Clear Sky Science · fr
Phénotypage automatisé des maladies ophtalmologiques à partir des dossiers médicaux de routine en utilisant de petits modèles de langage et l’ontologie des phénotypes humains (HPO)
Pourquoi une lecture plus intelligente des notes des ophtalmologistes compte
Chaque consultation chez un ophtalmologiste donne lieu à une lettre ou un compte rendu fourmillant d’observations sur les yeux du patient. Ces notes sont vitales pour les soins, mais elles sont rédigées en texte libre, souvent en différentes langues et avec chaque médecin utilisant sa propre formulation. Cela rend difficile la consolidation des informations entre cliniques, la constitution de grands registres de recherche ou la recherche rapide de patients présentant des problèmes similaires. Cette étude montre comment un système d’intelligence artificielle (IA) soigneusement conçu peut automatiquement transformer ces récits désordonnés en une liste normalisée et claire d’anomalies oculaires — sans envoyer de données sensibles des patients dans le cloud.
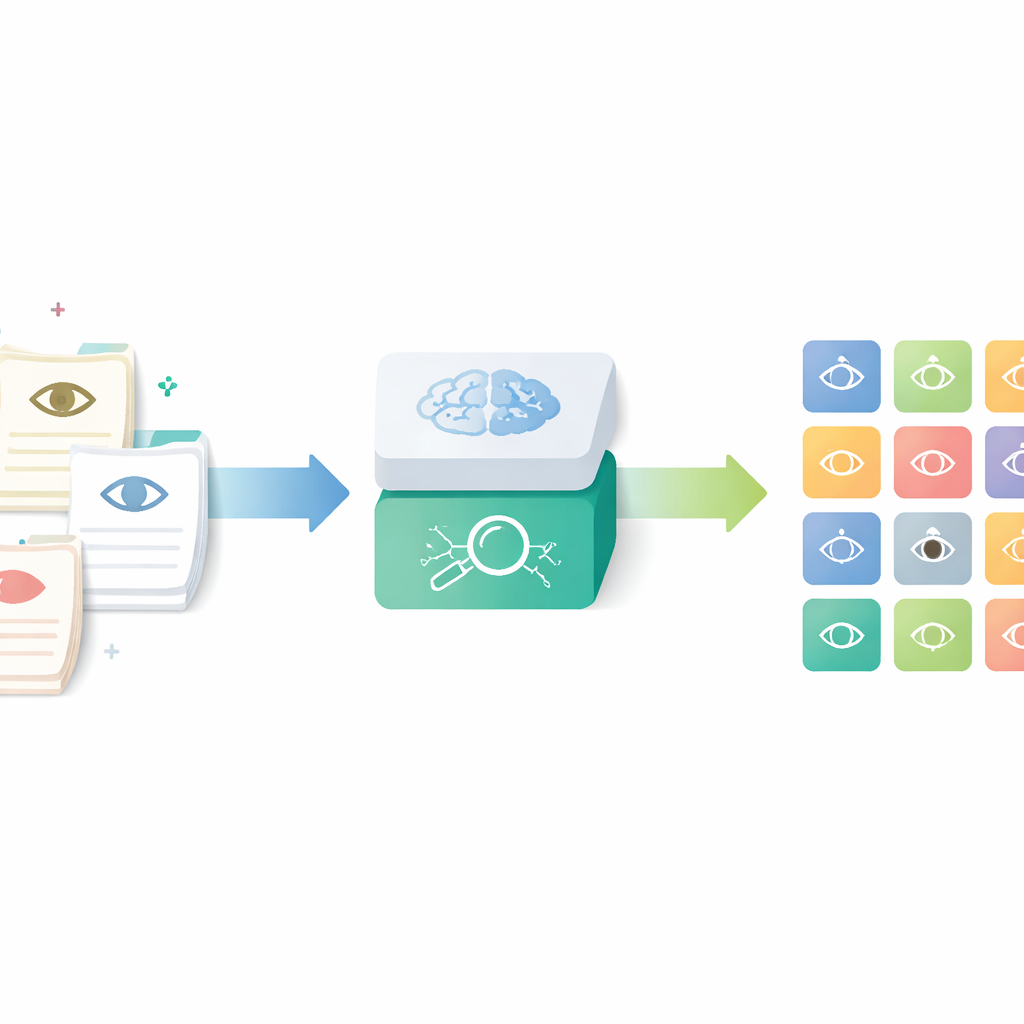
Transformer les notes quotidiennes en données structurées
Les chercheurs se sont concentrés sur un outil appelé Human Phenotype Ontology, un catalogue mondial de caractéristiques médicales précisément définies, y compris celles de l’œil. Plutôt que de compter sur les médecins pour rechercher et attribuer ces codes manuellement — un processus long et incohérent — ils ont construit une chaîne d’outils IA qui lit les lettres d’ophtalmologie de routine et produit les termes normalisés correspondants. L’objectif était de capturer la richesse des notes cliniques réelles tout en rendant les résultats exploitables pour la recherche, le contrôle qualité et les registres multi‑centres.
