Clear Sky Science · nl
Vision-language-modellen aanpassen voor neutrino-evenementclassificatie in de deeltjesfysica met hoge energie
Waarom piepkleine deeltjes en slimme machines ertoe doen
Neutrino's zijn spookachtige deeltjes die door het universum stromen en zelden met iets interageren, maar ze bevatten aanwijzingen over hoe materie en het heelal zich ontwikkelden. Moderne neutrino-experimenten gebruiken enorme detectoren die deze zeldzame botsingen vastleggen als fijnmazige beelden, en produceren meer data dan mensen alleen kunnen doorzoeken. Deze studie onderzoekt hoe een nieuw soort kunstmatige intelligentie, een vision-language-model, wetenschappers kan helpen deze gebeurtenissen nauwkeuriger en op een voor mensen toegankelijkere manier te sorteren en te begrijpen.
Deeltjessporen omzetten in beelden
Wanneer een neutrino atomen in een vloeibaar-argon-detector raakt, laat het sporen van geladen deeltjes achter, een beetje zoals condensstrepen van vliegtuigen aan de hemel. De detector zet die sporen om in gedetailleerde zwart-witbeelden vanuit verschillende gezichtspunten. De onderzoekers bouwden een realistische gesimuleerde dataset van zulke beelden, die interacties van verschillende types neutrino's weergeven, en