Clear Sky Science · sv
Automatiserad fenotypning av oftalmologiska sjukdomar från rutinmässiga medicinska journaler med små språkmodeller och Human Phenotype Ontology (HPO)
Varför smartare tolkning av ögonläkares anteckningar spelar roll
Varje besök hos en ögonläkare genererar ett brev eller en rapport fylld med iakttagelser om patientens ögon. Dessa anteckningar är avgörande för vården, men de skrivs i fri text, ofta på olika språk och med varje läkare som använder sitt eget ordval. Det gör det svårt att kombinera information mellan kliniker, bygga stora forskningsregister eller snabbt hitta patienter med liknande problem. Denna studie visar hur ett omsorgsfullt utformat artificiellt intelligenssystem (AI) automatiskt kan förvandla dessa ostrukturerade berättelser till en ren, standardiserad lista över ögonfynd—utan att skicka känsliga patientuppgifter till molnet.
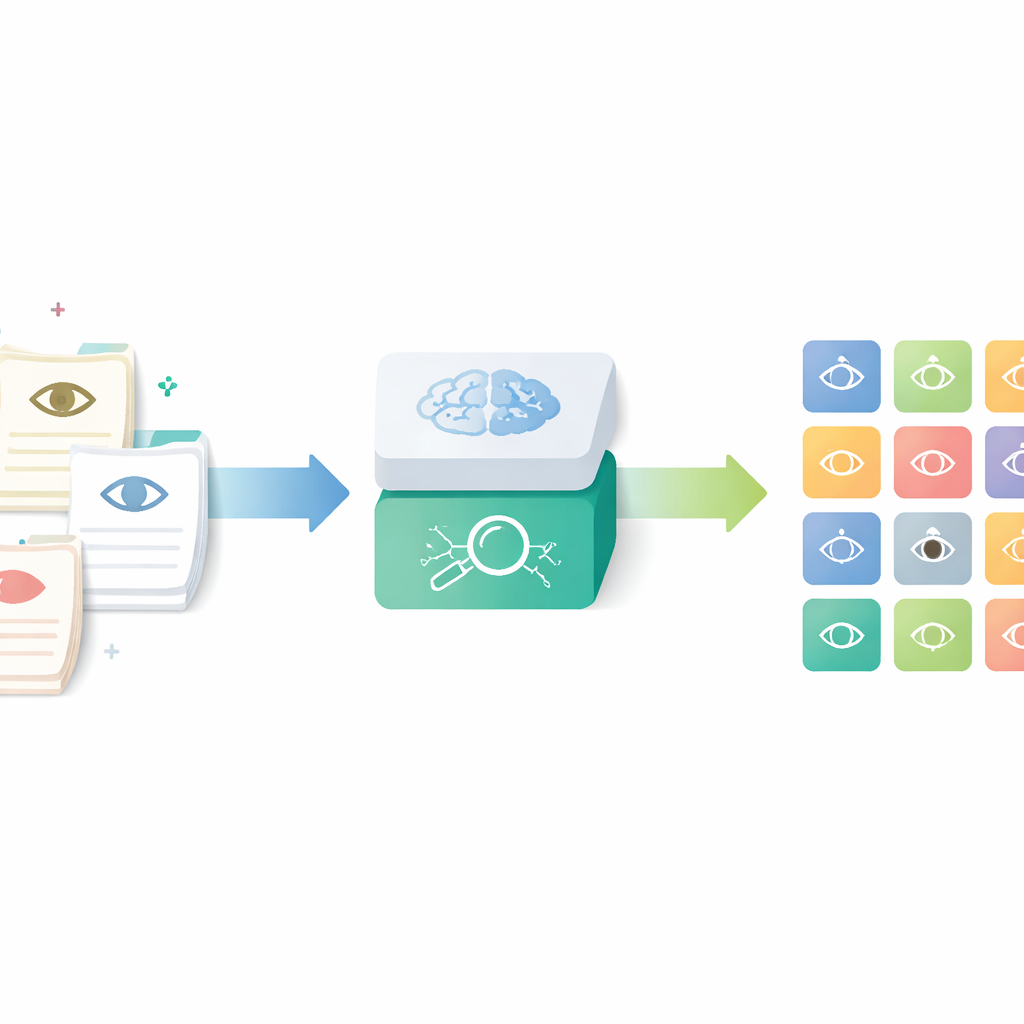
Att omvandla vardagliga anteckningar till strukturerad data
Forskarna koncentrerade sig på ett verktyg kallat Human Phenotype Ontology, en världsomspännande katalog över noggrant definierade medicinska kännetecken, inklusive ögonspecifika termer. Istället för att förlita sig på att läkare manuellt letar upp och tilldelar dessa koder—en tidskrävande och inkonsekvent process—byggde de en AI‑pipeline som läser rutinmässiga oftalmologibrev och ger motsvarande standardiserade termer. Målet var att fånga den rika detaljrikedomen i verkliga kliniska anteckningar samtidigt som resultaten gjordes användbara för forskning, kvalitetskontroll och flercenterregister.
