Clear Sky Science · en
Adapting vision-language models for neutrino event classification in high-energy physics
Why tiny particles and smart machines matter
Neutrinos are ghostlike particles that stream through the universe and rarely interact with anything, yet they hold clues to how matter and the cosmos evolved. Modern neutrino experiments use huge detectors that record these rare collisions as fine-grained images, producing more data than humans can sift through alone. This study explores how a new kind of artificial intelligence, called a vision language model, can help scientists sort and understand these events more accurately and in a more human-friendly way.
Turning particle tracks into pictures
When a neutrino hits atoms inside a liquid argon detector, it leaves behind trails of charged particles, a bit like contrails from airplanes crossing the sky. The detector turns these trails into detailed black-and-white images from different viewing angles. The researchers built a realistic simulated dataset of such images, representing interactions from different types of neutrinos, as well as a background class where the neutrino type cannot be cleanly identified. These images form the raw material for teaching computers how to tell one kind of interaction from another, a key step for studying how neutrinos change flavor as they travel.
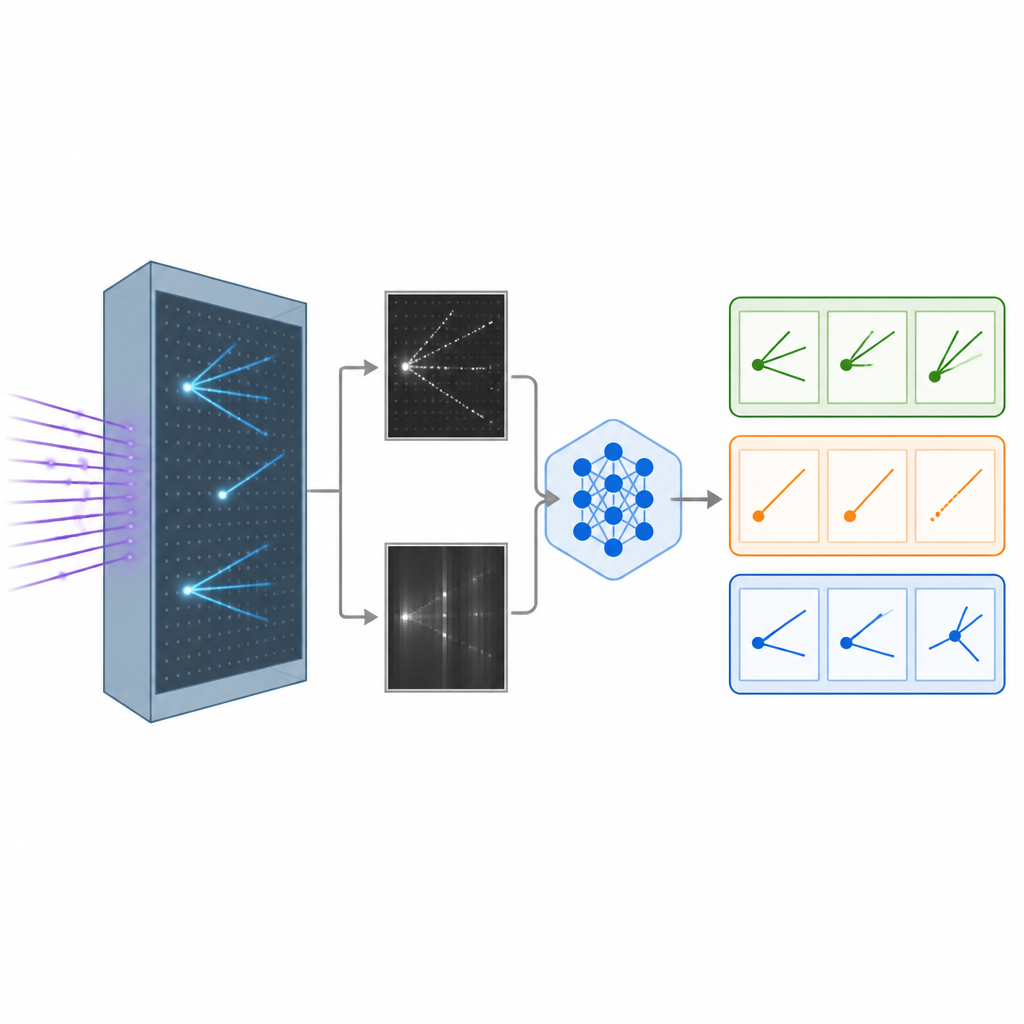
Giving AI both eyes and words
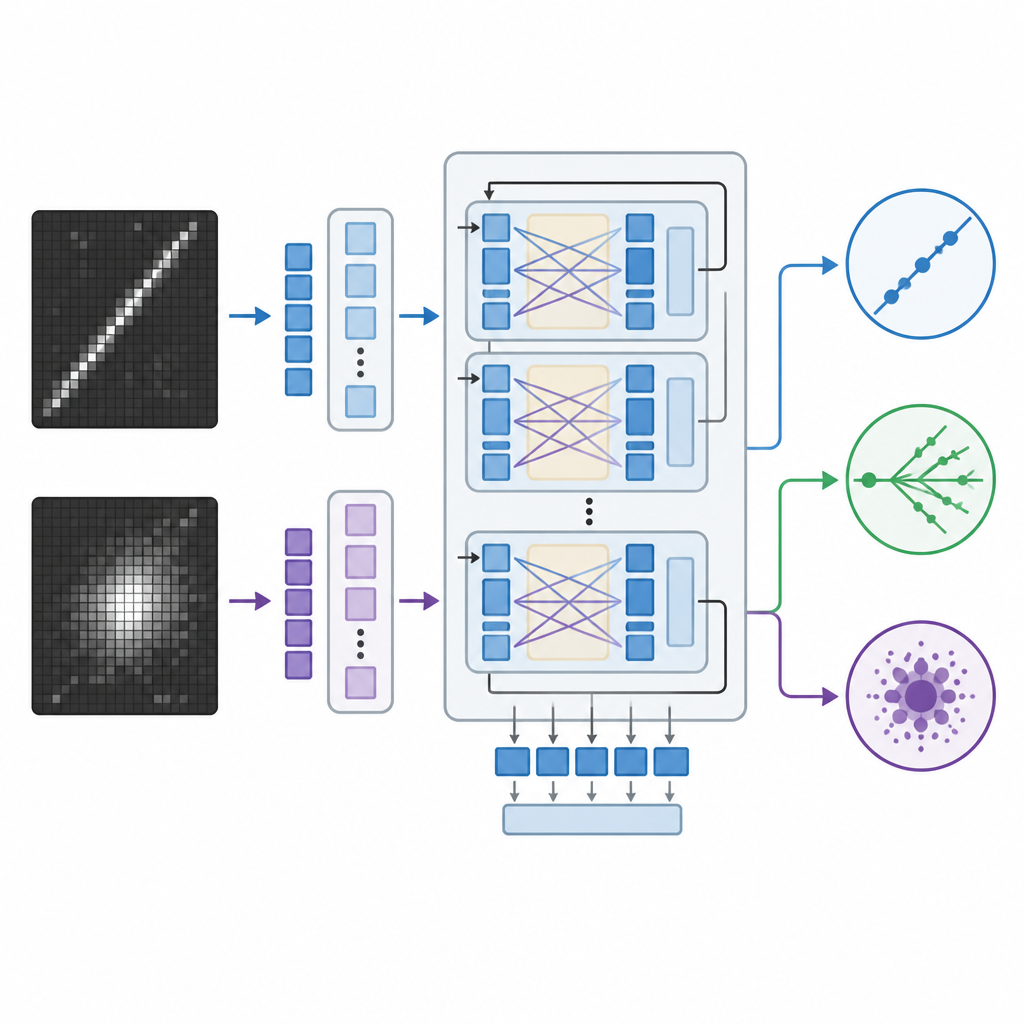
Traditional image-recognition systems in physics rely on convolutional neural networks or newer vision transformers, which are powerful but behave like black boxes that spit out numbers without explanation. The team instead adapted a large vision language model originally created by Meta, which can take images and text together and generate written responses. They fine-tuned this model on the neutrino images using an efficient method that adjusts only a small portion of its billions of internal settings. During training, the model saw pairs of detector images along with guidance about what patterns mark each interaction type, such as long narrow tracks or fuzzy showers, and learned to assign each event to one of three categories.
How the model was tested
