Clear Sky Science · pt
Adaptando modelos visão-linguagem para classificação de eventos de neutrinos em física de altas energias
Por que partículas minúsculas e máquinas inteligentes importam
Neutrinos são partículas fantasmáticas que atravessam o universo e raramente interagem com a matéria, mas guardam pistas sobre como a matéria e o cosmos evoluíram. Experimentos modernos com neutrinos usam detectores enormes que registram essas colisões raras como imagens de alta resolução, gerando mais dados do que humanos conseguem analisar sozinhos. Este estudo investiga como um novo tipo de inteligência artificial, chamado modelo visão-linguagem, pode ajudar cientistas a classificar e entender esses eventos com mais precisão e de forma mais acessível.
Transformando trilhas de partículas em imagens
Quando um neutrino atinge átomos dentro de um detector de argônio líquido, ele deixa rastros de partículas carregadas, um pouco como trilhas deixadas por aviões no céu. O detector converte essas trilhas em imagens detalhadas em preto e branco a partir de diferentes ângulos. Os pesquisadores construíram um conjunto de dados simulado realista dessas imagens, representando interações de diferentes tipos de neutrinos, além de uma classe de fundo em que o tipo de neutrino não pode ser identificado com clareza. Essas imagens formam o material bruto para ensinar computadores a distinguir um tipo de interação de outro, um passo chave para estudar como os neutrinos mudam de sabor enquanto viajam.
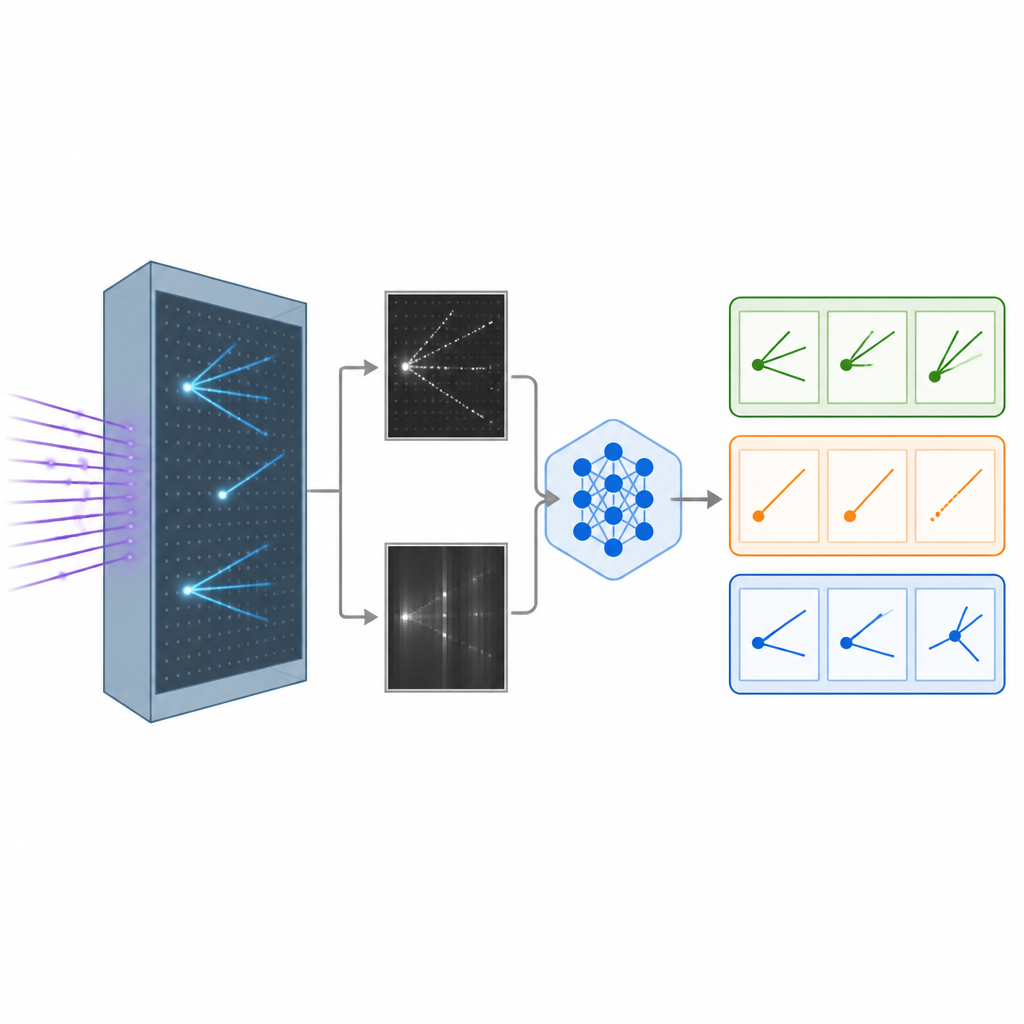
Dar à IA tanto olhos quanto palavras
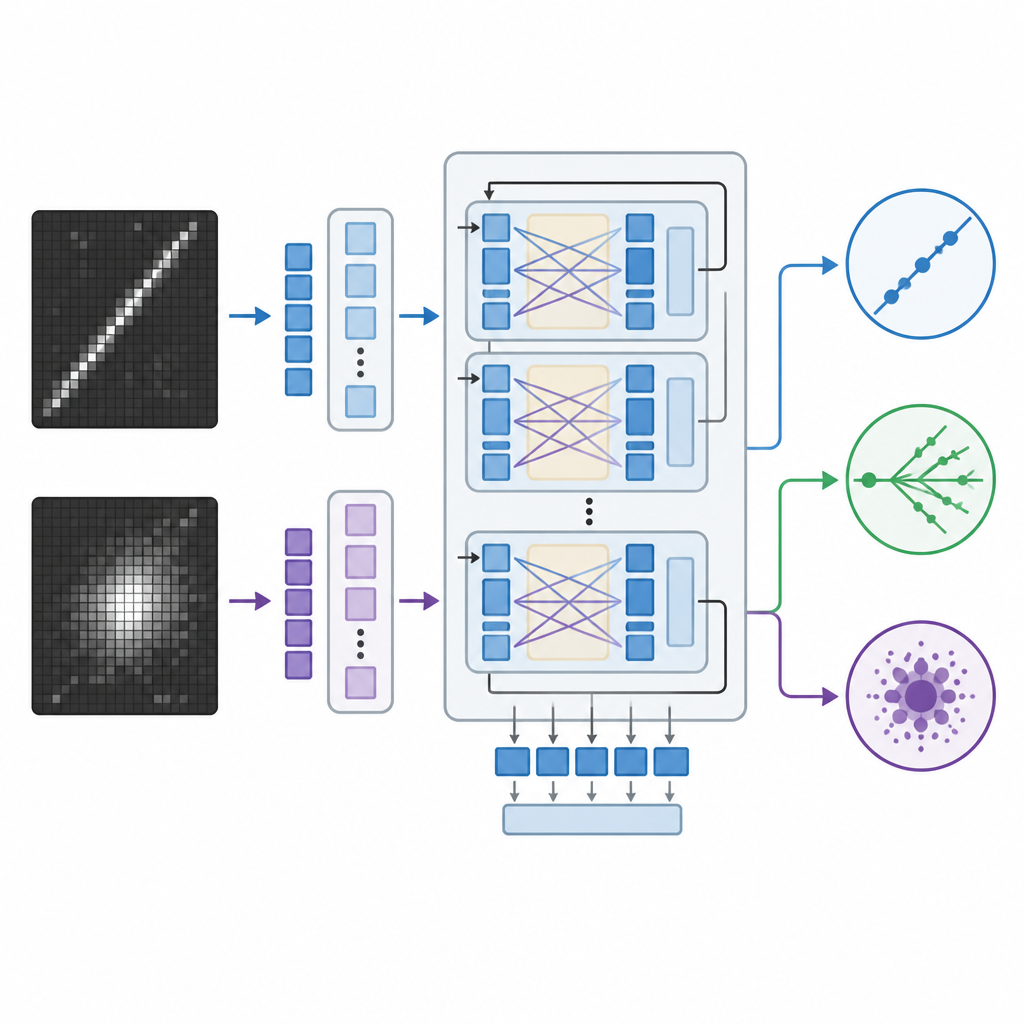
