Clear Sky Science · fr
L’apprentissage automatique et profond révèle les déterminants de séquence encodant les modifications histones bivalentes
Comment la ponctuation de l’ADN façonne l’avenir d’une cellule
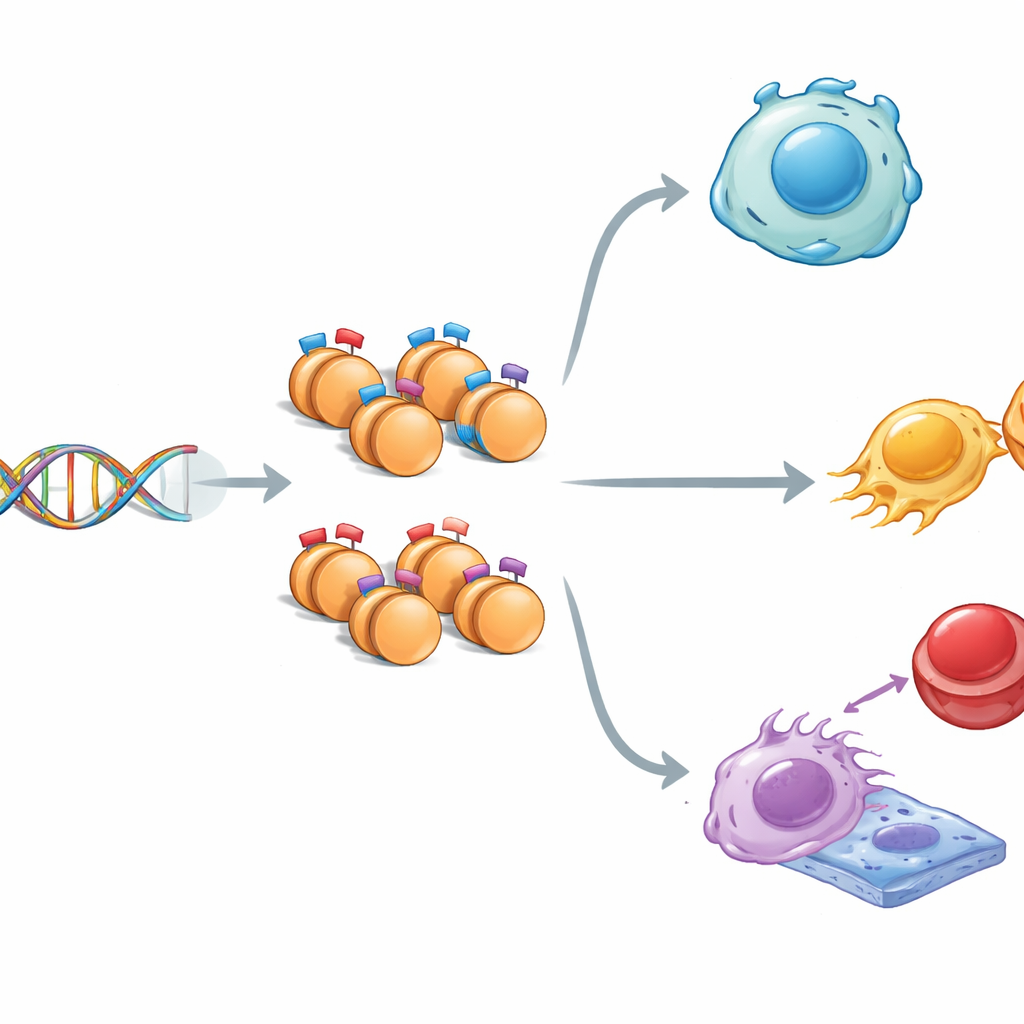
Toutes les cellules de votre corps portent essentiellement le même ADN, et pourtant les cellules nerveuses et musculaires se comportent de manière très différente. Une des raisons tient aux marques chimiques portées par les protéines qui emballent l’ADN : elles peuvent activer ou réprimer des gènes sans modifier le code génétique lui‑même. Cette étude pose une question étonnamment simple aux conséquences importantes : existe‑t‑il des motifs cachés dans la séquence d’ADN qui indiquent à la cellule où placer un type spécial de marque « mixte » qui maintient des gènes cruciaux à mi‑chemin entre le silence et l’activité ?
