Clear Sky Science · pt
Fenotipagem automatizada de doenças oftalmológicas a partir de prontuários rotineiros usando pequenos modelos de linguagem e a Ontologia de Fenótipo Humano (HPO)
Por que uma leitura mais inteligente das anotações dos oftalmologistas importa
Cada consulta com um oftalmologista gera uma carta ou relatório repleto de observações sobre os olhos do paciente. Essas anotações são vitais para o cuidado, mas são escritas em texto livre, frequentemente em idiomas diferentes e com cada médico usando sua própria linguagem. Isso dificulta combinar informações entre clínicas, construir grandes registros para pesquisa ou localizar rapidamente pacientes com problemas semelhantes. Este estudo mostra como um sistema de inteligência artificial (IA) cuidadosamente projetado pode transformar automaticamente essas narrativas desorganizadas em uma lista padronizada e limpa de achados oftalmológicos — sem enviar dados sensíveis dos pacientes para a nuvem.
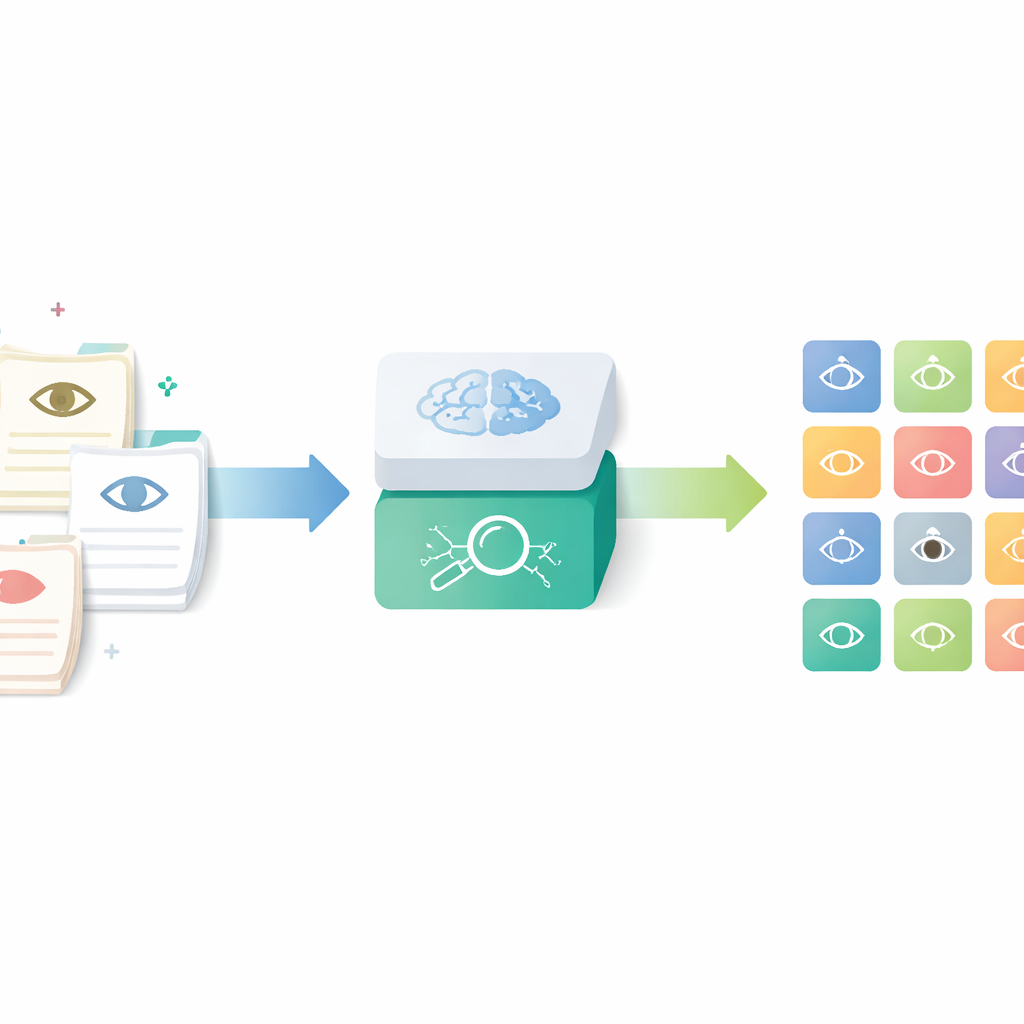
Transformando anotações do dia a dia em dados estruturados
Os pesquisadores concentraram-se em uma ferramenta chamada Human Phenotype Ontology, um catálogo mundial de características médicas definidas com precisão, incluindo as do olho. Em vez de depender que os médicos procurem e atribuam esses códigos manualmente — um processo demorado e inconsistente — eles construíram um pipeline de IA que lê cartas de oftalmologia rotineiras e produz os termos padronizados correspondentes. O objetivo foi capturar o detalhe rico das anotações clínicas reais enquanto torna os resultados utilizáveis para pesquisa, controle de qualidade e registros multicêntricos.
