Clear Sky Science · sv
Anpassning av vision-language-modeller för neutrino-händelseklassificering inom högenergifysik
Varför små partiklar och smarta maskiner spelar roll
Neutriner är spökliknande partiklar som strömmar genom universum och sällan växelverkar med något, men de bär på ledtrådar till hur materia och kosmos utvecklats. Moderna neutrinoexperiment använder enorma detektorer som registrerar dessa sällsynta kollisioner som högupplösta bilder, och de producerar mer data än människor kan bearbeta på egen hand. Denna studie utforskar hur en ny typ av artificiell intelligens, kallad en vision-language-modell, kan hjälpa forskare att sortera och förstå dessa händelser mer exakt och på ett mer människovänligt sätt.
Att förvandla partikelskråpor till bilder
När en neutrino träffar atomer i en flytande argon-detektor lämnar den efter sig spår av laddade partiklar, lite som kondensstrimmor från flygplan på himlen. Detektorn omvandlar dessa spår till detaljerade svartvita bilder från olika synvinklar. Forskarna byggde en realistisk simulerad datamängd av sådana bilder, som representerar interaktioner från olika typer av neutriner, samt en bakgrundsklass där neutrino-typen inte kan identifieras entydigt. Dessa bilder utgör råmaterialet för att lära datorer att skilja en interaktionstyp från en annan, ett viktigt steg för att studera hur neutriner byter smak när de färdas.
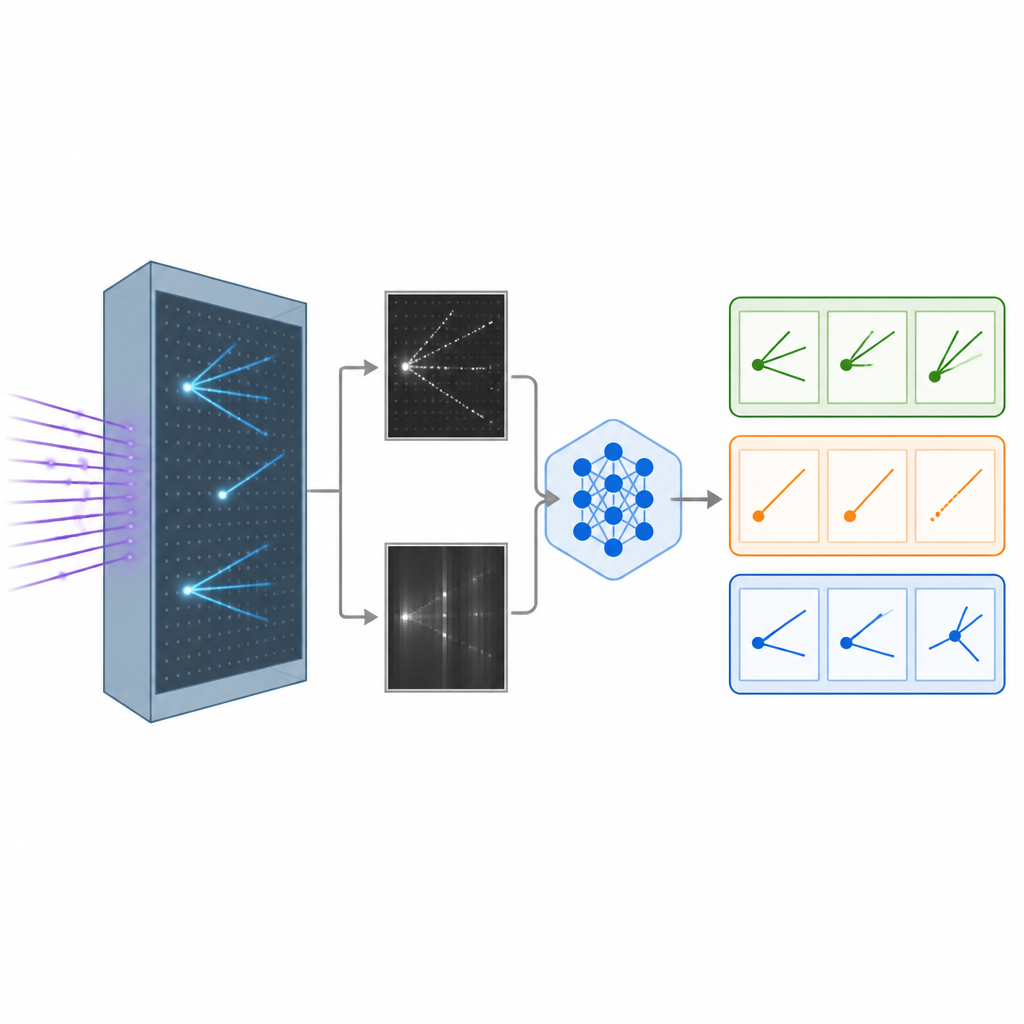
Ge AI både ögon och ord
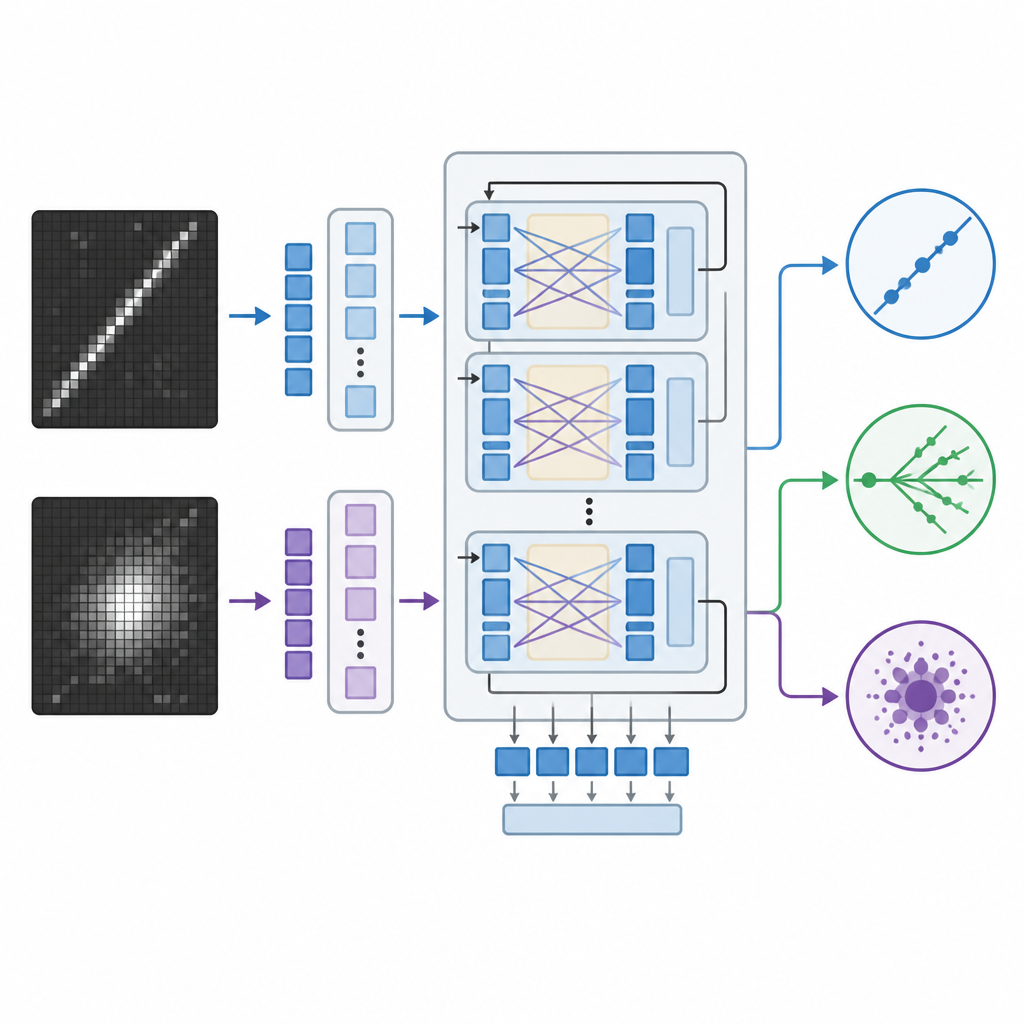