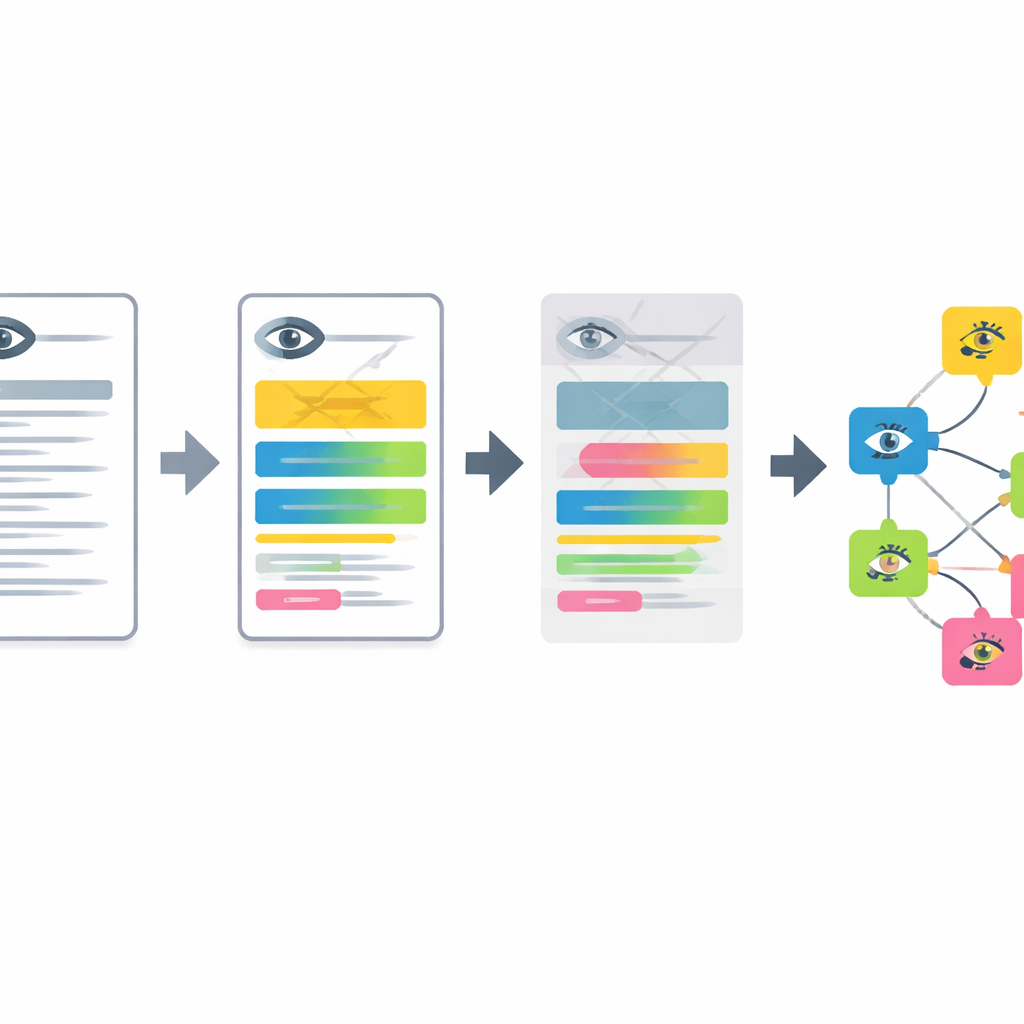
Parcours étape par étape du texte aux constatations oculaires
La chaîne fonctionne en quatre étapes principales. D’abord, des notes de clinique ophtalmologique anonymisées rédigées en allemand sont traduites en anglais par un petit modèle de langage adapté avec des exemples d’invite. Ensuite, le système découpe les descriptions longues en segments courts, chacun décrivant un seul signe de la partie antérieure ou postérieure de l’œil. Troisièmement, il filtre les constatations normales et reconnaît quand une maladie est explicitement exclue, de sorte que seuls les problèmes réels sont conservés. Enfin, chaque segment restant est transformé en une « embedding » mathématique et mis en correspondance avec l’entrée la plus proche dans une version multilingue étendue de l’Human Phenotype Ontology, produisant un terme phénotypique oculaire spécifique et normalisé.