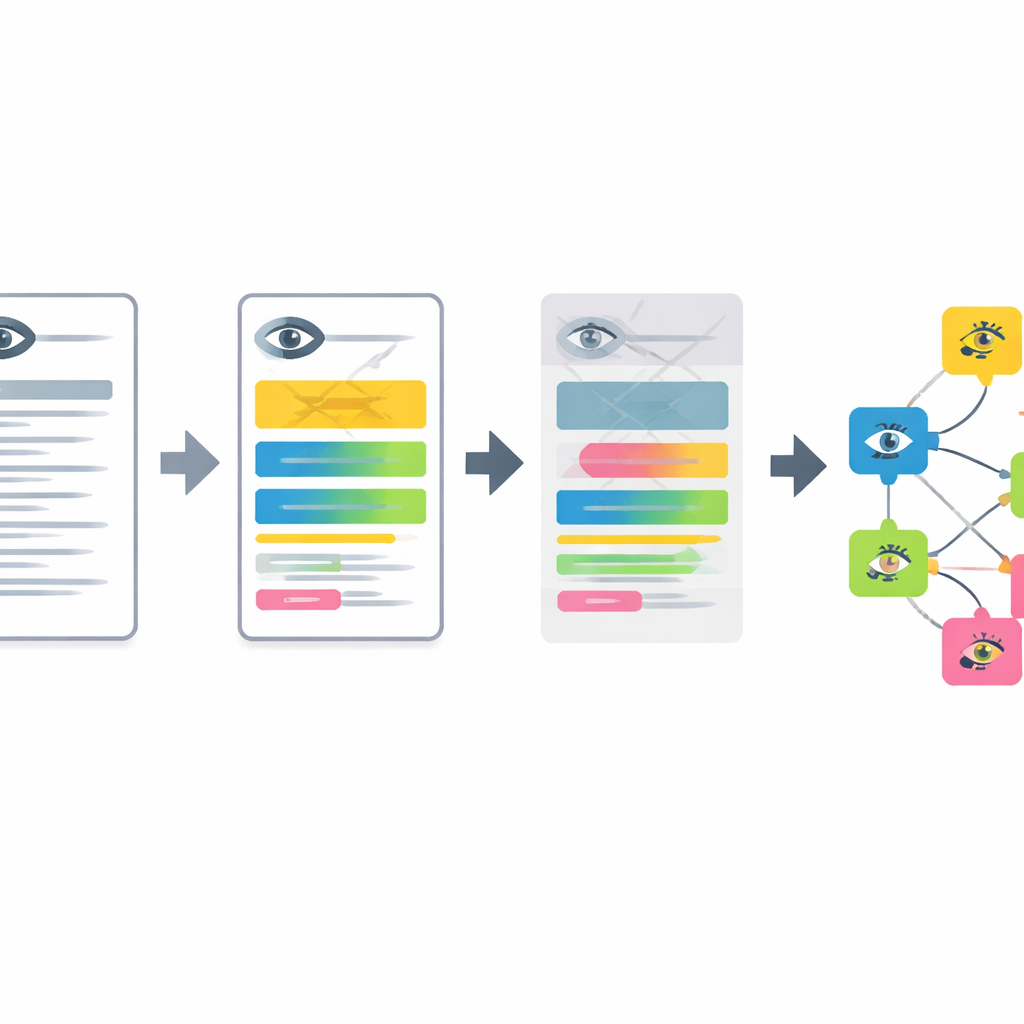
Jornada passo a passo do texto para os achados oculares
O pipeline funciona em quatro etapas principais. Primeiro, notas anonimizadas de clínicas oftalmológicas escritas em alemão são traduzidas para o inglês por um modelo de linguagem compacto afinado com prompts de exemplo. Em segundo lugar, o sistema divide descrições longas em segmentos curtos, cada um descrevendo uma única característica da parte anterior ou posterior do olho. Terceiro, ele filtra achados normais e reconhece quando uma doença é explicitamente descartada, de modo que apenas problemas reais são mantidos. Por fim, cada segmento restante é transformado em um “embedding” matemático e comparado com a entrada mais próxima em uma versão ampliada e multilíngue da Human Phenotype Ontology, resultando em um termo de fenótipo ocular específico e padronizado.
