Clear Sky Science · nl
Machine en Deep Learning onthullen sequentiebepalende factoren voor bivalente histonmodificaties
Hoe de leestekens van DNA de toekomst van een cel vormen
Elke cel in je lichaam draagt in wezen hetzelfde DNA, en toch gedragen hersencellen en spiercellen zich totaal verschillend. Een reden is dat chemische labels op de eiwitten die DNA verpakken genen aan of uit kunnen zetten zonder de genetische code zelf te veranderen. Deze studie stelt een verrassend eenvoudige vraag met grote implicaties: bestaan er verborgen patronen in de DNA‑sequentie die de cel aangeven waar een speciaal soort “gemengd” label moet worden geplaatst dat cruciale genen tussen stilte en activiteit in houdt?
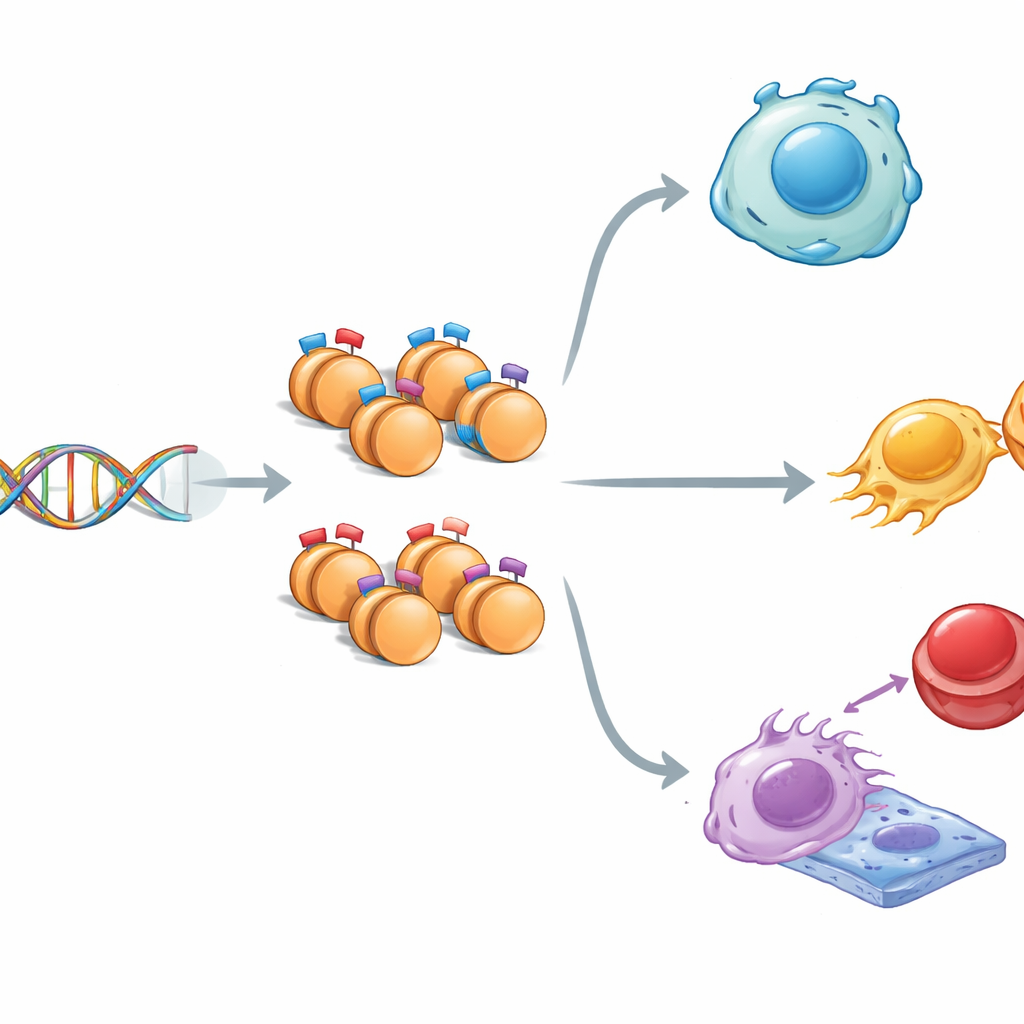
Het verhaal van twee tegengestelde labels
In de kern is DNA gewikkeld rond eiwitspoelen die histonen heten. Deze histonen kunnen signalen dragen die ofwel genactiviteit aanmoedigen (“ga”) ofwel onderdrukken (“stop”). Soms zitten beide types signalen samen op dezelfde plek, waardoor wat wetenschappers een “bivalente” toestand noemen ontstaat—genen worden in een gereed‑maar‑afwachtende modus gehouden. Met muisembryonale stamcellen, die bijna elk weefsel kunnen worden, brachten de onderzoekers drie sleutel‑histonlabels over het genoom in kaart. Ze vonden dat regio’s met gemengde labels verschilden van regio’s met slechts één label: ze waren iets smaller, rijker aan de DNA‑letters G en C, en sterker bewaard gebleven tijdens de evolutie, wat suggereert dat deze gereedstaande DNA‑stukken bijzonder belangrijk en zorgvuldig beschermd zijn.
