Clear Sky Science · de
Automatisierte Phänotypisierung ophthalmologischer Erkrankungen aus routinemäßigen Krankenakten mithilfe kleiner Sprachmodelle und der Human Phenotype Ontology (HPO)
Warum ein intelligenteres Lesen von Augenarztberichten wichtig ist
Jeder Besuch beim Augenarzt erzeugt einen Brief oder Bericht voller Beobachtungen zum Auge des Patienten. Diese Notizen sind für die Versorgung unverzichtbar, werden aber als Freitext verfasst, häufig in unterschiedlichen Sprachen und mit individueller Wortwahl der jeweiligen Ärztin oder des jeweiligen Arztes. Das erschwert das Zusammenführen von Informationen über Kliniken hinweg, den Aufbau großer Forschungsregister oder das schnelle Auffinden von Patientinnen und Patienten mit ähnlichen Problemen. Diese Studie zeigt, wie ein sorgfältig gestaltetes System der künstlichen Intelligenz (KI) solche unstrukturierten Berichte automatisch in eine saubere, standardisierte Liste von Augenbefunden überführen kann — ohne sensible Patientendaten in die Cloud zu senden.
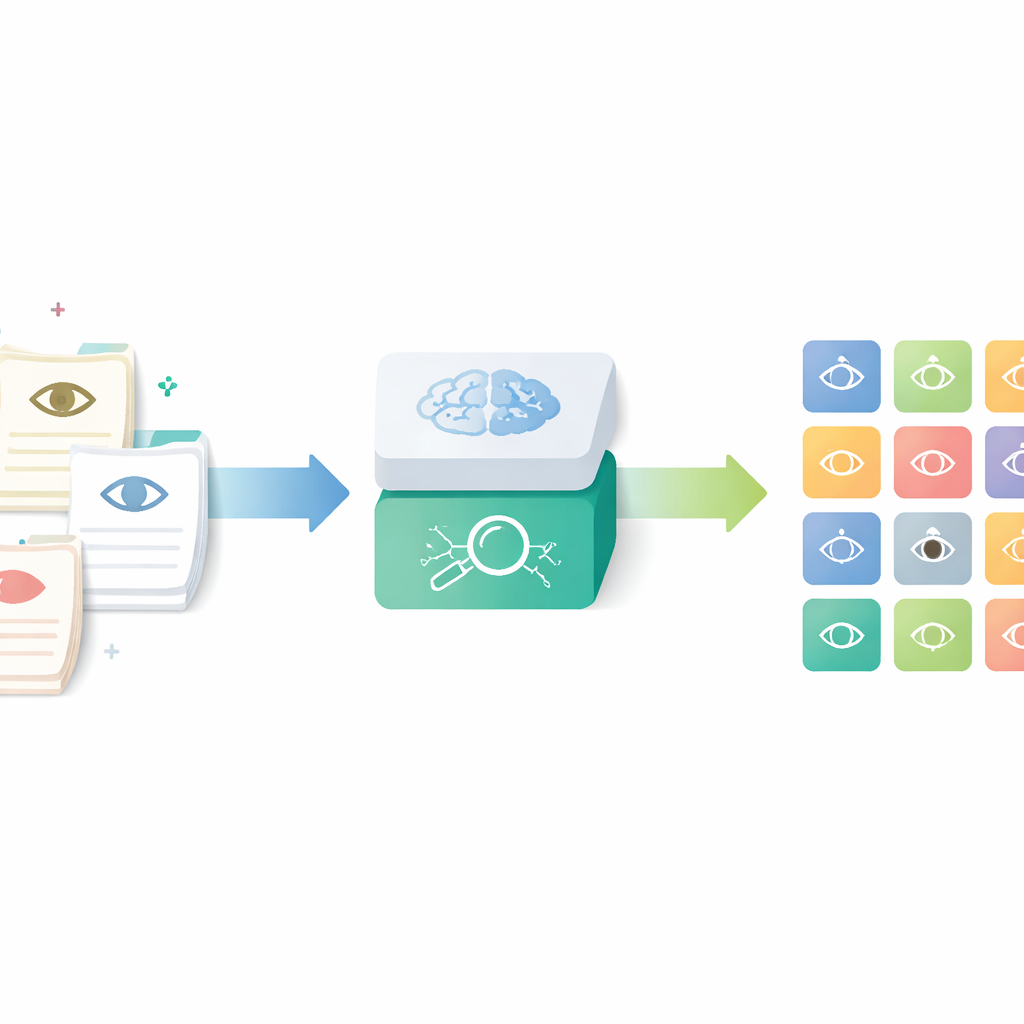
Alltägliche Berichte in strukturierte Daten verwandeln
Die Forschenden konzentrierten sich auf ein Werkzeug namens Human Phenotype Ontology, einen weltweit verwendeten Katalog genau definierter medizinischer Merkmale, einschließlich solcher des Auges. Anstatt Ärztinnen und Ärzte manuell Codes nachschlagen und zuweisen zu lassen — ein zeitaufwändiger und inkonsistenter Prozess — entwickelten sie eine KI‑Pipeline, die routinemäßige ophthalmologische Berichte liest und die passenden standardisierten Begriffe ausgibt. Ziel war es, die reichhaltigen Details in realen klinischen Notizen zu erfassen und gleichzeitig die Ergebnisse für Forschung, Qualitätskontrolle und multizentrische Register nutzbar zu machen.