Apprendre au système le langage des soins oculaires
Comme de nombreuses conditions oculaires très spécifiques ou formulations manquaient dans le catalogue standard, l’équipe a construit une liste locale de synonymes adaptée à leur clinique. Chaque fois que le système choisissait le mauvais terme pour un extrait de texte, des experts le corrigeaient et ajoutaient la tournure comme nouveau synonyme du code correct. Ce processus « expert‑in‑the‑loop » a été répété sur environ 10 000 comptes rendus médicaux. De nouveaux phénotypes oculaires qui n’existaient pas encore dans l’ontologie mondiale ont été proposés au consortium international de l’Human Phenotype Ontology, contribuant à améliorer la norme partagée pour les utilisateurs futurs.
À quel point l’IA s’accordait avec les experts humains
Pour évaluer les performances, les chercheurs ont sélectionné au hasard 175 dossiers patients réels et ont demandé à un ophtalmologiste expérimenté de les annoter manuellement avec des termes de l’ontologie. En moyenne, les humains ont trouvé 2,53 signes oculaires pertinents par lettre, tandis que l’IA en a produit 2,52 — presque identique. Sur 342 termes identifiés par les humains, le système en a récupéré 341. Les principales mesures de précision étaient solides : le recoupement entre les ensembles de termes IA et humains (similitude de Jaccard) était d’environ deux tiers, et l’équilibre entre exactitude et exhaustivité (score F1) était d’environ 0,80, comparable aux meilleurs outils dans d’autres domaines médicaux. La plupart des erreurs restantes se produisaient lorsque le terme oculaire nécessaire n’existait tout simplement pas encore dans l’ontologie.
Préserver la confidentialité des données tout en reliant les éléments
Un point notable de cette approche est qu’elle s’exécute entièrement sur le matériel local de l’hôpital, aidant les cliniques à se conformer aux règles strictes de protection des données tout en libérant la valeur de leurs dossiers. En convertissant des notes en texte libre en codes normalisés qui ne contiennent plus de noms ni d’identifiants directs, le système facilite le partage de données plus sûr pour les registres et la recherche. Sa conception modulaire permet à d’autres hôpitaux de l’adapter à leur propre vocabulaire et à leurs abréviations en ajustant les invites et en étendant les listes de synonymes, sans avoir à réentraîner de grands modèles d’IA.
Ce que cela pourrait signifier pour les patients et la recherche en ophtalmologie
Pour les patients, ce type de phénotypage automatisé pourrait permettre de reconnaître plus tôt des schémas rares de maladie et d’adapter et d’étudier plus efficacement les traitements entre centres. Pour les médecins et les chercheurs, il promet des revues de dossiers plus rapides, des registres plus complets et moins d’heures passées à coder manuellement. Les auteurs concluent qu’une chaîne IA basée sur la recherche d’information, solidement ancrée — construite autour d’une ontologie médicale de référence et adaptée au langage d’une clinique locale — peut traduire avec précision les notes d’ophtalmologie quotidiennes en données structurées prêtes pour la recherche, ouvrant la voie à une utilisation plus large de l’IA dans les soins oculaires de routine.
Citation: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Mots-clés: ophtalmologie, extraction de texte clinique, phénotypage, ontologies médicales, interopérabilité des données de santé