Clear Sky Science · zh
机器学习与深度学习揭示编码双价组蛋白修饰的序列决定因素
DNA 的标点如何塑造细胞的未来
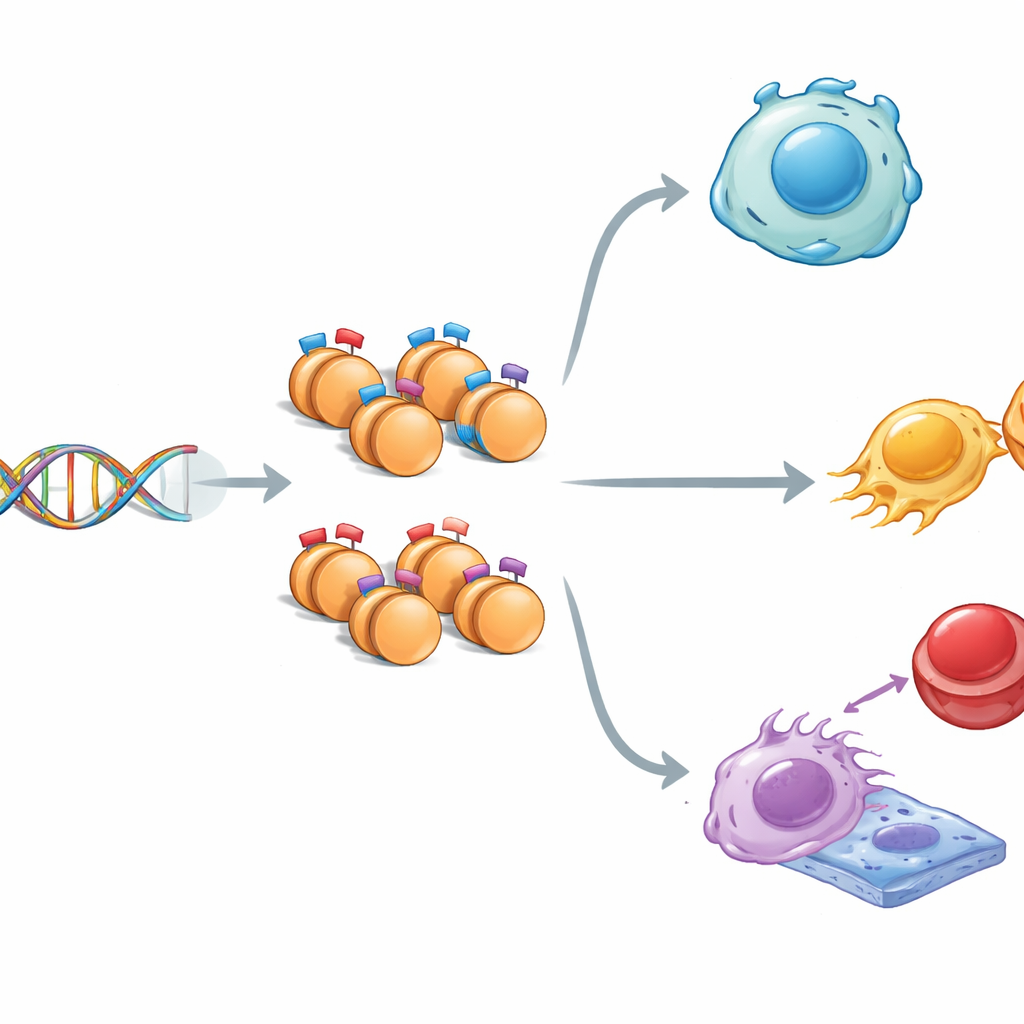
你体内的每个细胞基本上都携带相同的 DNA,然而脑细胞和肌肉细胞的行为却截然不同。其一原因是包裹 DNA 的蛋白质上的化学标签可以在不改变遗传密码的情况下开关基因。本研究提出了一个看似简单却意义重大的问题:DNA 序列中是否存在隐藏的模式,告诉细胞在哪里放置一种“混合”标签,使关键基因在沉默与活跃之间保持一种待命状态?
