Clear Sky Science · de
Anpassung von Vision-Language-Modellen zur Klassifizierung von Neutrino-Ereignissen in der Hochenergiephysik
Warum winzige Teilchen und kluge Maschinen wichtig sind
Neutrinos sind geisterhafte Teilchen, die das Universum durchdringen und nur selten mit Materie wechselwirken, aber dennoch Hinweise darauf liefern, wie sich Materie und Kosmos entwickelt haben. Moderne Neutrino-Experimente nutzen riesige Detektoren, die diese seltenen Kollisionen als fein aufgelöste Bilder festhalten und dabei mehr Daten erzeugen, als Menschen allein durchsehen können. Diese Studie untersucht, wie eine neue Art künstlicher Intelligenz, ein sogenanntes Vision-Language-Modell, Wissenschaftlern helfen kann, diese Ereignisse genauer und auf eine für Menschen zugänglichere Weise zu sortieren und zu verstehen.
Teilchenspuren in Bilder verwandeln
Wenn ein Neutrino Atome in einem Flüssig-Argon-Detektor trifft, hinterlässt es Spuren geladener Teilchen, ein wenig wie Kondensstreifen von Flugzeugen am Himmel. Der Detektor wandelt diese Spuren in detaillierte Schwarz-Weiß-Bilder aus verschiedenen Blickwinkeln um. Die Forscher erstellten einen realistischen simulierten Datensatz solcher Bilder, der Wechselwirkungen verschiedener Neutrino-Typen sowie eine