Clear Sky Science · ru
Адаптация визуально-языковых моделей для классификации событий нейтрино в физике высоких энергий
Почему важны крошечные частицы и умные машины
Нейтрино — почти неощутимые частицы, пронизывающие вселенную и редко взаимодействующие с материей, но в них скрыты подсказки о развитии материи и космоса. Современные эксперименты с нейтрино используют огромные детекторы, которые фиксируют эти редкие столкновения в виде детализированных изображений, производя объёмы данных, с которыми человеку трудно справиться. В этой работе исследуется, как новый класс искусственного интеллекта — визуально-языковая модель — может помочь учёным точнее сортировать и интерпретировать такие события, делая результаты более понятными для человека.
Преобразование следов частиц в изображения
Когда нейтрино сталкивается с атомами внутри детектора на жидком аргоне, оно оставляет за собой следы заряженных частиц, подобно конденсационным следам самолётов на небе. Детектор преобразует эти следы в детальные чёрно‑белые изображения с разных ракурсов. Авторы построили реалистичный синтетический набор данных таких изображений, представляющий взаимодействия разных типов нейтрино, а также фоновый класс, в котором тип нейтрино нельзя однозначно определить. Эти изображения служат исходным материалом для обучения компьютеров отличать один тип взаимодействия от другого — ключевой шаг в изучении превращений нейтрино при их движении.
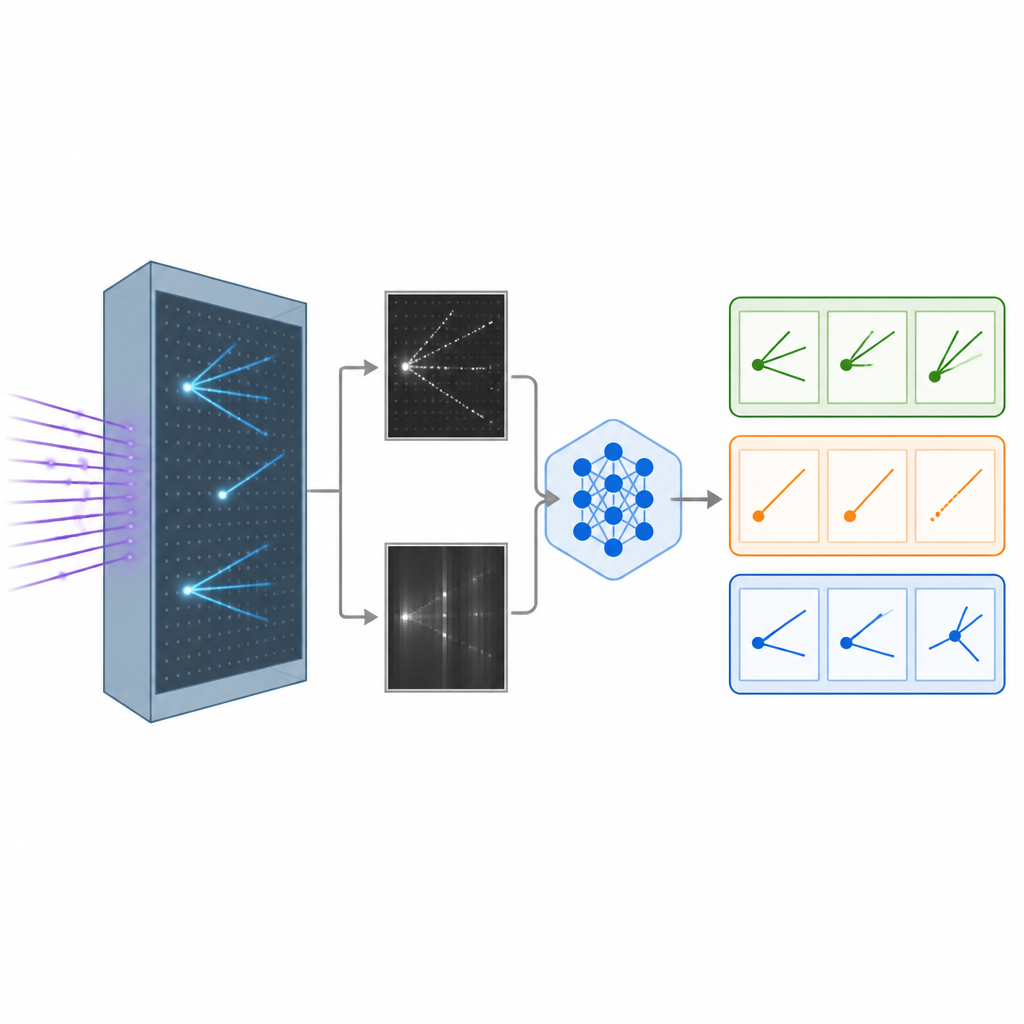
Дать ИИ и глаза, и слова
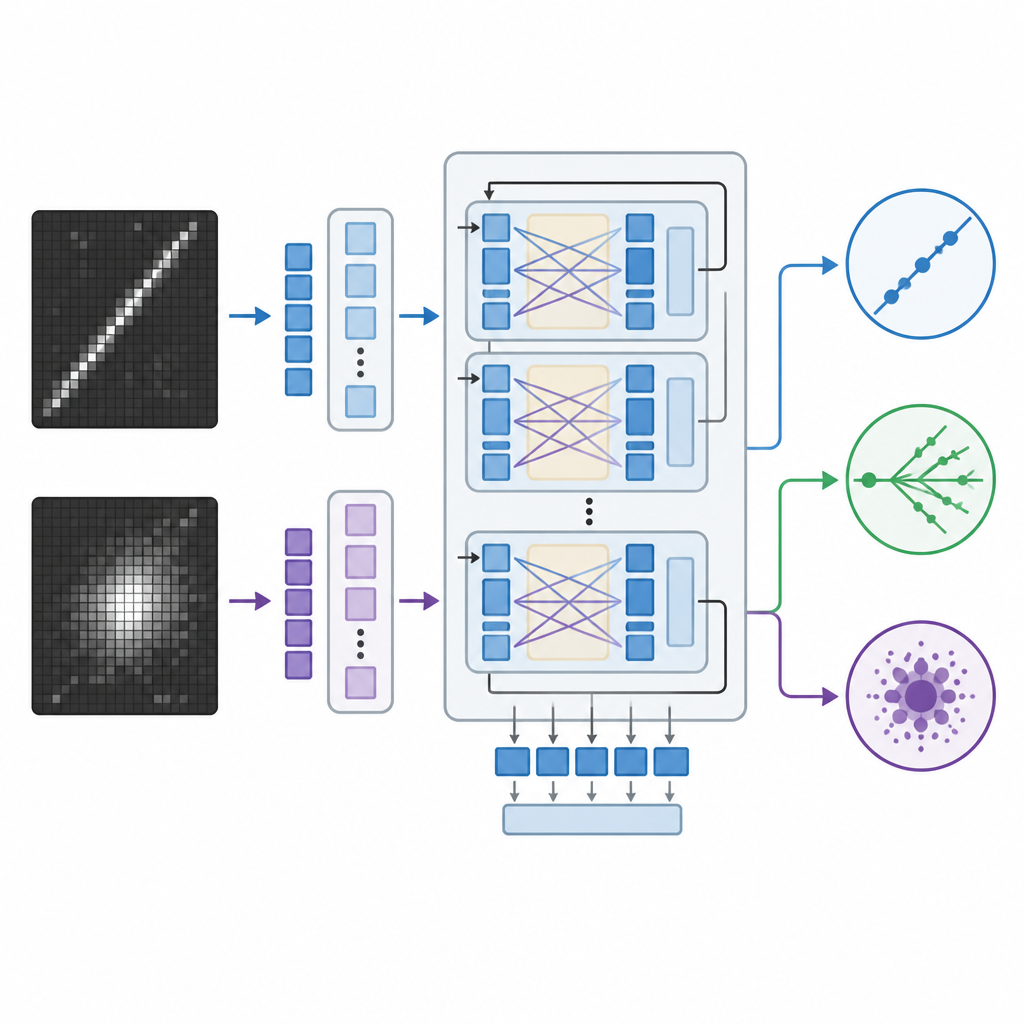
Традиционные системы распознавания изображений в физике опираются на свёрточные нейронные сети или более новые визуальные трансформеры — они мощные, но часто представляют собой «чёрные ящики», выдающие числа без объяснений. Команда вместо этого адаптировала большую визуально-языковую модель, изначально разработанную Meta, которая обрабатывает изображения вместе с текстом и генерирует текстовые ответы. Модель дообучали на изображениях нейтрино с использованием эффективного метода, изменяющего лишь небольшую часть её миллиардов внутренних параметров. В процессе обучения модель видела пары изображений детектора вместе с подсказками о признаках, характеризующих каждый тип взаимодействия — например, длинные узкие треки или расплывчатые лавины — и научилась относить событие к одной из трёх категорий.