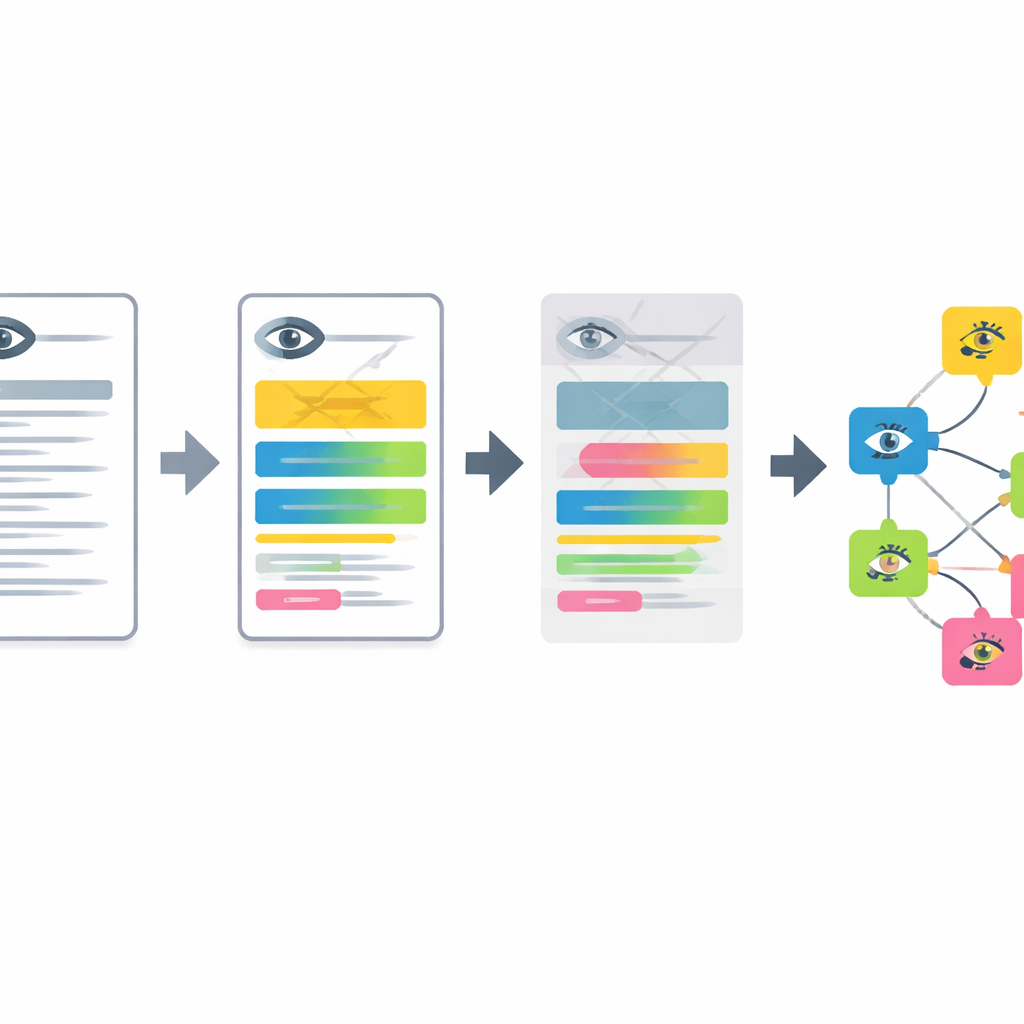
Schritt‑für‑Schritt von Text zu Augenbefunden
Die Pipeline arbeitet in vier Hauptphasen. Zuerst werden anonymisierte Augenarztberichte, die auf Deutsch verfasst sind, von einem kompakten Sprachmodell mithilfe abgestimmter Prompts ins Englische übersetzt. Zweitens teilt das System längere Beschreibungen in kurze Segmente auf, von denen jedes ein einzelnes Merkmal der vorderen oder hinteren Augenabschnitte beschreibt. Drittens werden normale Befunde herausgefiltert und Situationen erkannt, in denen eine Erkrankung ausdrücklich ausgeschlossen wird, sodass nur tatsächliche Auffälligkeiten verbleiben. Schließlich wird jedes verbleibende Segment in einen mathematischen „Embedding“-Vektor überführt und mit dem nächstliegenden Eintrag in einer erweiterten, mehrsprachigen Version der Human Phenotype Ontology abgeglichen, wodurch ein spezifischer, standardisierter Augenphänotyp‑Begriff entsteht.
