Clear Sky Science · it
Fenotipizzazione automatizzata delle malattie oftalmologiche dalle cartelle cliniche di routine usando piccoli modelli linguistici e l’Human Phenotype Ontology (HPO)
Perché è importante leggere meglio le note degli oculisti
Ogni visita dall’oculista genera una lettera o un referto ricco di osservazioni sugli occhi del paziente. Queste note sono fondamentali per la cura, ma sono scritte in testo libero, spesso in lingue diverse e con ciascun medico che usa la propria terminologia. Questo rende difficile aggregare informazioni tra cliniche, costruire grandi registri di ricerca o trovare rapidamente pazienti con problemi simili. Questo studio mostra come un sistema di intelligenza artificiale (IA) progettato con cura possa trasformare automaticamente questi resoconti disordinati in un elenco pulito e standardizzato di reperti oculari—senza inviare dati sensibili dei pazienti al cloud.
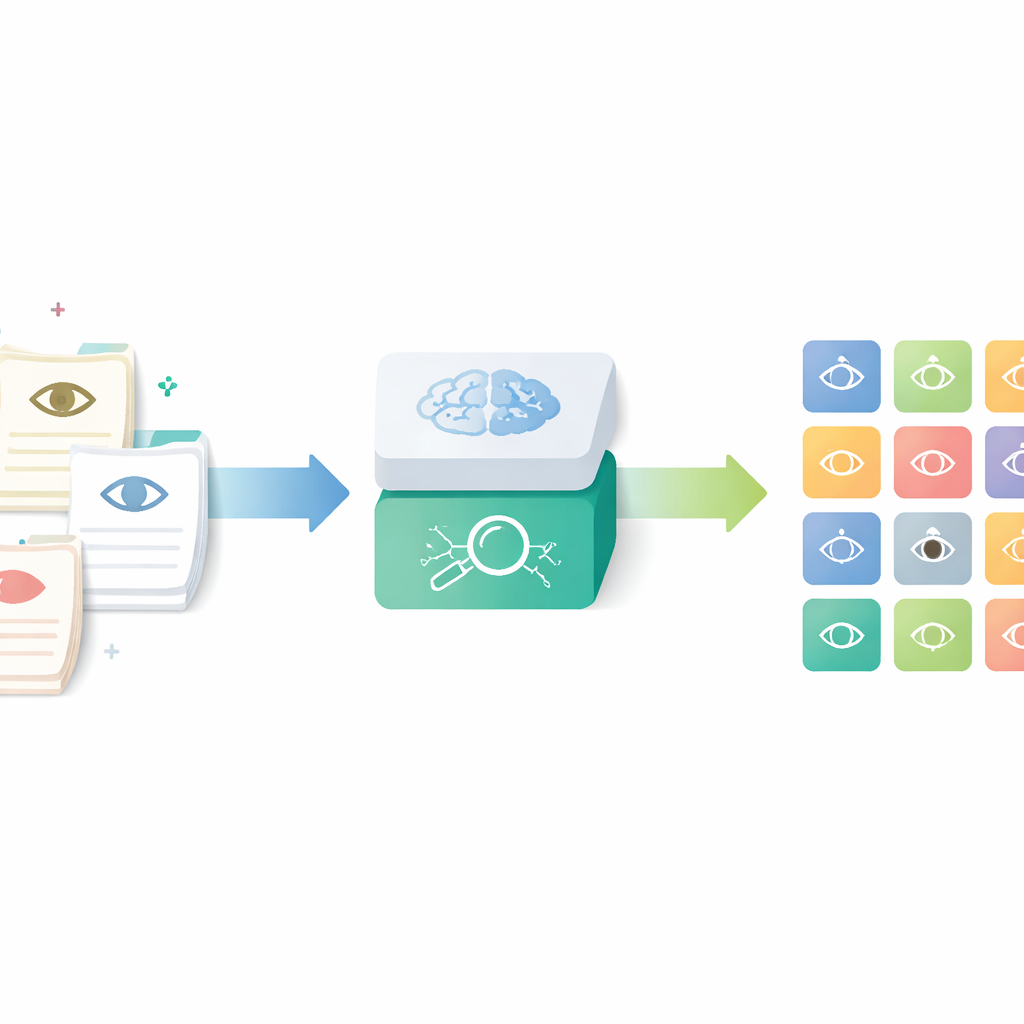
Trasformare le note quotidiane in dati strutturati
I ricercatori si sono concentrati su uno strumento chiamato Human Phenotype Ontology, un catalogo mondiale di caratteristiche mediche definite con precisione, comprese quelle oculari. Invece di affidarsi ai medici che devono cercare manualmente e assegnare questi codici—un processo dispendioso in termini di tempo e soggetto a variabilità—hanno costruito una pipeline di IA che legge le lettere oftalmologiche di routine e restituisce i termini standard corrispondenti. L’obiettivo era catturare il ricco dettaglio delle note cliniche reali rendendo i risultati utilizzabili per la ricerca, il controllo di qualità e registri multicentrici.