Sistemas tradicionais de reconhecimento de imagem na física dependem de redes neurais convolucionais ou de transformadores de visão mais recentes, que são poderosos mas funcionam como caixas-pretas que retornam números sem explicação. A equipe, em vez disso, adaptou um grande modelo visão-linguagem originalmente criado pela Meta, que pode receber imagens e texto juntos e gerar respostas escritas. Eles refinaram esse modelo nas imagens de neutrinos usando um método eficiente que ajusta apenas uma pequena fração de seus bilhões de parâmetros internos. Durante o treinamento, o modelo viu pares de imagens do detector juntamente com orientações sobre quais padrões marcam cada tipo de interação, como trilhas longas e estreitas ou chuveiros difusos, e aprendeu a atribuir cada evento a uma das três categorias.
Como o modelo foi testado
Para avaliar quão bem essa abordagem funciona, os pesquisadores compararam o modelo visão-linguagem com duas alternativas robustas: uma rede convolucional personalizada e um grande transformador de visão que analisa apenas imagens. Todos os três modelos foram treinados no mesmo conjunto de dados simulado do detector e depois avaliados em eventos reservados que nunca haviam visto antes. A equipe mediu acurácia e estatísticas relacionadas, e para o modelo visão-linguagem também derivou pontuações de confiança a partir de suas probabilidades internas sobre as três classes. Eles também desafiaram os modelos degradando a resolução das imagens, imitando detectores com menos canais de leitura ou dados comprimidos, e verificaram se o sistema ainda se comportava de maneira sensata quando recebeu instruções menos detalhadas.
O que os modelos revelaram
O modelo visão-linguagem igualou ou superou ligeiramente o transformador de visão na classificação correta dos eventos e superou claramente a rede convolucional, apesar de ter atualizado muito menos parâmetros durante o treinamento. Ambos os sistemas baseados em