Clear Sky Science · nl
Geautomatiseerde fenotypering van oftalmologische aandoeningen uit routinematige medische dossiers met behulp van kleine taalmodellen en de Human Phenotype Ontology (HPO)
Waarom slimmer lezen van oogartsenrapporten ertoe doet
Elke afspraak bij de oogarts levert een brief of rapport op dat vol staat met observaties over de ogen van de patiënt. Deze aantekeningen zijn cruciaal voor de zorg, maar ze zijn in vrije tekst geschreven, vaak in verschillende talen en met iedere arts die zijn eigen bewoording gebruikt. Dat maakt het lastig om informatie over klinieken heen te combineren, grote onderzoeksregisters op te bouwen of snel patiënten met vergelijkbare problemen te vinden. Deze studie laat zien hoe een zorgvuldig ontworpen kunstmatig intelligentiesysteem automatisch deze rommelige narratieven kan omzetten in een nette, gestandaardiseerde lijst van oogbevindingen—zonder gevoelige patiëntgegevens naar de cloud te sturen.
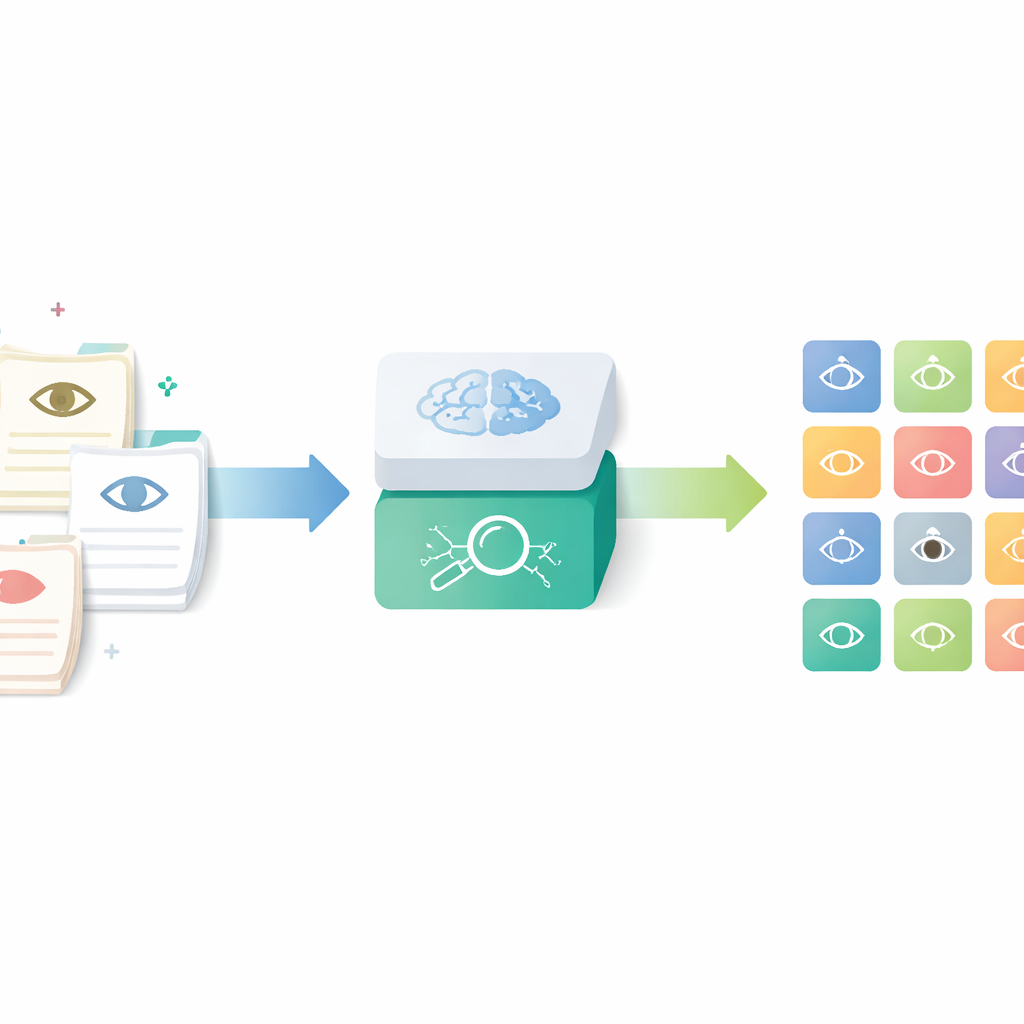
Dagelijkse aantekeningen omzetten in gestructureerde data
De onderzoekers richtten zich op een hulpmiddel genaamd de Human Phenotype Ontology, een wereldwijd register van nauwkeurig gedefinieerde medische kenmerken, inclusief die van het oog. In plaats van artsen te laten zoeken en handmatig deze codes toe te wijzen—een tijdrovend en inconsistente proces—bouwden ze een AI-pijplijn die routinematige oftalmologiebrieven leest en de bijbehorende gestandaardiseerde termen oplevert. Het doel was de rijke details in echte klinische notities vast te leggen en tegelijk de resultaten bruikbaar te maken voor onderzoek, kwaliteitscontrole en multicenterregisters.
