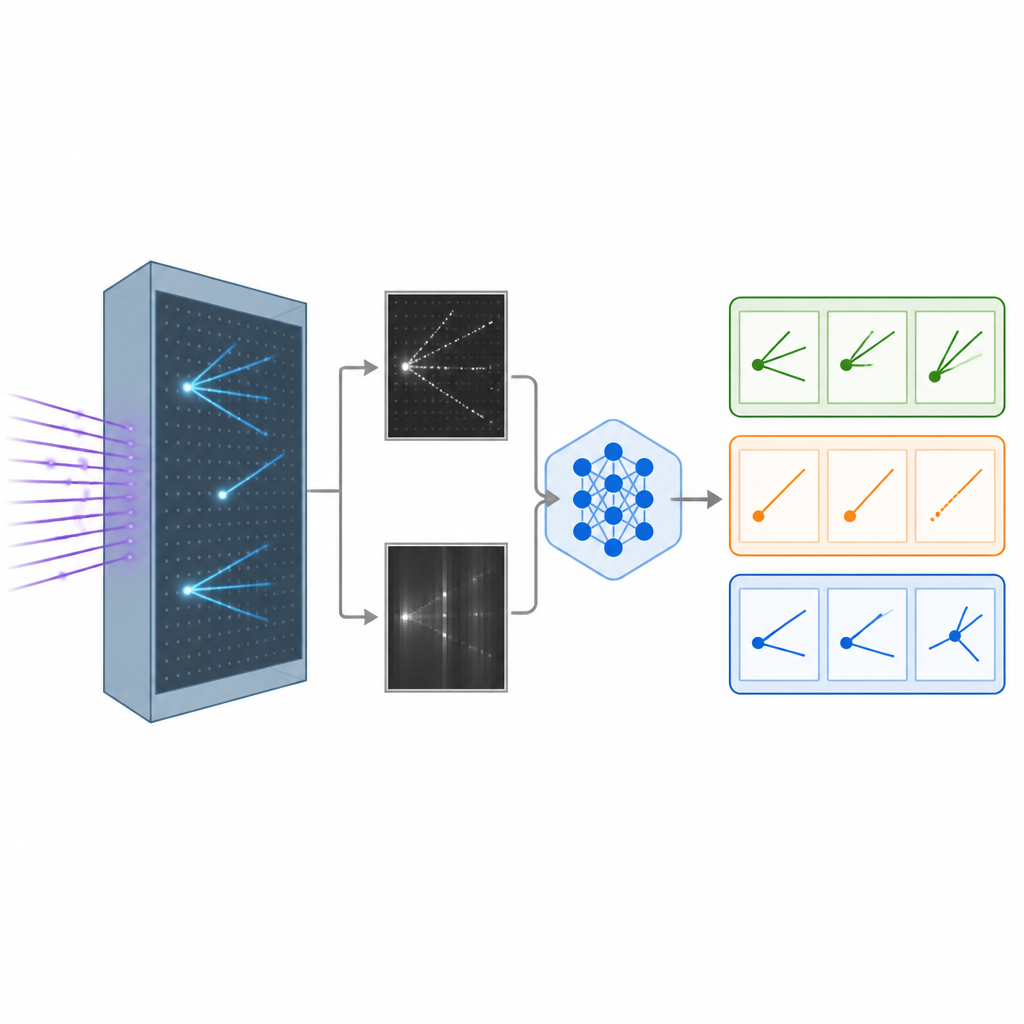
赋予人工智能视觉与文字
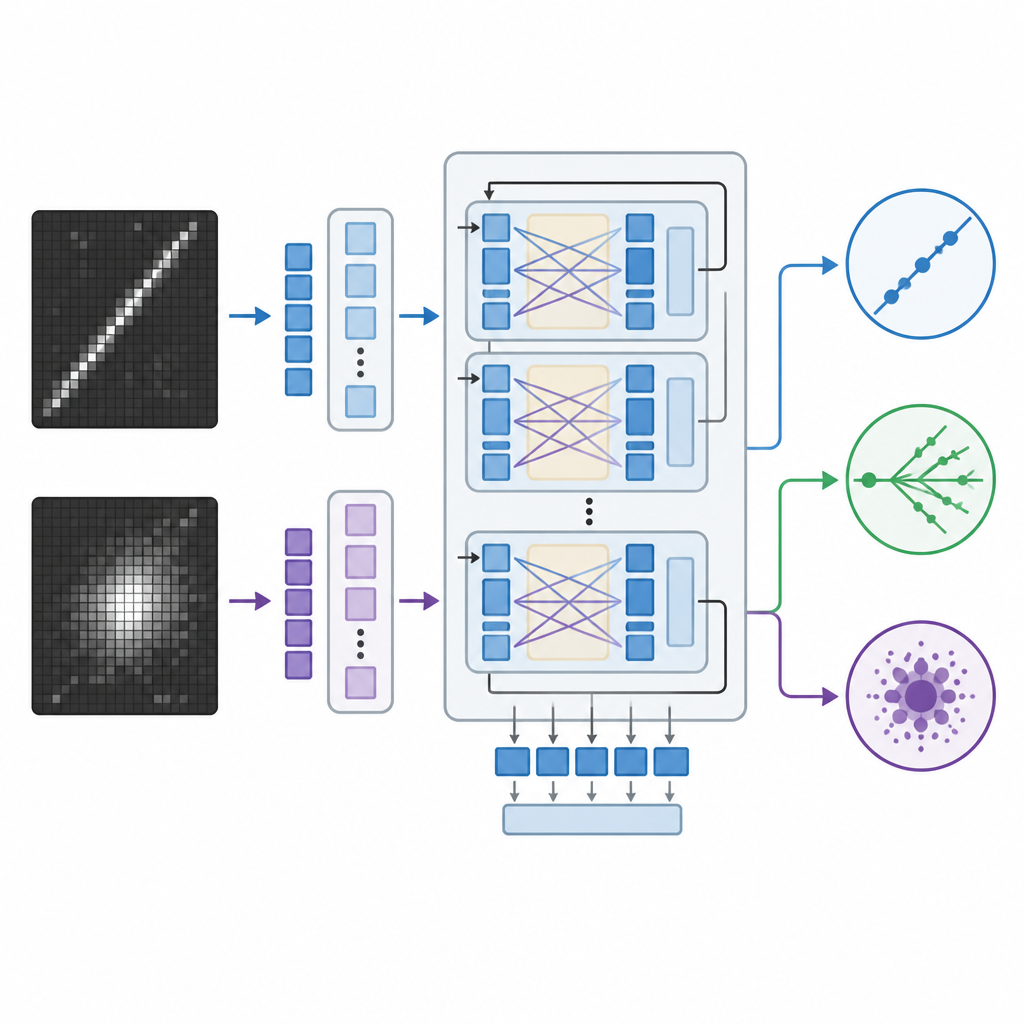
物理学中传统的图像识别系统依赖卷积神经网络或较新的视觉变换器,这些方法强大但常像黑箱一样只输出数字而缺乏解释性。研究团队转而改造了最初由 Meta 开发的一种大型视觉语言模型,该模型能够同时处理图像和文本并生成书面回答。他们使用一种高效的方法对模型进行了微调,仅调整了其数十亿内部参数中的一小部分。在训练过程中,模型看到成对的探测器图像以及关于哪些模式代表各类相互作用的提示,例如细长轨迹或模糊簇射,并学会将每次事件归入三类之一。
模型如何接受测试
为评估这种方法的效果,研究人员将视觉语言模型与两种强有力的替代方案进行了比较:一个定制的卷积网络和一个仅处理图像的大型视觉变换器。所有三种模型都在相同的模拟探测器数据上训练,然后在从未见过的保留事件上进行评估。团队测量了准确率及相关统计指标,对于视觉语言模型,还从其对三类的内部概率中推导出置信度分数。他们进一步通过降低图像分辨率(模拟通道更少或数据被压缩的探测器)来挑战模型,并检查在提示信息不那么详细时系统行为是否仍然合理。
模型揭示了什么