Ensinando ao sistema a linguagem do cuidado ocular
Como muitas condições oculares altamente específicas ou modos de expressá-las estavam ausentes do catálogo padrão, a equipe construiu uma lista local de sinônimos adaptada à sua clínica. Sempre que o sistema escolhia o termo errado para um trecho de texto, especialistas o corrigiam e adicionavam a frase como um novo sinônimo para o código correto. Esse processo de “especialista no loop” foi repetido em cerca de 10.000 relatórios médicos. Novos fenótipos oculares que ainda não existiam na ontologia global foram propostos de volta ao consórcio internacional da Human Phenotype Ontology, ajudando a aprimorar o padrão compartilhado para usuários futuros.
Quão bem a IA concordou com especialistas humanos
Para testar o desempenho, os pesquisadores selecionaram aleatoriamente 175 prontuários reais de pacientes e um oftalmologista experiente os anotou manualmente com termos da ontologia. Em média, os humanos encontraram 2,53 características oculares relevantes por carta, enquanto a IA produziu 2,52 — praticamente idêntico. Das 342 entradas identificadas pelos humanos, o sistema recuperou 341. As medidas-chave de acurácia foram fortes: a sobreposição entre os conjuntos de termos da IA e dos humanos (similaridade de Jaccard) foi de cerca de dois terços, e o equilíbrio entre correção e completude (pontuação F1) foi cerca de 0,80, comparável a ferramentas de ponta em outros domínios médicos. A maioria dos erros restantes ocorreu quando o termo ocular necessário simplesmente ainda não existia na ontologia.
Preservando a privacidade dos dados enquanto conecta as informações
Uma característica notável desta abordagem é que ela roda inteiramente em hardware local do hospital, ajudando as clínicas a cumprir regras rígidas de proteção de dados enquanto ainda desbloqueiam o valor de seus registros. Ao transformar notas em texto livre em códigos padronizados que não contêm mais nomes ou identificadores diretos, o sistema favorece o compartilhamento de dados mais seguro para registros e pesquisas. Seu design modular permite que outros hospitais o adaptem à sua própria terminologia e abreviaturas ajustando prompts e estendendo listas de sinônimos, sem a necessidade de re-treinar grandes modelos de IA.
O que isso pode significar para pacientes e pesquisa oftalmológica
Para os pacientes, esse tipo de fenotipagem automatizada pode significar que padrões raros de doença sejam reconhecidos mais cedo e que tratamentos possam ser melhor combinados e estudados entre centros. Para médicos e pesquisadores, promete revisões de prontuário mais rápidas, registros mais completos e menos horas gastas em codificação manual. Os autores concluem que um pipeline de IA baseado em recuperação, cuidadosamente fundamentado — construído em torno de uma ontologia médica confiável e afinado para a linguagem de uma clínica local — pode traduzir com precisão notas oftalmológicas do cotidiano em dados estruturados prontos para pesquisa, abrindo caminho para um uso mais amplo da IA no cuidado oftalmológico rotineiro.
Citação: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Palavras-chave: oftalmologia, mineração de texto clínico, fenotipagem, ontologias médicas, interoperabilidade de dados de saúde