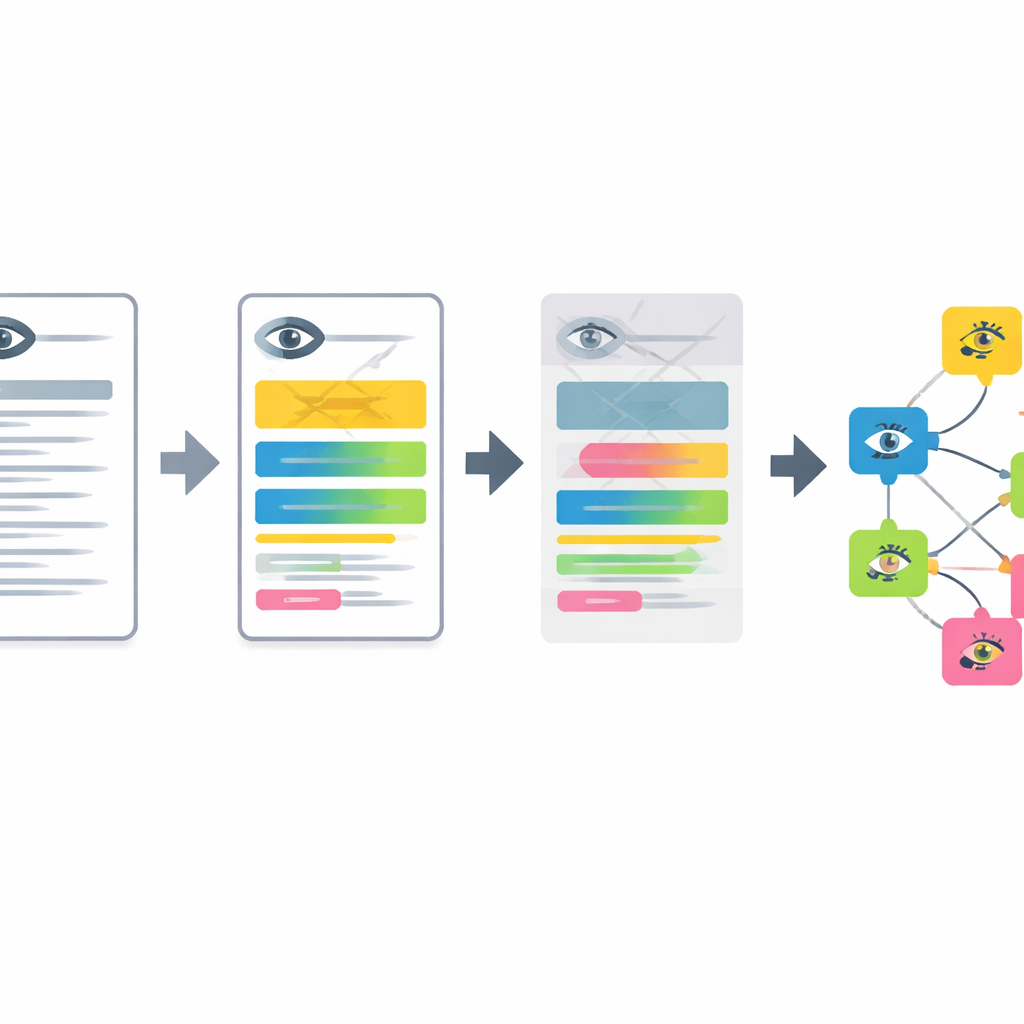
Steg‑för‑steg: från text till ögonfynd
Pipelinen fungerar i fyra huvudstadier. Först översätts anonymiserade ögonkliniksanteckningar skrivna på tyska till engelska av en kompakt språkmodell som finjusterats med exempelprompter. Därefter delar systemet upp längre beskrivningar i korta segment, där varje segment beskriver ett enskilt fynd i ögats främre eller bakre delar. Tredje steget filtrerar bort normala fynd och känner igen när en sjukdom uttryckligen utesluts, så att endast verkliga problem behålls. Slutligen omvandlas varje kvarvarande segment till en matematisk ”embedding” och matchas mot den närmaste posten i en utökad, flerspråkig version av Human Phenotype Ontology, vilket ger en specifik, standardiserad ögonfenotypskod.