Traditionella bildigenkänningssystem inom fysik förlitar sig på konvolutionella neurala nätverk eller nyare vision-transformers, som är kraftfulla men ofta beter sig som svarta lådor som levererar siffror utan förklaring. Teamet anpassade istället en stor vision-language-modell ursprungligen skapad av Meta, som kan hantera bilder och text tillsammans och generera skriftliga svar. De finjusterade denna modell på neutrino-bilderna med en effektiv metod som justerar endast en liten del av dess miljarder interna parametrar. Under träningen såg modellen par av detektorbilder tillsammans med vägledning om vilka mönster som kännetecknar varje interaktionstyp, såsom långa smala spår eller diffusa shower, och lärde sig att tilldela varje händelse till en av tre kategorier.
Hur modellen testades
För att bedöma hur väl detta tillvägagångssätt fungerar jämförde forskarna vision-language-modellen med två starka alternativ: ett specialbyggt konvolutionellt nätverk och en stor vision-transformer som endast betraktar bilder. Alla tre modeller tränades på samma simulerade detektordata och utvärderades sedan på hållna händelser de aldrig sett tidigare. Teamet mätte noggrannhet och relaterade statistiska mått, och för vision-language-modellen härledde de också konfidenspoäng från dess interna sannolikheter över de tre klasserna. De utsatte dessutom modellerna för påfrestning genom att försämra bildupplösningen, vilket efterliknar detektorer med färre läsutgångar eller komprimerade data, och kontrollerade om systemet fortfarande betedde sig vettigt när det gavs mindre detaljerade uppmaningar.
Vad modellerna avslöjade