Gereedstaande schakelaars voor ontwikkeling en ziekte
Toen het team deze gelabelde regio’s koppelde aan nabije genen, verscheen een patroon. Genen gemarkeerd door gemengde histonsignalen werden meestal slechts matig tot expressie gebracht en waren sterk betrokken bij vroege ontwikkeling en bij de beslissing van stamcellen om flexibel te blijven of te specialiseren. Pathways zoals Hippo, MAPK, Wnt en TGF‑beta—kerncommunicatiestromen voor groei en weefselvorming—waren sterk vertegenwoordigd. Sommige bivalent gemarkeerde genen zijn ook in verband gebracht met kanker, wat suggereert dat hetzelfde gereedschap van gereedstaande controle dat gezonde ontwikkeling stuurt, bij ziekte gekaapt kan worden. Over het algemeen lijken de gemengde labels te werken als fijn afgestelde dimmers, die genen een subtiele basisactiviteit geven terwijl ze klaar blijven om op te schakelen of uit te worden gezet wanneer signalen binnenkomen.
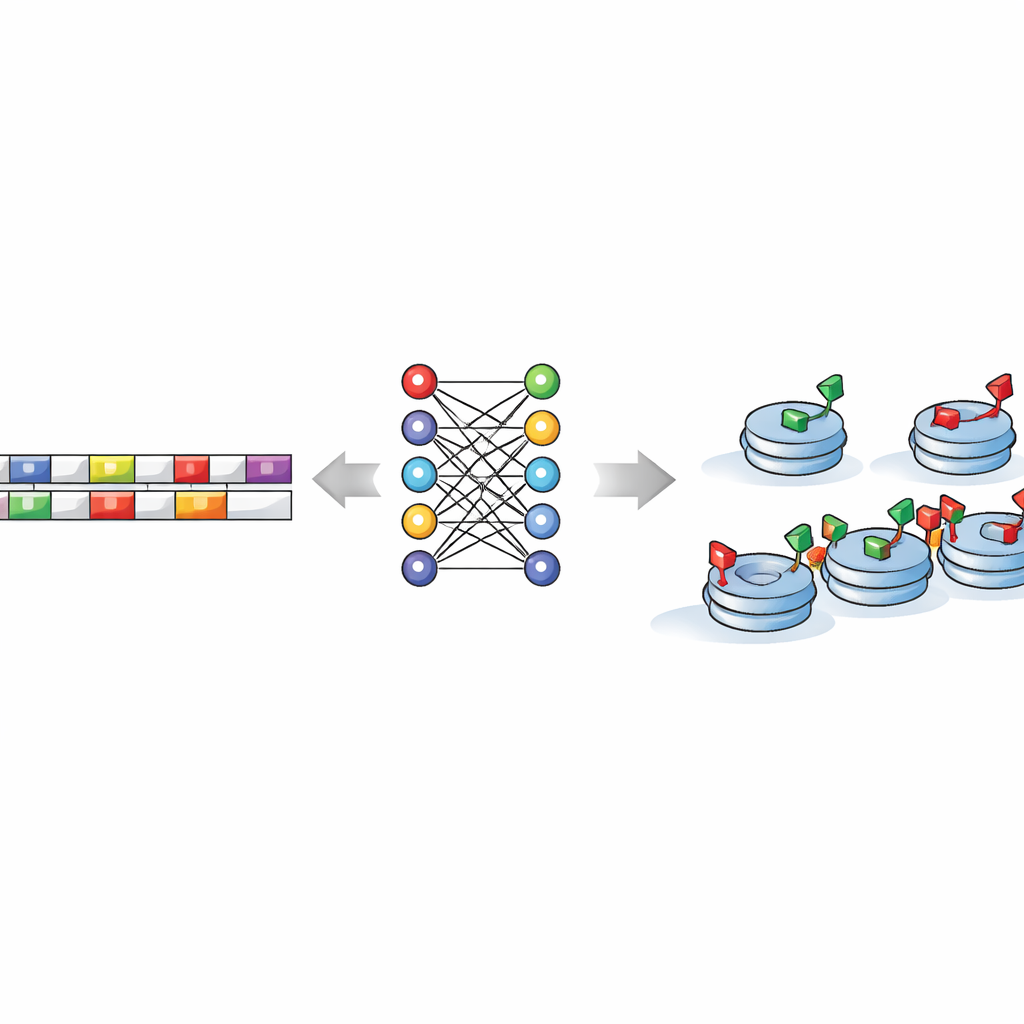
Machines leren verborgen DNA‑patronen lezen
De kernvraag van de studie is of de DNA‑sequentie zelf instructies bevat voor waar deze gereedstaande toestanden zich vormen. Om dit te testen voerden de onderzoekers korte stukken DNA—opgedeeld in alle mogelijke kleine “woorden” van een paar letters—aan een reeks machine learning‑ en deep learningmodellen. Deze algoritmes leerden regio’s met gemengde labels te onderscheiden van regio’s met alleen activerende of alleen repressieve labels, vaak met hoge nauwkeurigheid. Cruciaal was dat wanneer de DNA‑letters willekeurig werden geschud, de modellen faalden, wat liet zien dat het echte genoom authentieke voorspellende signalen draagt in plaats van toevallige ruis. Dit betekent dat een computer zonder experimentele metingen alleen aan de hand van de DNA‑tekst kan voorspellen waar de cel waarschijnlijk deze gemengde histonlabels plaatst.
Sequentiemotieven als moleculaire wegwijzers