两种对立标记的故事
在细胞核内,DNA 绕着称为组蛋白的蛋白纺锤卷绕。这些组蛋白可以携带促使基因活性(“开”)或抑制它(“关”)的信号。有时,两类信号会出现在同一位点,形成科学家所谓的“双价”状态——基因处于一种准备就绪但尚未执行的模式。研究者在小鼠胚胎干细胞(可分化为几乎任何组织)中绘制了三种关键组蛋白标记在基因组上的分布。他们发现带有混合标记的区域与单一标记区域不同:这些区域略窄,富含 G 和 C 碱基,并在进化上更为保守,这提示这些待命的 DNA 区域尤其重要并受到精细保护。
为发育与疾病准备的待命开关
当团队将这些带标记的区域与其邻近基因关联时,出现了明确的模式。被混合组蛋白信号标记的基因通常仅适度表达,并在早期发育以及干细胞保持可塑性或特化的决定过程中发挥重要作用。Hippo、MAPK、Wnt 和 TGF-β 等通路——这些关于生长与组织形成的核心通信电路——在这些基因中高度富集。一些带有双价标记的基因也与癌症有关,表明同一套引导健康发育的待命控制系统可能在疾病中被劫持。总体而言,混合标记像经过精细调节的调光开关,给予基因一个微妙的基础活性,同时在信号到来时保持它们可以被迅速加强或关闭的准备状态。
训练机器去识别隐藏的 DNA 模式
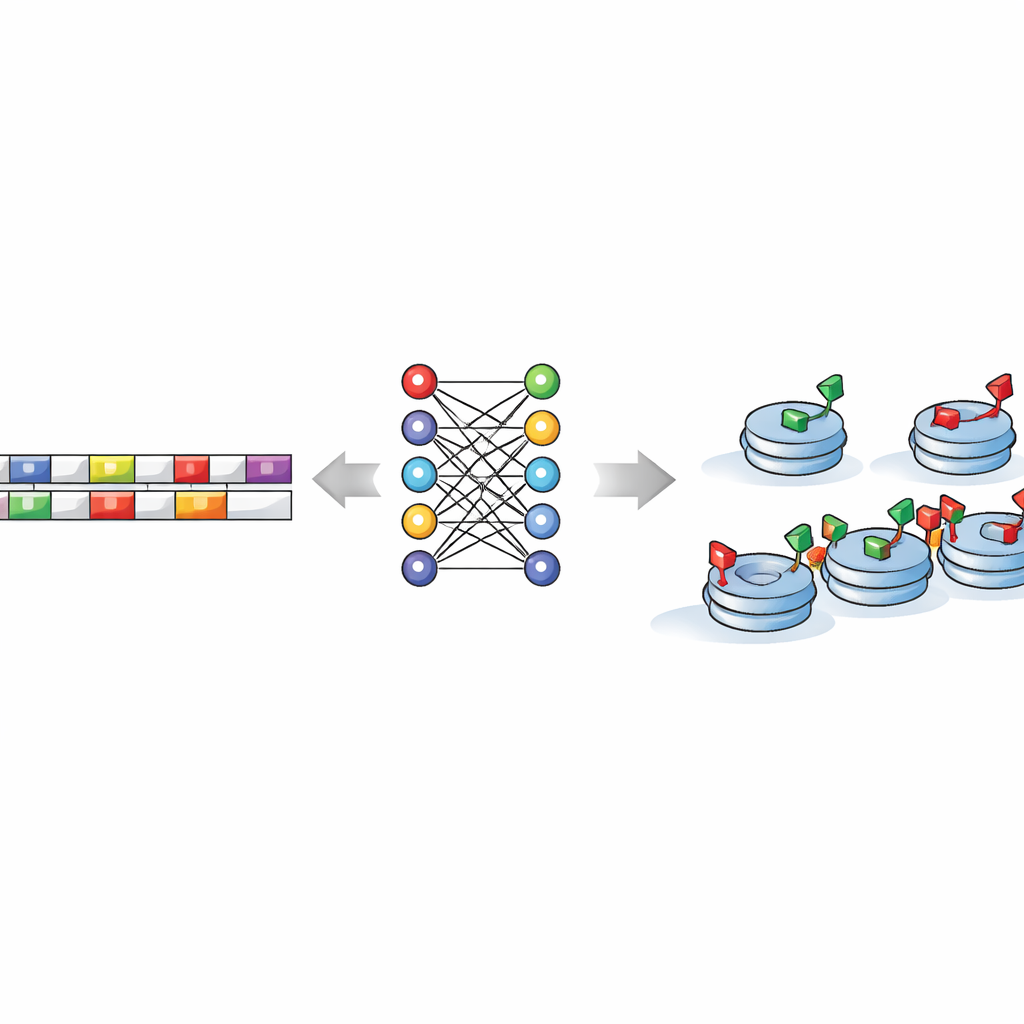
研究的核心问题是 DNA 序列本身是否编码了这些待命状态形成位置的指令。为检验这一点,研究者将短片段 DNA——分解为所有可能的几字母“小词”——输入一组机器学习与深度学习模型。这些算法学会区分带有混合标记的区域与仅有激活性或仅有抑制性标记的区域,且通常具有很高的准确率。关键在于,将 DNA 字母随机打乱后,模型便失效,表明真实基因组中存在真实的可预测信号而不是偶然噪音。这意味着在不借助任何实验测量的情况下,计算机仅凭 DNA 文本就能推测细胞可能放置这些混合组蛋白标记的位置。
作为分子路标的序列基元
通过解析模型内部,作者发现了若干短的 DNA 基元——重复出现的字母模式——这些模式特别具有信息量。其中一些,如类似 TCTGAA 与 TCACAG 的序列,与主导干细胞调控因子(如 OCT4、SOX2、ESRRB 以及名为 TCFCP2l1 的因子)的已知结合位点相匹配。其他基元则倾向于聚集在双价标记区域的边缘,暗示某些基元可能有助于设定这些待命染色质区的边界。不同的基元组合与排列区分了不同类型的混合标记,意味着尽管许多调控蛋白相同,每类双价状态仍遵循其自身的“语法”规则。
对干细胞及其更广泛意义的影响
简言之,该研究表明 DNA 不仅仅是一系列基因清单;它还内含关于这些基因应如何被打包以及对信号的响应准备程度的指令。在胚胎干细胞中,特定的短 DNA 模式有助于招募蛋白因子并塑造对立组蛋白标记共存的区域,使发育基因维持在开与关之间的微妙平衡。借助机器学习与深度学习来解读这一隐藏代码,作者既提供了一个从序列预测表观基因组状态的实用工具,也更清晰地描绘了细胞如何在早期生命过程中将灵活性编入基因组——以及这种编程如何在疾病中出错的可能途径。
引用: Zhao, X., Wu, J., Che, Y. et al. Machine and Deep Learning Reveal Sequence Determinants Encoding Bivalent Histone Modifications. Commun Biol 9, 491 (2026). https://doi.org/10.1038/s42003-026-09962-8
关键词: 双价染色质, 组蛋白修饰, 胚胎干细胞, DNA 序列基元, 基因组学中的机器学习