een achtergrondklasse waar het neutrino-type niet eenduidig te bepalen is. Deze beelden vormen het ruwe materiaal om computers te leren het ene soort interactie van het andere te onderscheiden, een belangrijke stap voor het bestuderen van hoe neutrino's van smaak veranderen tijdens hun reis.
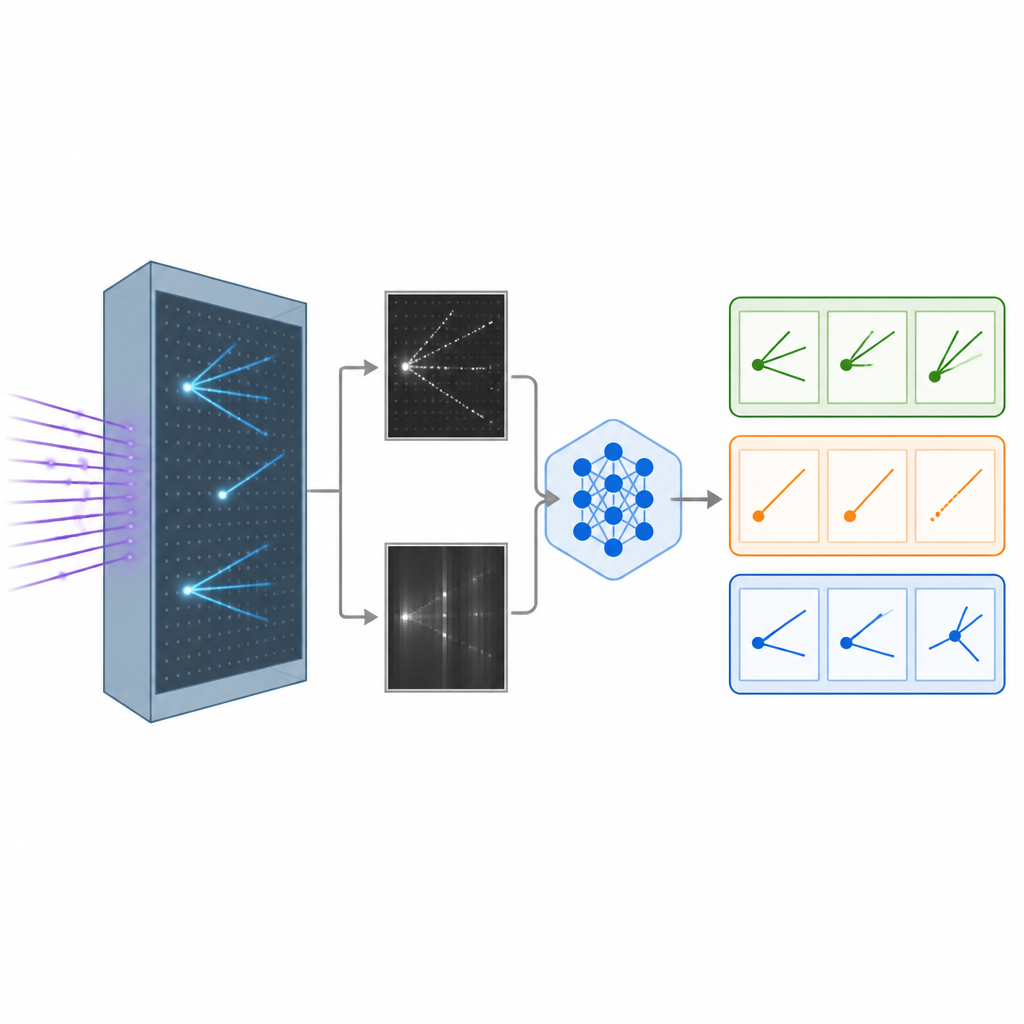
De AI zowel ogen als woorden geven
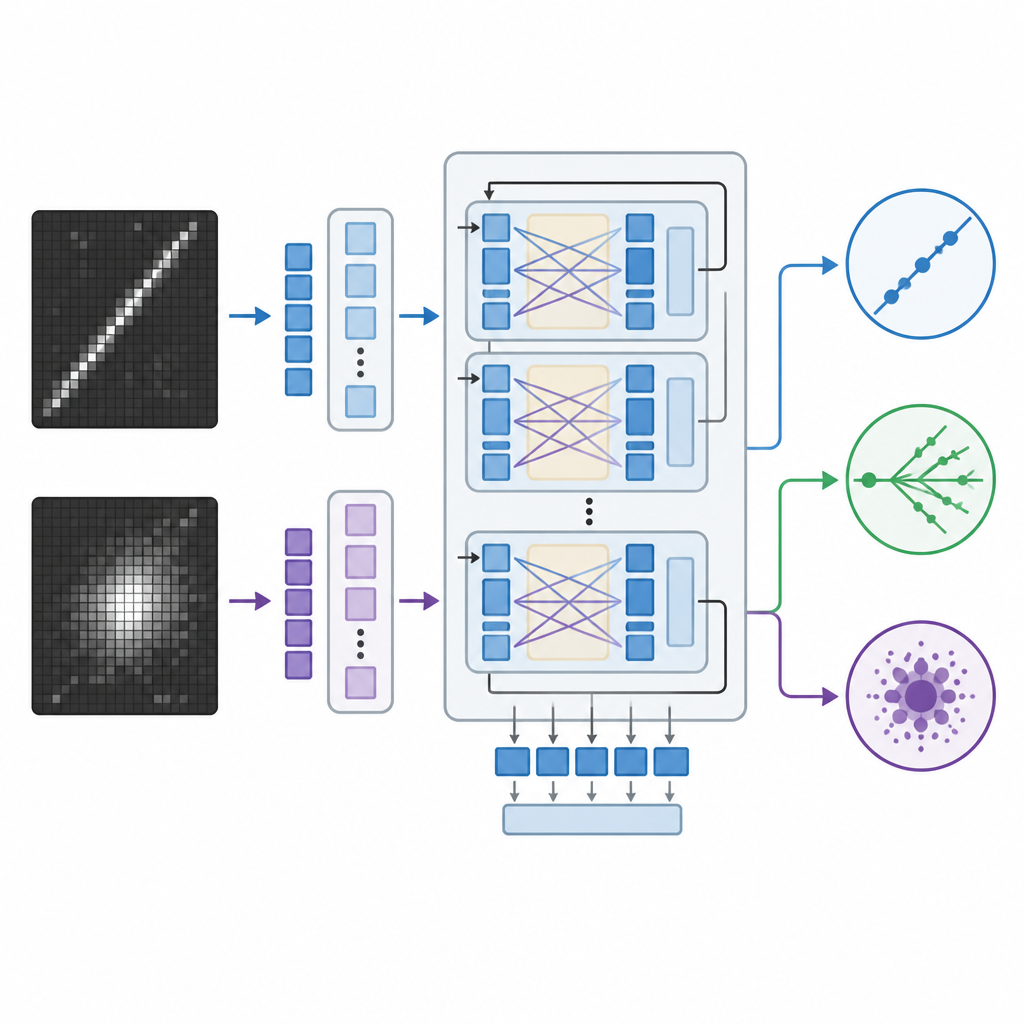
Traditionele beeldherkenningssystemen in de fysica vertrouwen op convolutionele neurale netwerken of nieuwere vision-transformers, die krachtig zijn maar vaak als black boxes functioneren die alleen getallen opleveren zonder uitleg. Het team paste in plaats daarvan een groot vision-language-model aan dat oorspronkelijk door Meta is ontwikkeld en dat beelden en tekst samen kan verwerken en schriftelijke reacties kan genereren. Ze fine-tuneden dit model op de neutrino-beelden met een efficiënte methode die slechts een klein deel van de miljarden interne parameters aanpast. Tijdens het trainen zag het model paren van detectorbeelden samen met aanwijzingen over welke patronen bij elk interactietype horen, zoals lange smalle sporen of vage schuivers, en leerde elk evenement aan een van drie categorieën toe te wijzen.