Hintergrundklasse enthält, in der sich der Neutrinotyp nicht sauber bestimmen lässt. Diese Bilder bilden das Rohmaterial, mit dem Computer darin trainiert werden, eine Interaktionsart von einer anderen zu unterscheiden — ein zentraler Schritt, um zu untersuchen, wie sich Neutrinos auf ihrer Reise entwickeln.
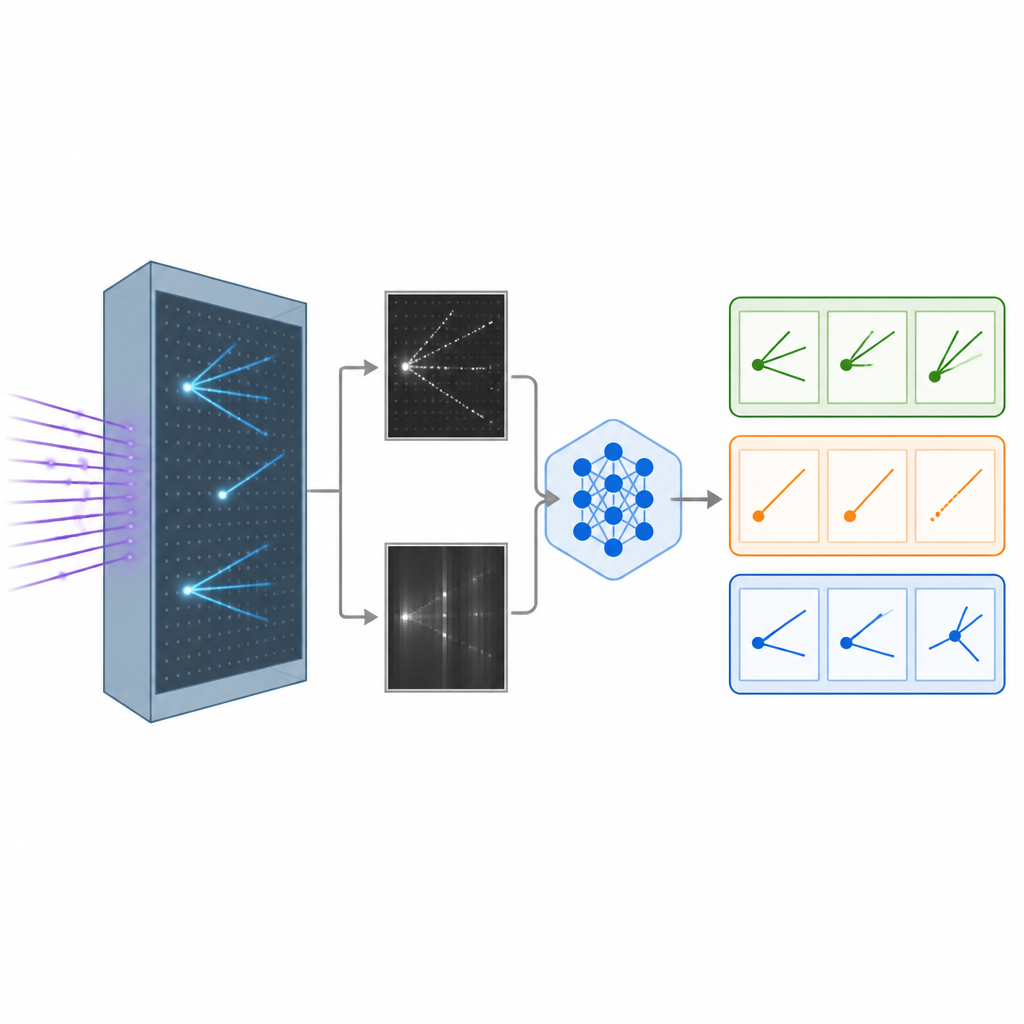
Der KI sowohl Augen als auch Worte geben
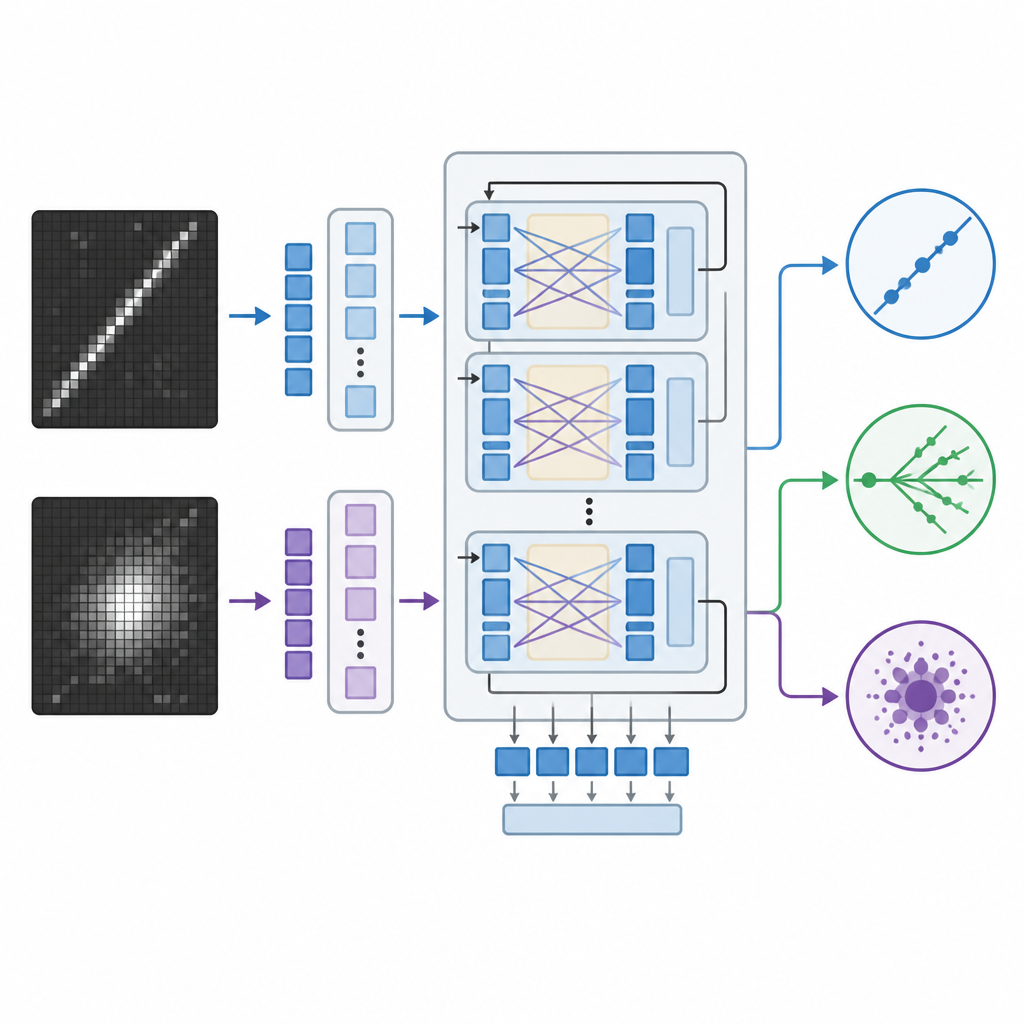
Traditionelle Bild-Erkennungssysteme in der Physik stützen sich auf Faltungsnetze (CNN) oder neuere Vision Transformer, die leistungsfähig sind, aber oft wie Black Boxes agieren und nur Zahlen ausgeben, ohne Erklärung. Das Team passte stattdessen ein großes Vision-Language-Modell an, das ursprünglich von Meta entwickelt wurde und Bilder sowie Text gemeinsam verarbeiten und schriftliche Antworten erzeugen kann. Sie feinjustierten dieses Modell auf den Neutrino-Bildern mit einer effizienten Methode, die nur einen kleinen Teil seiner Milliarden internen Parameter anpasst. Während des Trainings sah das Modell Bildpaare aus dem Detektor zusammen mit Hinweisen darauf, welche Muster für jede Interaktionsart typisch sind — etwa lange schmale Spuren oder diffuse Schauer — und lernte, jedes Ereignis einer von drei Kategorien zuzuordnen.