To judge how well this approach works, the researchers compared the vision language model to two strong alternatives: a custom-built convolutional network and a large vision transformer that looks only at images. All three models were trained on the same simulated detector data and then evaluated on held-out events they had never seen before. The team measured accuracy and related statistics, and for the vision language model they also derived confidence scores from its internal probabilities over the three classes. They further pushed the models by degrading the image resolution, mimicking detectors with fewer readout channels or compressed data, and by checking whether the system still behaved sensibly when given less detailed prompts.
What the models revealed
The vision language model matched or slightly surpassed the vision transformer in correctly classifying events and clearly outperformed the convolutional network, even though it updated far fewer parameters during training. Both transformer-based systems remained robust when images were downsampled to lower resolution, while the convolutional model’s performance dropped sharply. A distinctive benefit of the vision language model is that it can also generate natural language explanations tied to visible features in the event images, such as pointing out a long, straight track that looks like a muon or the absence of such a track in neutral current events. Although these explanations do not literally expose the model’s inner workings, they give physicists a more intuitive window into why a decision was made than raw numbers or heat maps alone.
Looking ahead for physics and AI
The study concludes that large vision language models, when carefully adapted, can serve as versatile tools for neutrino experiments, combining strong classification power with interpretable, text-based descriptions. They are more computationally demanding than simpler networks, so lighter models will still be preferred for real-time or resource-limited tasks. However, for offline analyses where understanding and trust are vital, these multimodal models offer a promising way to build reusable “foundation” systems that can be fine-tuned for new detectors and data with relatively little extra work. In this way, the partnership between particle physics and advanced AI could help scientists read the faint signatures of neutrinos more clearly and with greater confidence.
Citation: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Keywords: neutrino classification, vision language model, liquid argon detector, high energy physics, machine learning in physics