Une histoire de deux marques opposées
Dans le noyau, l’ADN s’enroule autour de bobines protéiques appelées histones. Ces histones peuvent porter des signaux qui encouragent l’activité des gènes (« go ») ou la suppriment (« stop »). Parfois, les deux types de signaux coexistent au même endroit, créant ce que les scientifiques appellent un état « bivalent » : les gènes restent prêts mais en attente. En utilisant des cellules souches embryonnaires de souris, capables de donner presque tous les tissus, les chercheurs ont cartographié trois marques histones clés à l’échelle du génome. Ils ont observé que les régions portant des marques mixtes diffèrent des régions à marque unique : elles sont un peu plus étroites, plus riches en bases G et C, et mieux conservées au cours de l’évolution, ce qui suggère que ces segments en attente de l’ADN sont particulièrement importants et soigneusement préservés.
Interrupteurs prêts pour le développement et la maladie
Lorsque l’équipe a relié ces régions marquées aux gènes voisins, un schéma est apparu. Les gènes marqués par des signaux histones mixtes avaient tendance à être activés seulement modérément et étaient fortement impliqués dans le développement précoce et dans la décision des cellules souches de rester flexibles ou de se spécialiser. Des voies telles que Hippo, MAPK, Wnt et TGF‑beta — des circuits de communication centraux pour la croissance et la formation des tissus — étaient surreprésentées. Certains gènes marqués bivalentement ont également été associés à des cancers, suggérant que le même système de contrôle en attente qui guide un développement sain peut être détourné dans la maladie. Globalement, les marques mixtes semblent fonctionner comme des variateurs finement réglés, donnant aux gènes un niveau d’activité de base subtil tout en les maintenant prêts à s’amplifier ou à s’éteindre lorsque des signaux surviennent.
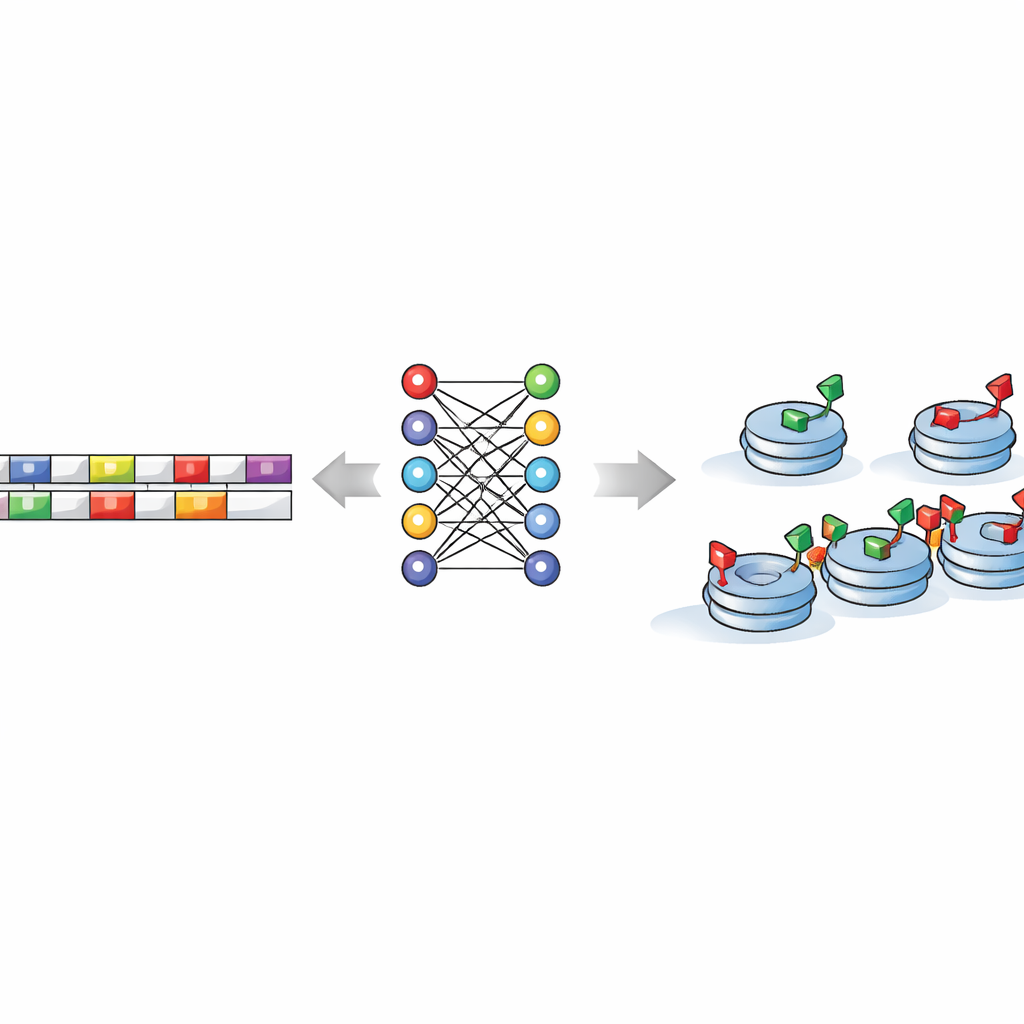
Apprendre aux machines à lire les motifs cachés de l’ADN
Le cœur de l’étude interroge si la séquence d’ADN elle‑même encode des instructions indiquant où ces états prêts doivent se former. Pour le tester, les chercheurs ont découpé de courts segments d’ADN — réduits à tous les « mots » possibles de quelques lettres — et les ont fournis à un ensemble de modèles d’apprentissage automatique et d’apprentissage profond. Ces algorithmes ont appris à distinguer les régions à marques mixtes de celles ne portant qu’une marque activating ou répressive, souvent avec une grande précision. Crucialement, lorsque les lettres d’ADN ont été mélangées au hasard, les modèles ont échoué, montrant que le génome réel porte des signaux prédictifs authentiques plutôt qu’un bruit fortuit. Cela signifie que, sans aucune mesure expérimentale, un ordinateur peut utiliser uniquement le texte de l’ADN pour deviner où la cellule est susceptible de placer ces marques histones mixtes.
