Clear Sky Science · zh
使用小型语言模型和人类表型本体(HPO)从常规病历中自动表型化眼科疾病
为什么更智能地阅读眼科医生笔记很重要
每次就诊都会产生一封包含大量关于患者眼部观察的信件或报告。这些笔记对于护理至关重要,但它们以自由文本形式书写,常常使用不同语言,并且每位医生的用词各不相同。这使得跨诊所汇总信息、建立大型研究登记库或快速找到具有相似问题的患者变得困难。本研究展示了如何通过精心设计的人工智能(AI)系统,自动将这些杂乱的叙述转化为干净、标准化的眼部发现列表——而无需将敏感的患者数据发送到云端。
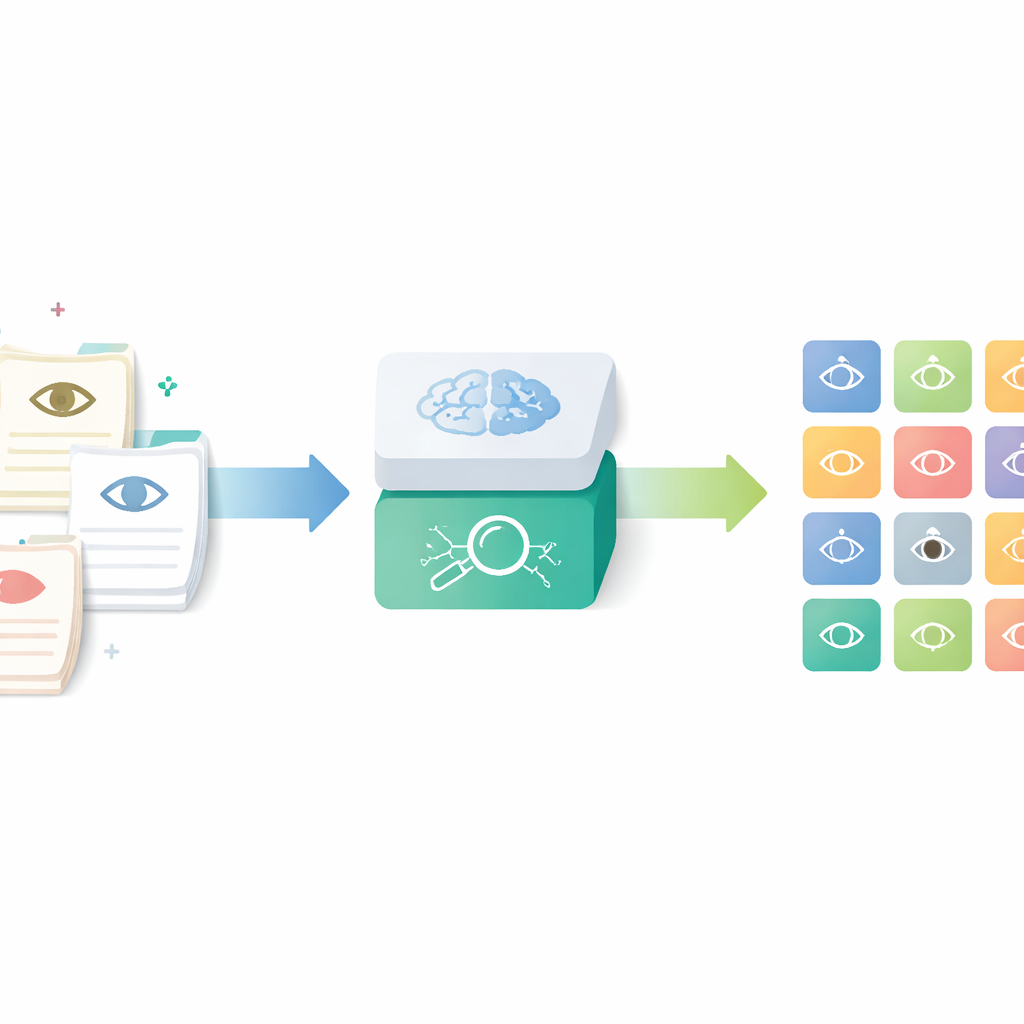
把日常笔记变成结构化数据
研究人员聚焦于一种称为人类表型本体(Human Phenotype Ontology,HPO)的工具,这是一个全球性的、对医学特征(包括眼科特征)进行精确定义的目录。研究者没有依赖医生手动查找和分配这些代码——这既耗时又不一致——而是构建了一个AI管道,能够读取常规眼科信件并输出对应的标准化术语。目标是在捕捉真实临床笔记中丰富细节的同时,使结果可用于研究、质量控制和多中心登记库。
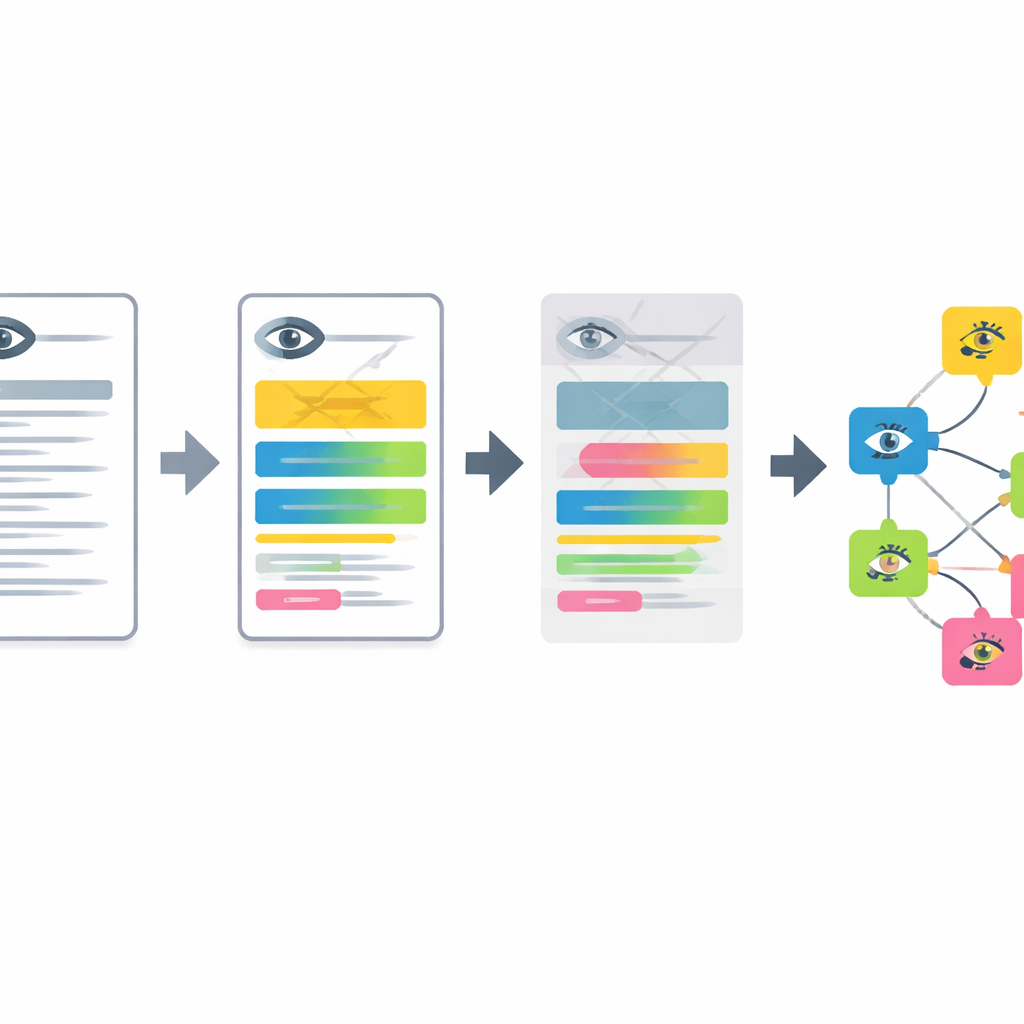
从文本到眼部发现的分步流程
该管道主要有四个阶段。首先,经匿名化的德文眼科病历由经过示例提示调优的小型语言模型翻译成英文。第二,系统将较长的描述拆分为短段落,每段描述眼前段或后段的单一特征。第三,它过滤掉正常发现并识别出被明确排除的疾病,只保留真正的问题。最后,每个剩余段落被转换为数学“嵌入向量”,并与扩展的多语种人类表型本体中的最接近条目进行匹配,从而得出具体且标准化的眼科表型术语。
教会系统眼科领域的语言