transformador permaneceram robustos quando as imagens foram reduzidas em resolução, enquanto o desempenho do modelo convolucional caiu acentuadamente. Um benefício distintivo do modelo visão-linguagem é que ele também pode gerar explicações em linguagem natural vinculadas a características visíveis nas imagens do evento, como apontar uma trilha longa e reta que se parece com um múon ou a ausência de tal trilha em eventos de corrente neutra. Embora essas explicações não revelem literalmente o funcionamento interno do modelo, elas oferecem aos físicos uma janela mais intuitiva sobre por que uma decisão foi tomada do que números brutos ou mapas de calor sozinhos.
Perspectivas para a física e a IA
O estudo conclui que grandes modelos visão-linguagem, quando cuidadosamente adaptados, podem servir como ferramentas versáteis para experimentos com neutrinos, combinando forte capacidade de classificação com descrições interpretáveis em texto. Eles exigem mais recursos computacionais do que redes mais simples, de modo que modelos mais leves ainda serão preferidos para tarefas em tempo real ou com recursos limitados. No entanto, para análises off-line em que compreensão e confiança são vitais, esses modelos multimodais oferecem um caminho promissor para construir sistemas “fundação” reutilizáveis que podem ser refinados para novos detectores e dados com relativamente pouco trabalho adicional. Dessa forma, a parceria entre física de partículas e IA avançada pode ajudar cientistas a ler as assinaturas tênues dos neutrinos de forma mais clara e com maior confiança.
Citação: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Palavras-chave: classificação de neutrinos, modelo visão-linguagem, detector de argônio líquido, física de altas energias, aprendizado de máquina na física