视觉语言模型在正确分类事件方面与视觉变换器不相上下或略有超越,并明显优于卷积网络,尽管在训练时它只更新了极少的参数。两个基于变换器的系统在图像下采样到较低分辨率时仍表现稳健,而卷积模型的性能则急剧下降。视觉语言模型的一个显著优势是它还能生成与事件图像中可见特征相关的自然语言解释,例如指出一条看起来像μ子的长而直的轨迹,或在中性流相互作用中此类轨迹的缺失。尽管这些解释并不能真正揭示模型的内部机理,但它们比单纯的数字或热图更直观地为物理学家展示了决策理由。
面向物理学与人工智能的未来
研究结论认为,经过慎重改造的大型视觉语言模型可以作为中微子实验的多功能工具,将强大的分类能力与可解释的基于文本的描述相结合。它们比更简单的网络计算要求更高,因此在实时或资源受限的任务中仍会优先使用轻量模型。然而,对于需要理解与信任的离线分析,这些多模态模型为构建可复用的“基础”系统提供了有希望的路径,能够以相对较少的额外工作对新探测器和新数据进行微调。通过这种方式,粒子物理学与先进人工智能的合作可以帮助科学家更清晰、更有信心地读取中微子微弱的信号特征。
引用: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
关键词: 中微子分类, 视觉语言模型, 液氩探测器, 高能物理, 物理学中的机器学习