Stapsgewijze route van tekst naar oogbevindingen
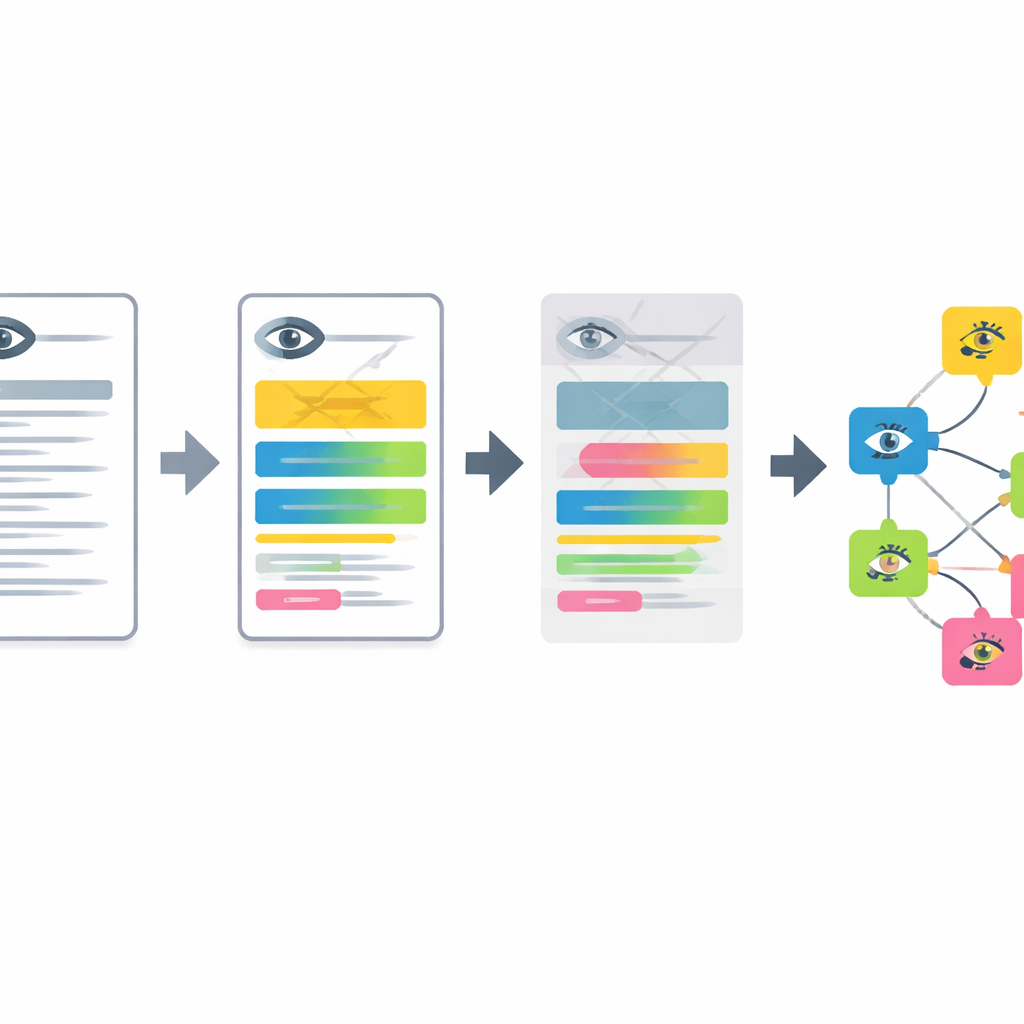
De pijplijn werkt in vier hoofdfasen. Eerst worden geanonimiseerde oogklinieknotities die in het Duits zijn geschreven vertaald naar het Engels door een compact taalmodel dat is afgestemd met voorbeeldprompts. Vervolgens knipt het systeem langere beschrijvingen in korte segmenten, elk met één kenmerk van het voorste of achterste deel van het oog. Derde stap is het filteren van normale bevindingen en het herkennen van wanneer een ziekte expliciet wordt uitgesloten, zodat alleen echte problemen overblijven. Ten slotte wordt elk overgebleven segment omgezet in een wiskundige "embedding" en gekoppeld aan de dichtstbijzijnde invoer in een uitgebreide, meertalige versie van de Human Phenotype Ontology, wat resulteert in een specifieke, gestandaardiseerde oogfenotype-term.