Dem System die Sprache der Augenheilkunde beibringen
Da viele sehr spezifische Augenbefunde oder Formulierungsweisen im Standardkatalog fehlten, erstellte das Team eine lokale Synonymliste, die auf ihre Klinik zugeschnitten war. Immer wenn das System für einen Textabschnitt den falschen Begriff wählte, korrigierten Experten dies und fügten die Formulierung als neues Synonym für den richtigen Code hinzu. Dieser „Expert‑in‑the‑loop“-Prozess wurde an etwa 10.000 medizinischen Berichten wiederholt. Neue Augenphänotypen, die noch nicht im globalen Ontologie‑Katalog existierten, wurden dem internationalen Human Phenotype Ontology‑Konsortium vorgeschlagen und trugen so zur Verbesserung des gemeinsamen Standards für künftige Nutzer bei.
Wie gut die KI mit menschlichen Expertinnen und Experten übereinstimmte
Zur Leistungsbewertung wählten die Forschenden zufällig 175 echte Patientenakten aus und ließen sie von einem erfahrenen Augenarzt manuell mit Ontologiebegriffen annotieren. Im Mittel fanden Menschen 2,53 relevante Augenmerkmale pro Bericht, während die KI 2,52 ermittelte — nahezu identisch. Von 342 menschlich identifizierten Begriffen lieferte das System 341 zurück. Wichtige Genauigkeitsmaße waren stark: die Überlappung zwischen KI‑ und Menschentermmengen (Jaccard‑Ähnlichkeit) betrug etwa zwei Drittel, und das Gleichgewicht von Korrektheit und Vollständigkeit (F1‑Score) lag bei ungefähr 0,80, vergleichbar mit modernen Werkzeugen in anderen medizinischen Bereichen. Die meisten verbleibenden Fehler traten auf, weil der benötigte Augenbegriff schlicht noch nicht in der Ontologie existierte.
Daten privat halten und trotzdem Zusammenhänge erschließen
Ein bemerkenswertes Merkmal dieses Ansatzes ist, dass er vollständig auf lokaler Krankenhaus‑Hardware läuft, wodurch Kliniken helfen können, strenge Datenschutzanforderungen einzuhalten und gleichzeitig den Wert ihrer Aufzeichnungen nutzbar zu machen. Indem Freitextnotizen in standardisierte Codes überführt werden, die keine Namen oder direkten Identifikatoren mehr enthalten, unterstützt das System ein sichereres Teilen von Daten für Register und Forschung. Sein modularer Aufbau ermöglicht es anderen Krankenhäusern, es an eigene Formulierungen und Abkürzungen anzupassen, indem sie Prompts anpassen und Synonymlisten erweitern, ohne große KI‑Modelle neu trainieren zu müssen.
Was das für Patientinnen, Patienten und die Augenforschung bedeuten könnte
Für Patientinnen und Patienten könnte eine solche automatisierte Phänotypisierung bedeuten, dass seltene Krankheitsmuster früher erkannt werden und Behandlungen besser über Zentren hinweg verglichen und untersucht werden können. Für Ärztinnen, Ärzte und Forschende verspricht sie schnellere Aktenauswertungen, vollständigere Register und weniger Zeitaufwand für manuelle Kodierung. Die Autorinnen und Autoren kommen zu dem Schluss, dass eine sorgfältig fundierte, retrieval‑basierte KI‑Pipeline — aufgebaut um eine vertrauenswürdige medizinische Ontologie und auf die Sprache einer lokalen Klinik abgestimmt — Alltagsberichte der Ophthalmologie präzise in strukturierte, forschungsbereite Daten übersetzen kann und damit den Weg für einen breiteren Einsatz von KI in der routinemäßigen Augenversorgung ebnet.
Zitation: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Schlüsselwörter: Ophthalmologie, klinisches Text‑Mining, Phänotypisierung, medizinische Ontologien, Interoperabilität von Gesundheitsdaten