Les motifs de séquence comme panneaux indicateurs moléculaires
En sondant l’intérieur des modèles, les auteurs ont découvert une poignée de courts motifs d’ADN — motifs de lettres récurrents — particulièrement informatifs. Certains, comme des séquences ressemblant à TCTGAA et TCACAG, correspondaient à des sites de liaison connus de régulateurs maîtres des cellules souches tels qu’OCT4, SOX2, ESRRB, et un facteur appelé TCFCP2l1. D’autres avaient tendance à se regrouper près des bords des régions marquées bivalentement, suggérant que certains motifs pourraient aider à définir les limites de ces zones de chromatine en attente. Différentes combinaisons et positionnements de motifs distinguaient un type de marquage mixte d’un autre, impliquant que chaque classe de bivalence suit sa propre « grammaire » de règles de séquence tout en partageant de nombreux mêmes facteurs régulateurs.
Ce que cela signifie pour les cellules souches et au‑delà
En termes simples, l’étude montre que l’ADN n’est pas seulement une liste de gènes ; il porte aussi des instructions intégrées sur la façon dont ces gènes doivent être empaquetés et sur leur degré de préparation à répondre. Dans les cellules souches embryonnaires, des motifs courts spécifiques de l’ADN contribuent à recruter des facteurs protéiques et à façonner les régions où des marques histones opposées coexistent, maintenant les gènes du développement en équilibre sur une lame entre marche et arrêt. En utilisant l’apprentissage automatique et l’apprentissage profond pour lire ce code caché, les auteurs fournissent à la fois un outil pratique pour prédire les états épigénétiques à partir de la séquence et une image plus claire de la façon dont les cellules programment la flexibilité dans leur génome au cours des premières étapes de la vie — et comment ce programme peut mal tourner dans la maladie.
Citation: Zhao, X., Wu, J., Che, Y. et al. Machine and Deep Learning Reveal Sequence Determinants Encoding Bivalent Histone Modifications. Commun Biol 9, 491 (2026). https://doi.org/10.1038/s42003-026-09962-8
Mots-clés: chromatine bivalente, modifications des histones, cellules souches embryonnaires, motifs de séquence ADN, apprentissage automatique en génomique