Clear Sky Science · de
Maschinen- und Deep Learning enthüllen Sequenzdeterminanten, die bivalente Histon-Modifikationen codieren
Wie die Interpunktionszeichen der DNA die Zukunft einer Zelle formen
Jede Zelle in Ihrem Körper trägt im Wesentlichen dieselbe DNA, dennoch verhalten sich Nervenzellen und Muskelzellen völlig unterschiedlich. Ein Grund dafür sind chemische Markierungen an den DNA-verpackenden Proteinen, die Gene ein- oder ausschalten können, ohne den genetischen Code zu verändern. Diese Studie stellt eine überraschend einfache Frage mit weitreichenden Folgen: Gibt es verborgene Muster in der DNA-Sequenz, die der Zelle verraten, wo eine besondere Art von „gemischter“ Markierung platziert werden soll, die wichtige Gene zwischen Ruhe und Aktivität hält?
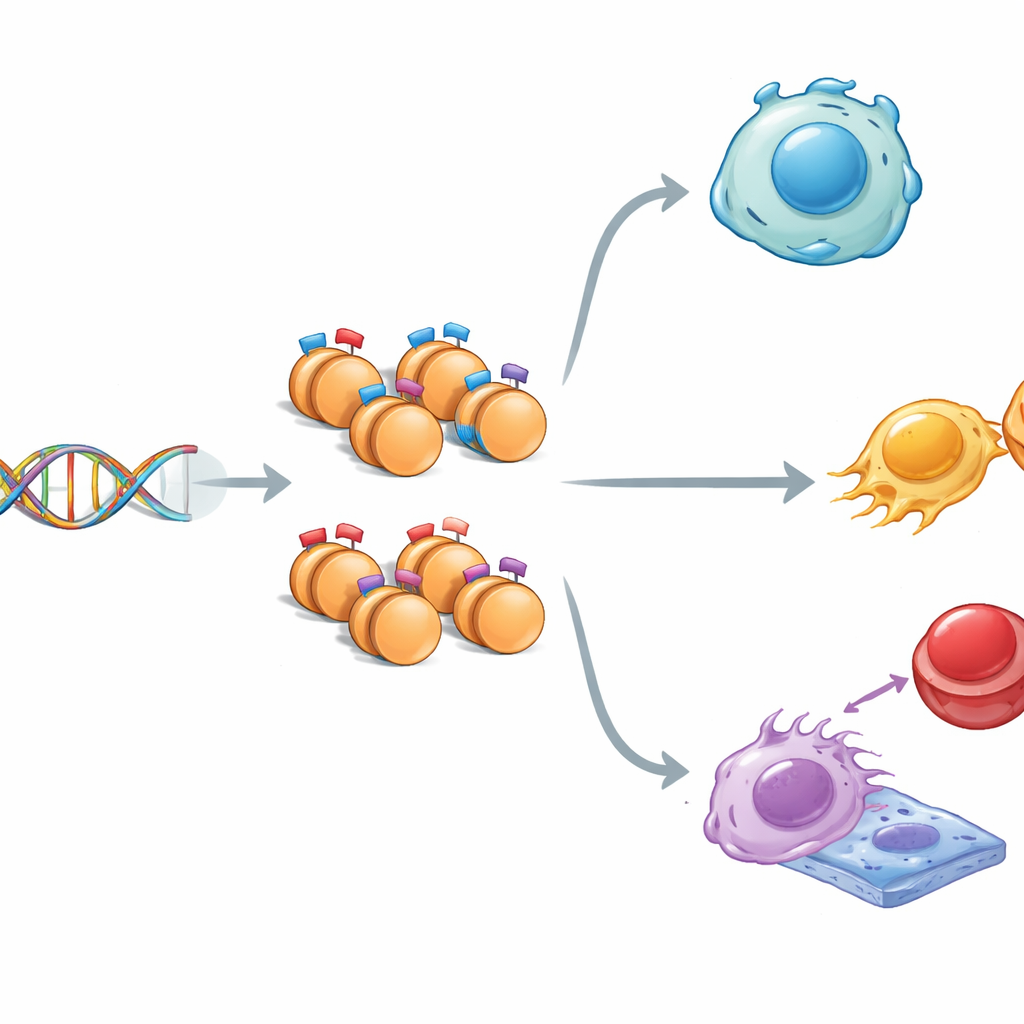
Die Geschichte von zwei gegensätzlichen Markierungen
Im Zellkern ist die DNA um Proteintrommeln gewickelt, die Histone genannt werden. Diese Histone können Signale tragen, die entweder die Genaktivität fördern („Go“) oder unterdrücken („Stop“). Manchmal sitzen beide Signaltypen am selben Ort und erzeugen einen sogenannten „bivalenten“ Zustand — Gene werden in einem Bereitschaftsmodus gehalten. Die Forschenden kartierten in Maus-embryonalen Stammzellen, die fast jedes Gewebe bilden können, drei zentrale Histonmarken im Genom. Sie stellten fest, dass Regionen mit gemischten Markierungen sich von einheitlich markierten Regionen unterschieden: sie waren etwas schmaler, reichhaltiger an den DNA-Basen G und C und evolutionär stärker konserviert, was darauf hindeutet, dass diese einsatzbereiten DNA-Strecken besonders wichtig und sorgfältig geschützt sind.
