Clear Sky Science · en
Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO)
Why smarter reading of eye doctors’ notes matters
Every visit to an eye doctor produces a letter or report packed with observations about the patient’s eyes. These notes are vital for care, but they are written in free text, often in different languages and with each doctor using their own wording. That makes it hard to combine information across clinics, build large research registries, or quickly find patients with similar problems. This study shows how a carefully designed artificial intelligence (AI) system can automatically turn these messy narratives into a clean, standardized list of eye findings—without sending sensitive patient data to the cloud.
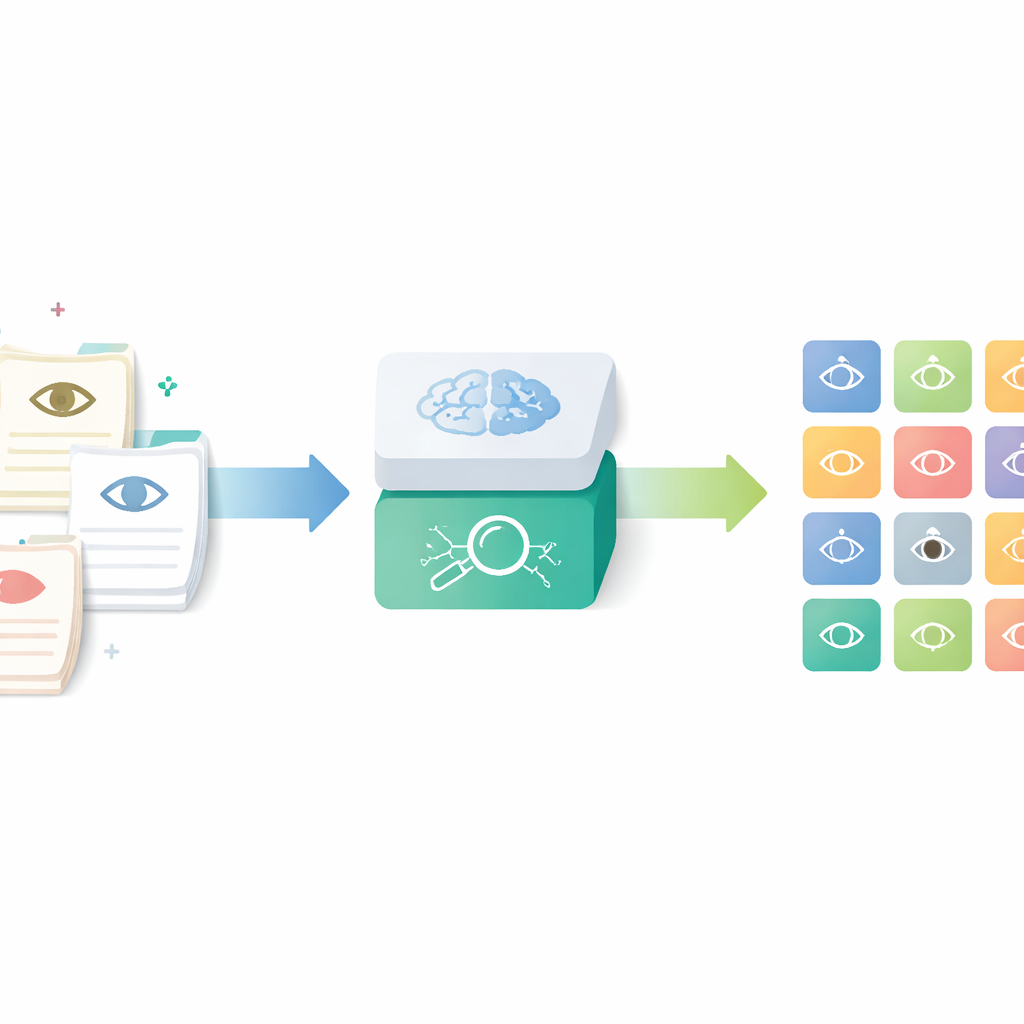
Turning everyday notes into structured data
The researchers focused on a tool called the Human Phenotype Ontology, a worldwide catalog of precisely defined medical features, including those of the eye. Instead of relying on doctors to manually look up and assign these codes—a time‑consuming and inconsistent process—they built an AI pipeline that reads routine ophthalmology letters and outputs the matching standardized terms. The goal was to capture the rich detail in real clinical notes while making the results usable for research, quality control, and multi-center registries.