Как тестировали модель
Чтобы оценить эффективность подхода, исследователи сравнили визуально-языковую модель с двумя сильными альтернативами: специально разработанной свёрточной сетью и крупным визуальным трансформером, работающим только с изображениями. Все три модели обучали на одном и том же синтетическом наборе данных детектора и затем проверяли на отложенных событиях, которых они не видели ранее. Команда измеряла точность и сопутствующие метрики, а для визуально-языковой модели дополнительно извлекала оценки уверенности из её внутренних вероятностей по трём классам. Также модели испытывали, ухудшая разрешение изображений — имитируя детекторы с меньшим числом каналов считывания или сжатые данные — и проверяли, сохраняет ли система разумное поведение при менее подробных подсказках.
Что показали модели
Визуально-языковая модель сопоставима или немного превосходит визуальный трансформер по правильной классификации событий и заметно опережает свёрточную сеть, несмотря на то, что при обучении она обновляла гораздо меньше параметров. Обе системы на базе трансформеров оставались устойчивыми при понижении разрешения изображений, тогда как производительность свёрточной модели резко падала. Отдельное преимущество визуально-языковой модели в том, что она может генерировать объяснения на естественном языке, привязанные к видимым признакам на изображениях событий — например, указывать на длинный прямой трек, похожий на мюон, или на отсутствие такого трека в нейтрально‑текущих событиях. Хотя эти объяснения не раскрывают буквально внутреннее устройство модели, они дают физикам более интуитивное представление о причинах принятого решения, чем одни лишь числовые оценки или тепловые карты.
Взгляд в будущее для физики и ИИ
Авторы приходят к выводу, что при аккуратной адаптации большие визуально-языковые модели могут служить универсальными инструментами для экспериментов с нейтрино, сочетая мощную классификацию с интерпретируемыми текстовыми описаниями. Они требуют больше вычислительных ресурсов, чем более простые сети, поэтому для задач в реальном времени или с ограниченными ресурсами предпочтение по‑прежнему будет отдаваться более лёгким моделям. Однако для офлайн‑анализов, где важны понимание и доверие, эти мультимодальные модели предлагают перспективный путь создания переиспользуемых «фундаментальных» систем, которые можно дообучать для новых детекторов и данных с относительно небольшими дополнительными усилиями. Так партнёрство между физикой элементарных частиц и продвинутым ИИ может помочь учёным яснее и увереннее читать слабые сигнатуры нейтрино.
Цитирование: Sagar, D., Yu, K., Yankelevich, A. et al. Adapting vision-language models for neutrino event classification in high-energy physics. Commun Phys 9, 186 (2026). https://doi.org/10.1038/s42005-026-02688-3
Ключевые слова: классификация нейтрино, визуально-языковая модель, детектор на жидком аргоне, физика высоких энергий, машинное обучение в физике