Bereitstehende Schalter für Entwicklung und Krankheit
Als das Team diese markierten Regionen mit benachbarten Genen verknüpfte, zeigte sich ein Muster. Gene, die durch gemischte Histonsignale markiert waren, wurden meist nur mäßig exprimiert und waren stark in frühzeitige Entwicklungsprozesse sowie in die Entscheidung von Stammzellen, flexibel zu bleiben oder sich zu spezialisieren, eingebunden. Signalwege wie Hippo, MAPK, Wnt und TGF-beta — zentrale Kommunikationskreise für Wachstum und Gewebebildung — waren stark vertreten. Einige bivalent markierte Gene wurden auch mit Krebs in Verbindung gebracht, was darauf hindeutet, dass dasselbe bereitstehende Kontrollsystem, das gesunde Entwicklung steuert, in Krankheiten missbraucht werden kann. Insgesamt wirken gemischte Markierungen wie fein justierbare Dimmer-Schalter, die Genen eine subtile Grundaktivität verleihen und sie zugleich bereit halten, bei eintreffenden Signalen hoch- oder heruntergefahren zu werden.
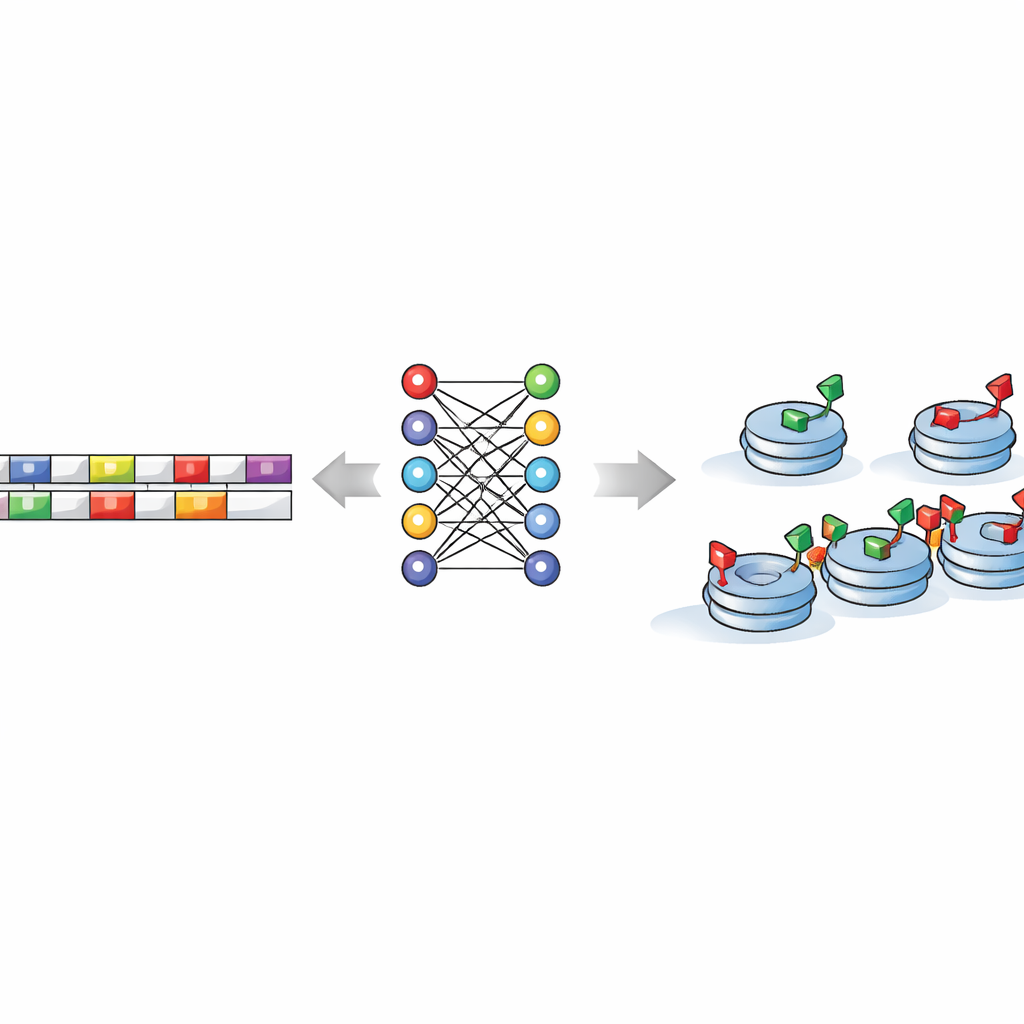
Maschinen beibringen, versteckte DNA-Muster zu lesen
Kernfrage der Studie ist, ob die DNA-Sequenz selbst Anweisungen dafür enthält, wo diese Bereitschaftszustände entstehen sollen. Um das zu prüfen, fütterten die Forschenden kurze DNA-Abschnitte — zerlegt in alle möglichen kleinen „Wörter“ von wenigen Basen — in eine Reihe von Machine-Learning- und Deep-Learning-Modellen. Diese Algorithmen lernten, Regionen mit gemischten Markierungen von solchen mit nur aktivierenden oder nur repressiven Markierungen zu unterscheiden, oft mit hoher Genauigkeit. Entscheidenderweise scheiterten die Modelle, wenn die DNA-Buchstaben zufällig durchmischt wurden, was zeigt, dass das echte Genom authentische prädiktive Signale trägt und nicht bloß zufälliges Rauschen. Das bedeutet, dass ein Computer allein aus dem DNA-Text, ohne experimentelle Messungen, vorhersagen kann, wo die Zelle wahrscheinlich diese gemischten Histonmarken anbringt.
Sequenzmotive als molekulare Wegweiser