Door in de modellen te kijken, ontdekten de auteurs een handvol korte DNA‑motieven—terugkerende lettersubstrengen—die bijzonder informatief waren. Sommige, zoals sequenties die leken op TCTGAA en TCACAG, kwamen overeen met bekende bindingsplaatsen van meesterregulatoren van stamcellen zoals OCT4, SOX2, ESRRB en een factor genaamd TCFCP2l1. Andere motieven clusterden nabij de randen van bivalent gemarkeerde regio’s, wat suggereert dat bepaalde motieven kunnen helpen de grenzen van deze gereedstaande chromatinezones te zetten. Verschillende combinaties en plaatsingen van motieven onderscheiden het ene type gemengde markering van het andere, wat impliceert dat elke klasse van bivalentie zijn eigen “grammatica” van sequentieregels volgt, ook al delen ze veel van dezelfde regulatorische eiwitten.
Wat dit betekent voor stamcellen en verder
Kort gezegd toont de studie aan dat DNA niet alleen een lijst van genen is; het draagt ook ingesloten instructies over hoe strak die genen verpakt moeten worden en hoe paraat ze zijn om te reageren. In embryonale stamcellen helpen specifieke korte DNA‑patronen eiwitfactoren te rekruteren en vorm te geven aan regio’s waar tegengestelde histonlabels coëxisteren, waardoor ontwikkelingsgenen op een scheidslijn tussen aan en uit blijven balanceren. Door machine learning en deep learning te gebruiken om deze verborgen code te lezen, bieden de auteurs zowel een praktisch hulpmiddel om epigenetische toestanden uit sequentie te voorspellen als een helderder beeld van hoe cellen flexibiliteit in hun genoom programmeren tijdens de vroege levensfasen—en hoe die programmering bij ziekte verstoord kan raken.
Bronvermelding: Zhao, X., Wu, J., Che, Y. et al. Machine and Deep Learning Reveal Sequence Determinants Encoding Bivalent Histone Modifications. Commun Biol 9, 491 (2026). https://doi.org/10.1038/s42003-026-09962-8
Trefwoorden: bivalent chromatine, histonmodificaties, embryonale stamcellen, DNA-sequentiemotieven, machine learning in genomica