由于许多高度特异的眼病或表述方式在标准目录中缺失,团队为其诊所建立了本地同义词列表。每当系统为一段文本选择了错误术语时,专家会进行纠正并将该短语作为正确编码的新同义词添加进来。这种“专家在环”的过程在大约10,000份病历上重复进行。尚未存在于全球本体中的新眼科表型则被提交回国际人类表型本体联盟,帮助改进共享的标准,造福未来用户。
AI与人类专家的契合度如何
为评估性能,研究人员随机挑选了175份真实病历,由一名有经验的眼科医生手工用本体术语注释。平均来看,人类在每封信中发现2.53个相关眼部特征,而AI产生了2.52个——几乎相同。在人类识别的342个术语中,系统检索到了341个。关键准确性指标表现良好:AI与人工术语集合的重叠(Jaccard相似度)约为三分之二,正确性与完整性的平衡(F1分数)约为0.80,可与其他医疗领域的先进工具相媲美。剩余大多数错误发生在所需的眼科术语尚未存在于本体的情况下。
在保持数据隐私的同时串联信息
该方法的一个显著特点是其完全在本地医院硬件上运行,有助于诊所遵守严格的数据保护规则,同时释放病历的价值。通过将自由文本笔记转换为不再包含姓名或直接标识符的标准化代码,系统支持更安全的登记库和研究数据共享。其模块化设计允许其他医院通过调整提示词和扩展同义词列表来适配各自的用语和缩写,而无需重新训练大型AI模型。
这对患者和眼科研究可能意味着什么
对于患者而言,这类自动表型化可能意味着对罕见疾病模式的更早识别,治疗可以更好地进行匹配并在多中心间进行研究。对于医生和研究人员,它承诺带来更快的病历审查、更完整的登记库以及更少的手动编码时间。作者总结道:一个以可信医学本体为中心、并针对本地诊所语言进行调优的检索型AI管道,能够准确地将日常眼科笔记翻译成结构化、可直接用于研究的数据,为在常规眼科护理中更广泛地应用AI铺平了道路。
引用: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
关键词: 眼科学, 临床文本挖掘, 表型识别, 医学本体, 健康数据互操作性