Clear Sky Science · it
Adattare modelli visione-linguaggio per la classificazione di eventi di neutrini nella fisica delle alte energie
Perché particelle minuscole e macchine intelligenti contano
I neutrini sono particelle evanescenti che attraversano l’universo e interagiscono raramente con la materia, ma custodiscono indizi sull’evoluzione della materia e del cosmo. Gli esperimenti moderni sui neutrini usano rivelatori giganteschi che registrano queste collisioni rare come immagini a grana fine, generando più dati di quelli che gli esseri umani possono analizzare da soli. Questo studio esplora come una nuova categoria di intelligenza artificiale, detta modello visione-linguaggio, possa aiutare gli scienziati a ordinare e comprendere questi eventi in modo più accurato e più comprensibile.
Trasformare le tracce delle particelle in immagini
Quando un neutrino colpisce atomi all’interno di un rivelatore a argon liquido, lascia dietro di sé scie di particelle cariche, un po’ come le scie di condensazione degli aerei nel cielo. Il rivelatore converte queste scie in immagini in bianco e nero dettagliate viste da diverse angolazioni. I ricercatori hanno costruito un dataset simulato realistico di tali immagini, rappresentando interazioni di diversi tipi di neutrini, oltre a una classe di fondo in cui il tipo di neutrino non è identificabile con chiarezza. Queste immagini costituiscono il materiale grezzo per insegnare ai computer a distinguere un tipo di interazione dall’altro, un passaggio chiave per studiare come i neutrini cambiano sapore mentre viaggiano.
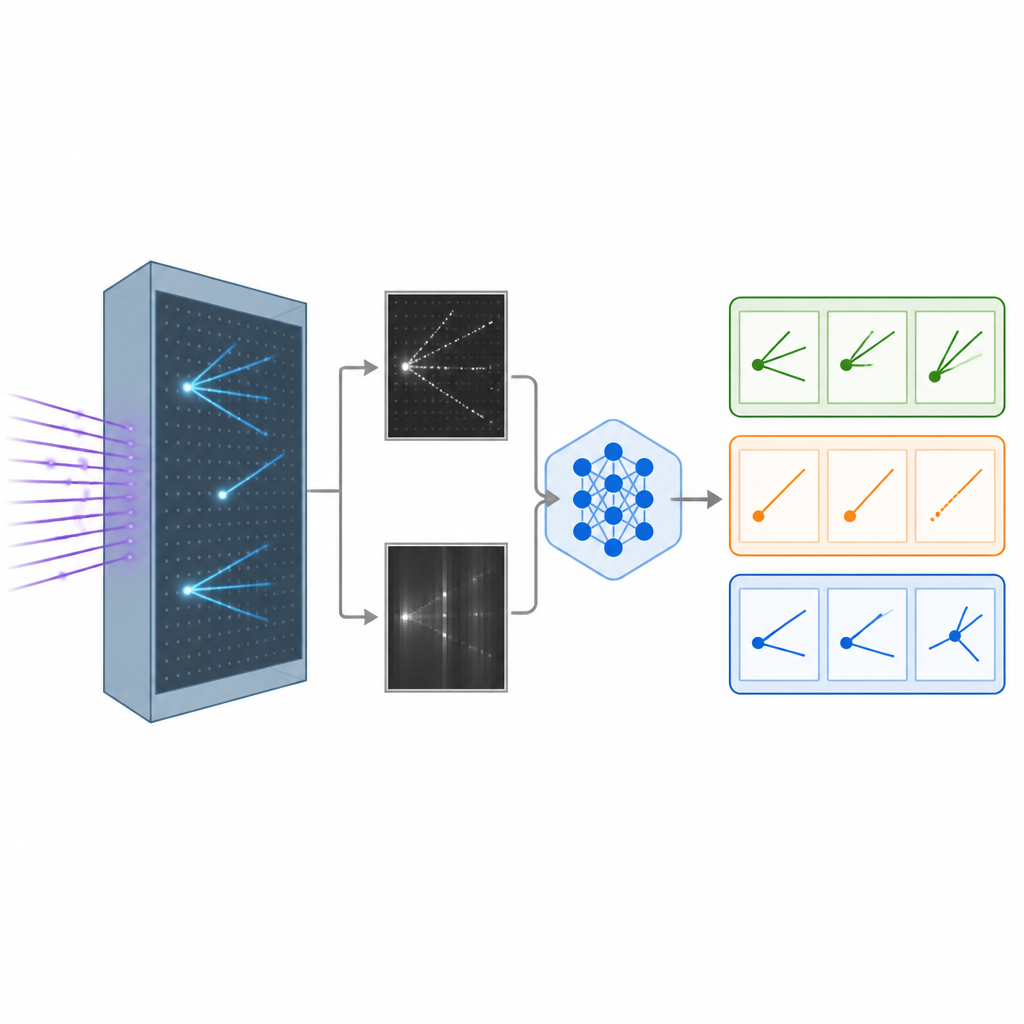
Dare all’IA occhi e parole
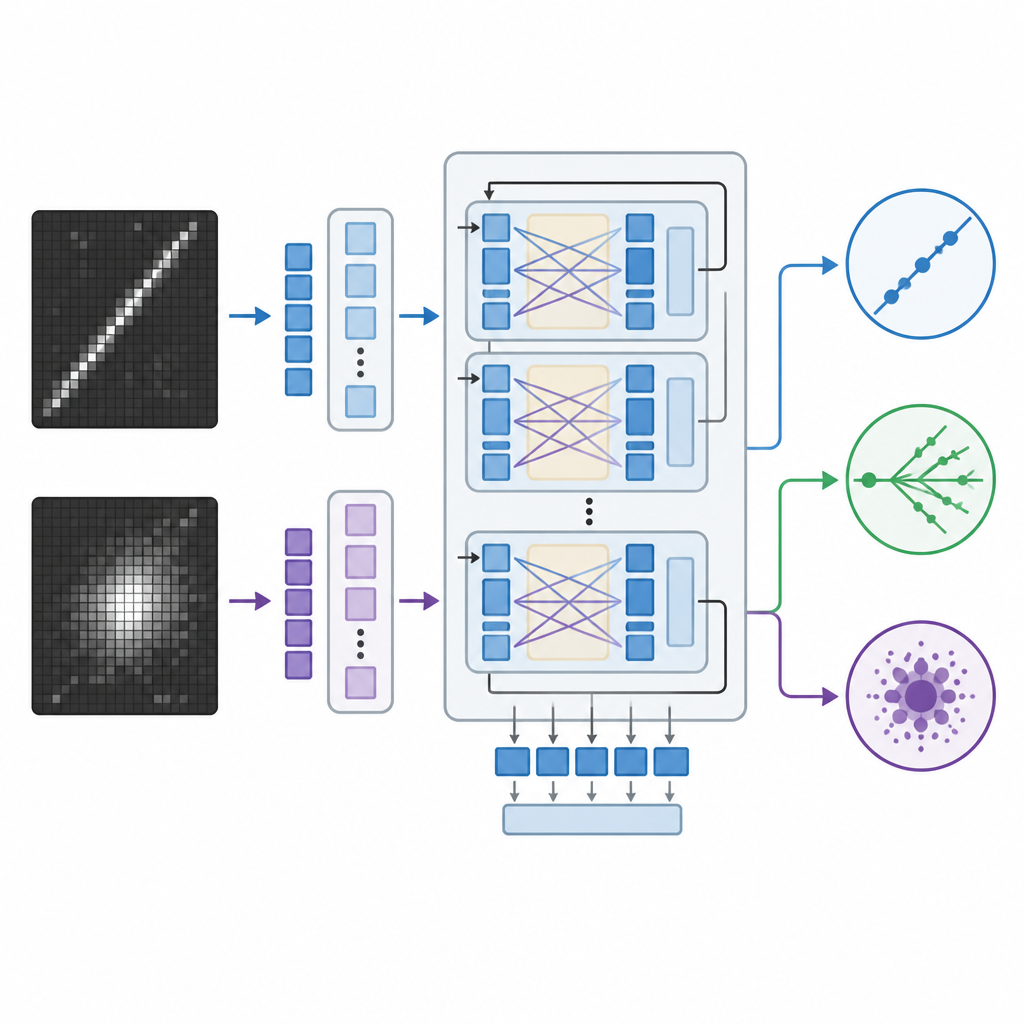
I sistemi tradizionali di riconoscimento delle immagini in fisica si basano su reti neurali convoluzionali o sui più recenti vision transformer, potenti ma spesso scatole nere che restituiscono numeri senza spiegazioni. Il gruppo ha invece adattato un grande modello visione-linguaggio originariamente sviluppato da Meta, capace di elaborare immagini e testo insieme e di generare risposte scritte. Hanno messo a punto (fine-tuned) questo modello sulle immagini dei neutrini usando un metodo efficiente che modifica solo una piccola parte dei suoi miliardi di parametri interni. Durante l’addestramento il modello ha visto coppie di immagini del rivelatore insieme a indicazioni su quali pattern caratterizzano ogni tipo di interazione, come tracce lunghe e sottili o sciami diffusi, e ha imparato ad assegnare ogni evento a una delle tre categorie.
