Clear Sky Science · fr
Adapter des modèles vision-langage pour la classification d'événements neutrinos en physique des hautes énergies
Pourquoi les particules minuscules et les machines intelligentes comptent
Les neutrinos sont des particules fantomatiques qui traversent l'univers et interagissent rarement avec la matière, et pourtant elles portent des indices sur l'évolution de la matière et du cosmos. Les expériences modernes sur les neutrinos utilisent d'énormes détecteurs qui enregistrent ces rares collisions sous forme d'images très détaillées, générant plus de données que ce que les humains peuvent traiter seuls. Cette étude examine comment un type d'intelligence artificielle récent, appelé modèle vision-langage, peut aider les scientifiques à trier et comprendre ces événements plus précisément et de manière plus accessible.
Transformer des traces de particules en images
Lorsqu'un neutrino frappe des atomes à l'intérieur d'un détecteur à argon liquide, il laisse derrière lui des traces de particules chargées, un peu comme des traînées d'avions dans le ciel. Le détecteur convertit ces tracés en images détaillées en noir et blanc vues sous différents angles. Les chercheurs ont constitué un jeu de données simulées réaliste de telles images, représentant des interactions de différents types de neutrinos, ainsi qu'une classe de fond où le type de neutrino ne peut pas être identifié de manière nette. Ces images constituent la matière première pour apprendre aux ordinateurs à distinguer un type d'interaction d'un autre, une étape clé pour étudier comment les neutrinos changent de saveur lors de leur déplacement.
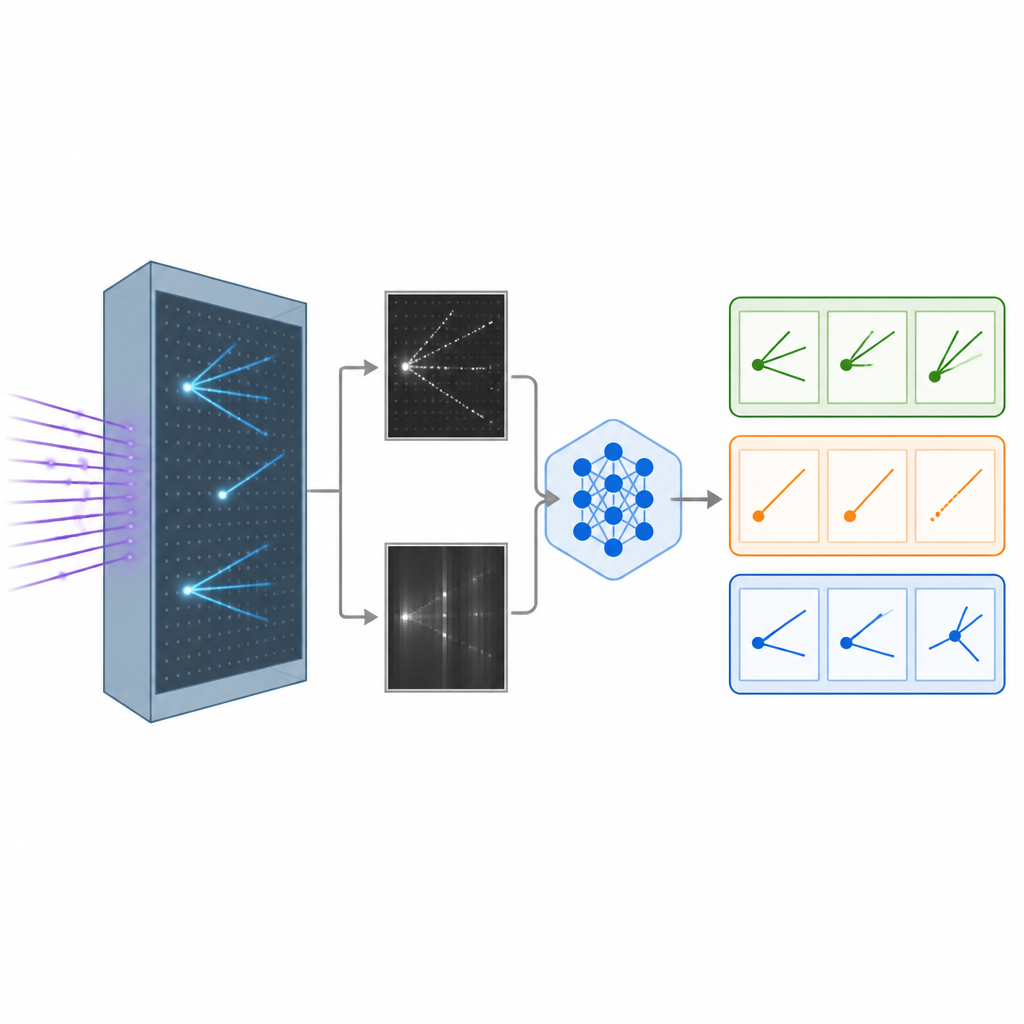
Donner à l'IA à la fois des yeux et des mots
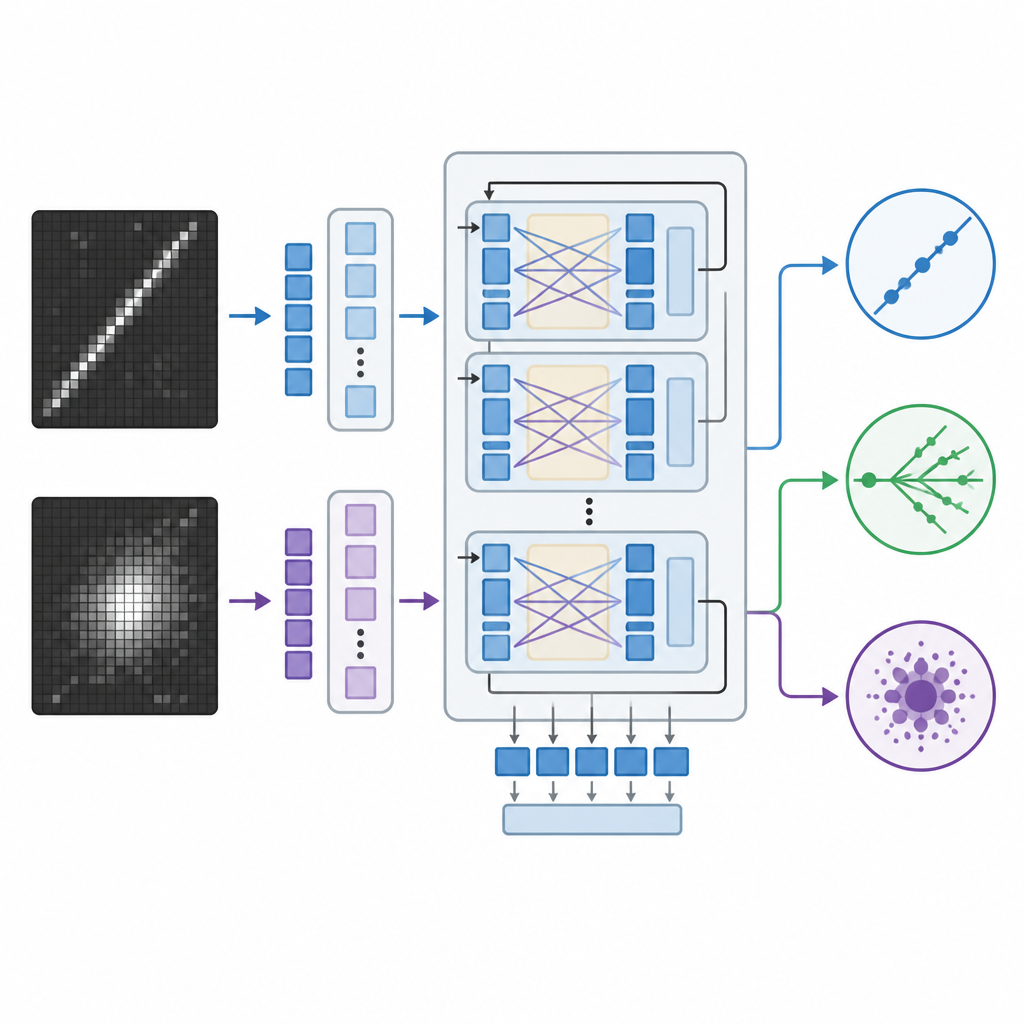
Les systèmes classiques de reconnaissance d'images en physique reposent sur des réseaux de neurones convolutionnels ou des transformeurs de vision plus récents, qui sont puissants mais fonctionnent souvent comme des boîtes noires rendant des nombres sans explication. L'équipe a plutôt adapté un grand modèle vision-langage initialement créé par Meta, capable de traiter images et texte conjointement et de générer des réponses écrites. Ils ont affiné ce modèle sur les images de neutrinos en utilisant une méthode efficace qui n'ajuste qu'une petite portion de ses milliards de paramètres internes. Pendant l'entraînement, le modèle a vu des paires d'images du détecteur accompagnées d'indications sur les motifs caractérisant chaque type d'interaction, comme des traces longues et étroites ou des gerbes diffuses, et a appris à assigner chaque événement à l'une des trois catégories.