Beim Blick in die Modelle entdeckten die Autorinnen und Autoren eine Handvoll kurzer DNA-Motive — wiederkehrende Buchstabenmuster — die besonders informativ waren. Einige, wie Sequenzen, die TCTGAA und TCACAG ähneln, deckten sich mit bekannten Bindungsstellen von zentralen Stammzellregulatoren wie OCT4, SOX2, ESRRB und einem Faktor namens TCFCP2l1. Andere neigten dazu, sich nahe den Rändern bivalenter Regionen zu häufen, was darauf hindeutet, dass bestimmte Motive helfen könnten, die Grenzen dieser bereitstehenden Chromatinzonen zu setzen. Unterschiedliche Kombinationen und Platzierungen von Motiven unterschieden eine Klasse gemischter Markierungen von einer anderen, was impliziert, dass jede Form der Bivalenz ihre eigene „Grammatik“ von Sequenzregeln hat, auch wenn viele derselben regulatorischen Proteine geteilt werden.
Was das für Stammzellen und darüber hinaus bedeutet
Kurz gesagt zeigt die Studie, dass DNA nicht nur eine Liste von Genen ist; sie enthält auch eingebettete Anweisungen darüber, wie fest diese Gene verpackt sein sollen und wie bereit sie sind zu reagieren. In embryonalen Stammzellen helfen spezifische kurze DNA-Muster dabei, Proteinfaktoren zu rekrutieren und Regionen zu formen, in denen gegensätzliche Histonmarken koexistieren und Entwicklungsgene auf einer scharfen Klinge zwischen An und Aus balancieren. Indem die Autorinnen und Autoren Machine Learning und Deep Learning nutzen, um diesen verborgenen Code zu lesen, liefern sie sowohl ein praktisches Werkzeug zur Vorhersage epigenetischer Zustände aus der Sequenz als auch ein klareres Bild davon, wie Zellen in der frühen Entwicklung Flexibilität in ihr Genom programmieren — und wie diese Programmierung in Krankheiten fehlgeleitet werden kann.
Zitation: Zhao, X., Wu, J., Che, Y. et al. Machine and Deep Learning Reveal Sequence Determinants Encoding Bivalent Histone Modifications. Commun Biol 9, 491 (2026). https://doi.org/10.1038/s42003-026-09962-8
Schlüsselwörter: bivalenter Chromatinzustand, Histonmodifikationen, embryonale Stammzellen, DNA-Sequenzmotive, Machine Learning in der Genomik