Come è stato testato il modello
Per valutare l’efficacia di questo approccio, i ricercatori hanno confrontato il modello visione-linguaggio con due alternative solide: una rete convoluzionale costruita ad hoc e un grande vision transformer che considera solo le immagini. Tut e tre i modelli sono stati addestrati sugli stessi dati simulati del rivelatore e poi valutati su eventi tenuti fuori dal training che non avevano mai visto. Il team ha misurato l’accuratezza e statistiche correlate, e per il modello visione-linguaggio ha anche ricavato punteggi di confidenza dalle sue probabilità interne sulle tre classi. Hanno ulteriormente messo alla prova i modelli degradando la risoluzione delle immagini, emulando rivelatori con meno canali di lettura o dati compressi, e verificando se il sistema si comportava ancora in modo sensato quando riceveva prompt meno dettagliati.
Cosa hanno rivelato i modelli
Il modello visione-linguaggio ha eguagliato o leggermente superato il vision transformer nella classificazione corretta degli eventi e ha chiaramente sovraperformato la rete convoluzionale, nonostante abbia aggiornato molti meno parametri durante l’addestramento. Entrambi i sistemi basati su transformer sono rimasti robusti anche quando le immagini sono state sottocampionate a bassa risoluzione, mentre le prestazioni del modello convoluzionale sono diminuite bruscamente. Un vantaggio distintivo del modello visione-linguaggio è la capacità di generare spiegazioni in linguaggio naturale legate a caratteristiche visibili nelle immagini dell’evento, come evidenziare una traccia lunga e diritta che assomiglia a un muone o l’assenza di una tale traccia in eventi di corrente neutra. Pur non rivelando letteralmente i meccanismi interni del modello, queste spiegazioni offrono ai fisici una finestra più intuitiva sul perché sia stata presa una decisione rispetto ai soli numeri o alle mappe di calore.
Prospettive per la fisica e l’IA
Lo studio conclude che i grandi modelli visione-linguaggio, se adattati con cura, possono fungere da strumenti versatili per gli esperimenti sui neutrini, combinando una forte capacità di classificazione con descrizioni interpretabili in forma testuale. Sono più esigenti dal punto di vista computazionale rispetto a reti più semplici, quindi modelli più leggeri rimarranno preferibili per compiti in tempo reale o con risorse limitate. Tuttavia, per analisi offline dove comprensione e fiducia sono cruciali, questi modelli multimodali offrono un modo promettente per costruire sistemi “fondamenta” riutilizzabili che possono essere riadattati a nuovi rivelatori e dati con relativamente poco lavoro aggiuntivo. In questo modo, la collaborazione tra fisica delle particelle e IA avanzata potrebbe aiutare gli scienziati a leggere le deboli firme dei neutrini in modo più chiaro e con maggiore fiducia.
Citazione: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Parole chiave: classificazione dei neutrini, modello visione-linguaggio, rivelatore a argon liquido, fisica delle alte energie, apprendimento automatico in fisica