Comment le modèle a été testé
Pour juger de l'efficacité de l'approche, les chercheurs ont comparé le modèle vision-langage à deux alternatives robustes : un réseau convolutionnel conçu sur mesure et un grand transformeur de vision qui ne considère que les images. Les trois modèles ont été entraînés sur les mêmes données simulées du détecteur puis évalués sur des événements tenus à l'écart qu'ils n'avaient jamais vus. L'équipe a mesuré la précision et des statistiques associées, et pour le modèle vision-langage ils ont aussi extrait des scores de confiance à partir de ses probabilités internes sur les trois classes. Ils ont encore mis les modèles à l'épreuve en dégradant la résolution des images, simulant des détecteurs avec moins de canaux de lecture ou des données compressées, et en vérifiant si le système se comportait toujours de manière sensée avec des invites moins détaillées.
Ce que les modèles ont révélé
Le modèle vision-langage a égalé ou légèrement dépassé le transformeur de vision pour la classification correcte des événements et a nettement surperformé le réseau convolutionnel, malgré la mise à jour d'un bien plus petit nombre de paramètres lors de l'entraînement. Les deux systèmes basés sur des transformeurs sont restés robustes lorsque les images ont été sous-échantillonnées à une résolution plus faible, tandis que la performance du modèle convolutionnel chutait fortement. Un avantage distinctif du modèle vision-langage est qu'il peut aussi générer des explications en langage naturel liées aux caractéristiques visibles dans les images d'événements, comme signaler une trace longue et droite ressemblant à un muon ou l'absence d'une telle trace dans des événements à courant neutre. Bien que ces explications n'exposent pas littéralement le fonctionnement interne du modèle, elles offrent aux physiciens une fenêtre plus intuitive sur les raisons d'une décision que de simples nombres ou des cartes de chaleur.
Perspectives pour la physique et l'IA
L'étude conclut que les grands modèles vision-langage, lorsqu'ils sont adaptés avec soin, peuvent servir d'outils polyvalents pour les expériences sur les neutrinos, alliant une forte capacité de classification à des descriptions interprétables en texte. Ils sont plus exigeants en calcul que des réseaux plus simples, de sorte que des modèles allégés resteront préférés pour les tâches en temps réel ou en environnement contraint. Cependant, pour les analyses hors ligne où la compréhension et la confiance sont essentielles, ces modèles multimodaux offrent une voie prometteuse pour construire des systèmes « fondation » réutilisables, susceptibles d'être affinés pour de nouveaux détecteurs et jeux de données avec relativement peu d'efforts supplémentaires. De cette façon, le partenariat entre la physique des particules et l'IA avancée pourrait aider les scientifiques à lire les faibles signatures des neutrinos plus clairement et avec davantage de confiance.
Citation: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Mots-clés: classification de neutrinos, modèle vision-langage, détecteur à argon liquide, physique des hautes énergies, apprentissage automatique en physique