Het systeem leren de taal van oogzorg te spreken
Omdat veel sterk specifieke oogaandoeningen of manieren om ze te verwoorden ontbraken in het standaardregister, bouwde het team een lokale synoniemenlijst die op hun kliniek was afgestemd. Telkens wanneer het systeem de verkeerde term aan een tekstgedeelte koppelde, corrigeerden experts dit en voegden ze die formulering toe als nieuw synoniem voor de juiste code. Dit "expert-in-the-loop"-proces werd herhaald op ongeveer 10.000 medische rapporten. Nieuwe oogfenotypes die nog niet bestonden in de wereldwijde ontologie werden teruggepresenteerd aan het internationale Human Phenotype Ontology-consortium, wat hielp de gedeelde standaard voor toekomstige gebruikers te verbeteren.
Hoe goed de AI overeenkwam met menselijke experts
Om de prestaties te testen selecteerden de onderzoekers willekeurig 175 echte patiëntendossiers en liet een ervaren oogarts deze handmatig annoteren met ontologietermen. Gemiddeld vonden mensen 2,53 relevante oogkenmerken per brief, terwijl de AI 2,52 produceerde—bijna identiek. Van de 342 door mensen geïdentificeerde termen haalde het systeem er 341 terug. Belangrijke nauwkeurigheidsmaatstaven waren sterk: de overlap tussen AI- en menselijke termensets (Jaccard-gelijkheid) bedroeg ongeveer twee derde, en de balans tussen juistheid en volledigheid (F1-score) was ongeveer 0,80, vergelijkbaar met state-of-the-art tools in andere medische domeinen. De meeste resterende fouten deden zich voor wanneer de benodigde oogterm simpelweg nog niet in de ontologie bestond.
Gegevens privé houden terwijl verbanden worden gelegd
Een opvallend kenmerk van deze aanpak is dat deze volledig op lokale ziekenhuishardware draait, waardoor klinieken kunnen voldoen aan strikte regels voor gegevensbescherming en toch de waarde van hun dossiers kunnen ontsluiten. Door vrijetekstnotities om te zetten in gestandaardiseerde codes die geen namen of directe identificatoren meer bevatten, ondersteunt het systeem veiliger gegevensdeling voor registers en onderzoek. Het modulaire ontwerp stelt andere ziekenhuizen in staat het aan te passen aan hun eigen bewoordingen en afkortingen door prompts aan te passen en synoniemenlijsten uit te breiden, zonder grootschalige AI-modellen opnieuw te hoeven trainen.
Wat dit kan betekenen voor patiënten en oogonderzoek
Voor patiënten kan dit soort geautomatiseerde fenotypering betekenen dat zeldzame ziektepatronen eerder worden herkend en dat behandelingen beter kunnen worden afgestemd en bestudeerd over centra heen. Voor artsen en onderzoekers belooft het snellere dossiercontroles, meer complete registers en minder uren besteed aan handmatige codering. De auteurs concluderen dat een zorgvuldig onderbouwde, retrieval-gebaseerde AI-pijplijn—gebouwd rond een vertrouwde medische ontologie en afgestemd op de taal van een lokale kliniek—dagelijkse oftalmologierapporten nauwkeurig kan vertalen naar gestructureerde, onderzoeksklare data, en zo de weg vrijmaakt voor breder gebruik van AI in routinematige oogzorg.
Bronvermelding: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Trefwoorden: oftalmologie, klinische tekstmining, fenotypering, medische ontologieën, interoperabiliteit van gezondheidsgegevens