Vision-language-modellen matchade eller överträffade svagt vision-transformern i att korrekt klassificera händelser och överträffade tydligt det konvolutionella nätverket, trots att den uppdaterade betydligt färre parametrar under träningen. Båda transformer-baserade systemen förblev robusta när bilderna nedsamplades till lägre upplösning, medan det konvolutionella nätverkets prestanda sjönk kraftigt. En utmärkande fördel med vision-language-modellen är att den även kan generera naturligt språkade förklaringar kopplade till synliga drag i händelsebilderna, till exempel att peka ut ett långt, rakt spår som ser ut som en muon eller avsaknaden av ett sådant spår i neutrinoklivhändelser. Även om dessa förklaringar inte bokstavligen blottlägger modellens inre funktioner, ger de fysiker en mer intuitiv inblick i varför ett beslut fattades än bara råa siffror eller värmekartor.
Framåtblick för fysik och AI
Studien slår fast att stora vision-language-modeller, när de anpassas omsorgsfullt, kan fungera som mångsidiga verktyg för neutrinoexperiment och kombinera kraftfull klassificeringsförmåga med tolkbara, textbaserade beskrivningar. De kräver mer beräkningsresurser än enklare nätverk, så lättare modeller kommer fortfarande att föredras för realtids- eller resursbegränsade uppgifter. För offlineanalyser där förståelse och förtroende är avgörande erbjuder dessa multimodala modeller däremot ett lovande sätt att bygga återanvändbara ”foundations”-system som kan finjusteras för nya detektorer och data med relativt litet extra arbete. På så sätt kan partnerskapet mellan partikelfysik och avancerad AI hjälpa forskare att läsa de svaga signaturerna från neutriner klarare och med större säkerhet.
Citering: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Nyckelord: neutrino-klassificering, vision-language-modell, flytande argon-detektor, högenergifysik, maskininlärning i fysik