Hoe het model getest werd
Om te beoordelen hoe goed deze aanpak werkt, vergeleken de onderzoekers het vision-language-model met twee sterke alternatieven: een speciaal gebouwd convolutioneel netwerk en een grote vision-transformer die alleen naar beelden kijkt. Alle drie de modellen werden getraind op dezelfde gesimuleerde detectordata en vervolgens geëvalueerd op gehouden-uit evenementen die ze nog nooit eerder gezien hadden. Het team mat nauwkeurigheid en verwante statistieken, en voor het vision-language-model bepaalden ze ook betrouwbaarheidscores uit de interne waarschijnlijkheden over de drie klassen. Ze zetten de modellen verder op de proef door de beeldresolutie te verlagen, waarmee ze detectoren met minder uitleeskanalen of gecomprimeerde data nabootsten, en door te controleren of het systeem nog steeds zinnig handelde bij minder gedetailleerde prompts.
Wat de modellen onthulden
Het vision-language-model kwam gelijk aan of overtrof de vision-transformer licht in het correct classificeren van gebeurtenissen en presteerde duidelijk beter dan het convolutionele netwerk, ondanks dat het veel minder parameters bijwerkte tijdens het trainen. Beide op transformer gebaseerde systemen bleven robuust toen beelden naar een lagere resolutie werden teruggebracht, terwijl de prestaties van het convolutionele model sterk daalden. Een onderscheidend voordeel van het vision-language-model is dat het ook natuurlijke-taaluitleg kan genereren die gekoppeld zijn aan zichtbare kenmerken in de gebeurtenisbeelden, zoals het aanwijzen van een lang, recht spoor dat op een muon lijkt of het ontbreken van zo’n spoor bij neutrale-stroomgebeurtenissen. Hoewel deze verklaringen niet letterlijk de innerlijke werking van het model blootleggen, geven ze natuurkundigen een meer intuïtief inzicht in waarom een beslissing is genomen dan alleen ruwe getallen of warmtemappen.
Vooruitkijken voor de fysica en AI
De studie concludeert dat grote vision-language-modellen, mits zorgvuldig aangepast, kunnen dienen als veelzijdige hulpmiddelen voor neutrino-experimenten, waarbij sterke classificatiekracht gecombineerd wordt met interpreteerbare, tekstgebaseerde beschrijvingen. Ze vragen meer computationele middelen dan eenvoudigere netwerken, dus lichtere modellen blijven de voorkeur hebben voor realtime- of middelenbeperkte taken. Voor offline-analyses waar begrip en vertrouwen cruciaal zijn, bieden deze multimodale modellen echter een veelbelovende manier om herbruikbare "foundation"-systemen te bouwen die met relatief weinig extra inspanning voor nieuwe detectoren en data kunnen worden gefine-tuned. Op die manier kan de samenwerking tussen deeltjesfysica en geavanceerde AI wetenschappers helpen de zwakke handtekeningen van neutrino's helderder en met grotere zekerheid te lezen.
Bronvermelding: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Trefwoorden: neutrino-classificatie, vision-language-model, vloeibaar-argon-detector, hoge-energie-fysica, machine learning in de fysica