Step-by-step journey from text to eye findings
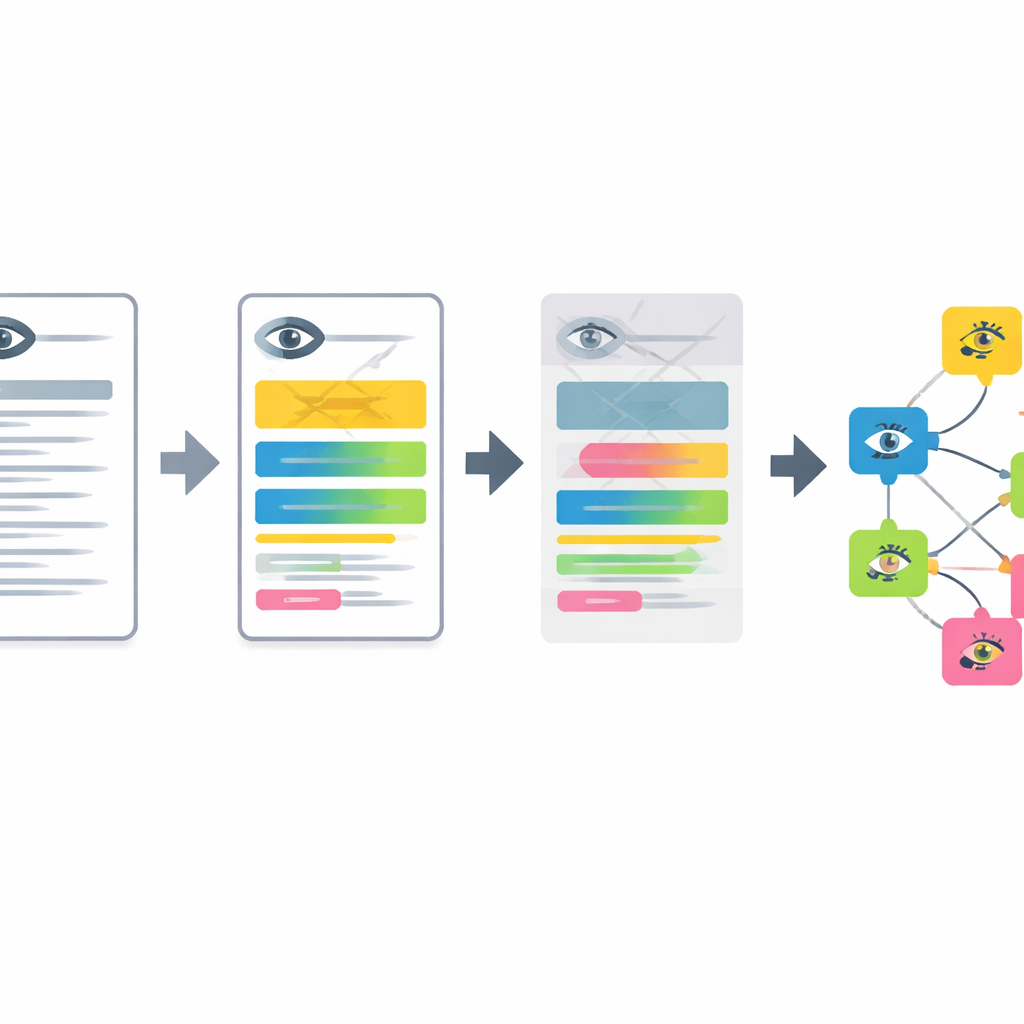
The pipeline works in four main stages. First, anonymized eye clinic notes written in German are translated into English by a compact language model tuned with example prompts. Second, the system breaks longer descriptions into short segments, each describing a single feature of the front or back of the eye. Third, it filters out normal findings and recognizes when a disease is explicitly ruled out, so that only true problems are kept. Finally, each remaining segment is transformed into a mathematical “embedding” and matched to the closest entry in an expanded, multilingual version of the Human Phenotype Ontology, yielding a specific, standardized eye phenotype term.
Teaching the system the language of eye care
Because many highly specific eye conditions or ways of phrasing them were missing from the standard catalog, the team built a local synonym list tailored to their clinic. Whenever the system chose the wrong term for a piece of text, experts corrected it and added the phrase as a new synonym for the right code. This “expert-in-the-loop” process was repeated on about 10,000 medical reports. New eye phenotypes that did not yet exist in the global ontology were proposed back to the international Human Phenotype Ontology consortium, helping to improve the shared standard for future users.
How well the AI agreed with human experts
To test performance, the researchers randomly selected 175 real patient records and had an experienced ophthalmologist annotate them by hand with ontology terms. On average, humans found 2.53 relevant eye features per letter, while the AI produced 2.52—almost identical. Out of 342 human-identified terms, the system retrieved 341. Key accuracy measures were strong: the overlap between AI and human term sets (Jaccard similarity) was about two‑thirds, and the balance of correctness and completeness (F1 score) was about 0.80, comparable to state‑of‑the‑art tools in other medical domains. Most remaining errors occurred when the needed eye term simply did not yet exist in the ontology.
Keeping data private while connecting the dots
A notable feature of this approach is that it runs entirely on local hospital hardware, helping clinics comply with strict data protection rules while still unlocking the value of their records. By turning free‑text notes into standardized codes that no longer contain names or direct identifiers, the system supports safer data sharing for registries and research. Its modular design allows other hospitals to adapt it to their own wording and abbreviations by adjusting prompts and extending synonym lists, without having to retrain large AI models.
What this could mean for patients and eye research
For patients, this kind of automated phenotyping could mean that rare patterns of disease are recognized sooner and that treatments can be better matched and studied across centers. For doctors and researchers, it promises faster chart reviews, more complete registries, and fewer hours spent on manual coding. The authors conclude that a carefully grounded, retrieval‑based AI pipeline—built around a trusted medical ontology and tuned to a local clinic’s language—can accurately translate everyday ophthalmology notes into structured, research‑ready data, paving the way for broader use of AI in routine eye care.
Citation: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Keywords: ophthalmology, clinical text mining, phenotyping, medical ontologies, health data interoperability