Wie das Modell getestet wurde
Um die Leistungsfähigkeit dieses Ansatzes zu beurteilen, verglichen die Forscher das Vision-Language-Modell mit zwei starken Alternativen: einem speziell entwickelten Faltungsnetz und einem großen Vision Transformer, der nur Bilder betrachtet. Alle drei Modelle wurden mit denselben simulierten Detektordaten trainiert und anschließend an zuvor ungesehenen Ereignissen evaluiert. Das Team maß Genauigkeit und verwandte Kennzahlen; für das Vision-Language-Modell leiteten sie außerdem Konfidenzwerte aus seinen internen Wahrscheinlichkeiten über die drei Klassen ab. Zudem setzten sie die Modelle stärkeren Bedingungen aus, indem sie die Bildauflösung herabsetzten — was Detektoren mit weniger Auslesekanälen oder komprimierten Daten nachbildet — und prüften, ob das System bei weniger detaillierten Eingabeanweisungen noch sinnvoll reagiert.
Was die Modelle zeigten
Das Vision-Language-Modell erreichte gleiche oder leicht bessere Ergebnisse als der Vision Transformer bei der korrekten Klassifizierung von Ereignissen und übertraf deutlich das Faltungsnetz, obwohl es während des Trainings wesentlich weniger Parameter aktualisierte. Beide transformerbasierten Systeme blieben robust, als die Bilder heruntergesampelt wurden, während die Leistung des Faltungsmodells stark abfiel. Ein markanter Vorteil des Vision-Language-Modells ist, dass es auch natürliche Sprach-Erklärungen generieren kann, die auf sichtbare Merkmale in den Ereignisbildern Bezug nehmen, etwa indem es auf eine lange, gerade Spur hinweist, die wie ein Myon aussieht, oder auf das Fehlen einer solchen Spur bei neutralen Stromereignissen. Diese Erklärungen offenbaren zwar nicht wörtlich die inneren Mechanismen des Modells, bieten Physikern aber ein intuitiveres Fenster dafür, warum eine Entscheidung getroffen wurde, als bloße Zahlen oder Heatmaps.
Ausblick für Physik und KI
Die Studie kommt zu dem Schluss, dass große Vision-Language-Modelle, wenn sie sorgfältig angepasst werden, als vielseitige Werkzeuge für Neutrino-Experimente dienen können, da sie starke Klassifikationsleistung mit interpretierbaren, textbasierten Beschreibungen kombinieren. Sie sind rechenintensiver als einfachere Netze, sodass leichtere Modelle für Echtzeit- oder ressourcenbeschränkte Aufgaben weiterhin bevorzugt werden. Für Offline-Analysen, bei denen Verstehen und Vertrauen wichtig sind, bieten diese multimodalen Modelle jedoch einen vielversprechenden Weg, wiederverwendbare "Foundation"-Systeme aufzubauen, die sich mit relativ geringem Zusatzaufwand für neue Detektoren und Daten feinjustieren lassen. Auf diese Weise könnte die Partnerschaft zwischen Teilchenphysik und fortgeschrittener KI Wissenschaftlern helfen, die schwachen Signaturen von Neutrinos klarer und mit größerer Zuversicht zu lesen.
Zitation: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Schlüsselwörter: Neutrino-Klassifikation, Vision-Language-Modell, Flüssig-Argon-Detektor, Hochenergiephysik, Maschinelles Lernen in der Physik