Att lära systemet ögonavdelningens språk
Eftersom många mycket specifika ögonsjukdomar eller uttryckssätt saknades i den standardiserade katalogen byggde teamet en lokal synonymlista anpassad till deras klinik. När systemet valde fel term för en textbit korrigerade experter det och lade till uttrycket som en ny synonym för rätt kod. Denna "expert‑i‑loopen"‑process upprepades på ungefär 10 000 medicinska rapporter. Nya ögonfenotyper som ännu inte fanns i den globala ontologin föreslogs tillbaka till det internationella Human Phenotype Ontology‑konsortiet, vilket hjälpte till att förbättra den gemensamma standarden för framtida användare.
Hur väl AI överensstämde med mänskliga experter
För att testa prestanda valde forskarna slumpmässigt ut 175 verkliga patientjournaler och lät en erfaren ögonläkare annotera dem för hand med ontologitermer. I genomsnitt fann människorna 2,53 relevanta ögonfynd per brev, medan AI:n gav 2,52—nästan identiskt. Av 342 mänskligt identifierade termer hämtade systemet 341. Nyckelmått för noggrannhet var starka: överlappet mellan AI‑ och människotermseten (Jaccard‑likhet) var ungefär två tredjedelar, och balansen mellan korrekthet och fullständighet (F1‑score) var cirka 0,80, jämförbart med toppmoderna verktyg inom andra medicinska domäner. De flesta kvarstående fel uppstod när den nödvändiga ögonfenotypen helt enkelt ännu inte fanns i ontologin.
Bevara integriteten samtidigt som man länkar samman information
En framträdande egenskap hos detta tillvägagångssätt är att det körs helt på lokal sjukhushårdvara, vilket hjälper kliniker att följa strikta dataskyddsregler samtidigt som värdet i deras journaler frigörs. Genom att omvandla fritextsanteckningar till standardiserade koder som inte längre innehåller namn eller direkta identifierare stödjer systemet säkrare datadelning för register och forskning. Dess modulära design gör det möjligt för andra sjukhus att anpassa det till sitt eget ordval och sina förkortningar genom att justera prompter och utöka synonymlistor, utan att behöva träna om stora AI‑modeller.
Vad detta kan betyda för patienter och ögonforskning
För patienter kan denna typ av automatiserad fenotypning innebära att sällsynta sjukdomsmönster upptäcks tidigare och att behandlingar kan matchas och studeras bättre över center. För läkare och forskare lovar det snabbare journalgenomgångar, mer fullständiga register och färre timmar åt manuell kodning. Författarna drar slutsatsen att en omsorgsfullt förankrad, retrieval‑baserad AI‑pipeline—byggd kring en betrodd medicinsk ontologi och anpassad till en lokal kliniks språk—kan översätta vardagliga oftalmologiska anteckningar till strukturerad, forskningsfärdig data med hög noggrannhet, vilket banar väg för bredare användning av AI i rutinmässig ögonvård.
Citering: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Nyckelord: ögonläkare, klinisk textutvinning, fenotypning, medicinska ontologier, interoperabilitet för hälsodata