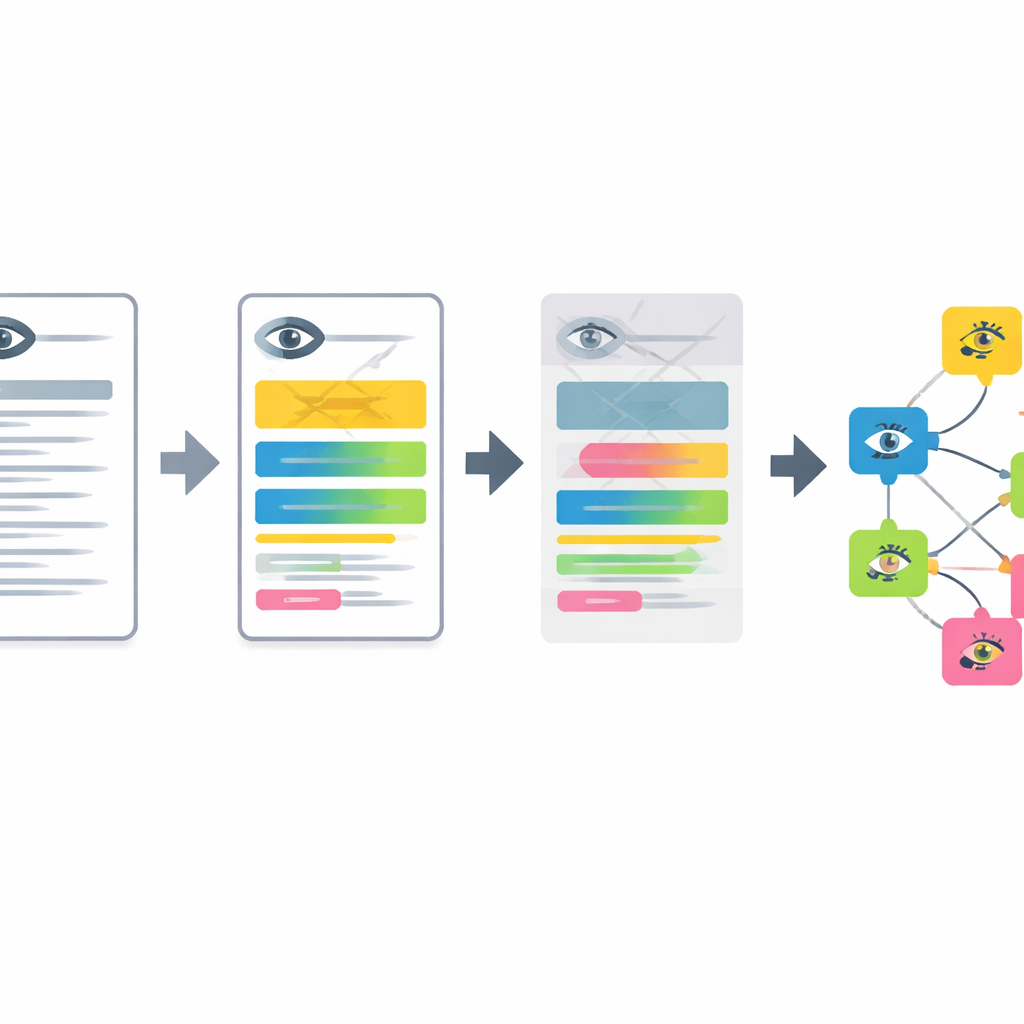
Il percorso passo dopo passo dal testo ai reperti oculari
La pipeline funziona in quattro fasi principali. Prima, le note anonimizate della clinica oculistica scritte in tedesco vengono tradotte in inglese da un modello linguistico compatto messo a punto con prompt di esempio. Secondo, il sistema divide descrizioni lunghe in brevi segmenti, ciascuno dei quali descrive una singola caratteristica della parte anteriore o posteriore dell’occhio. Terzo, filtra i reperti normali e riconosce quando una malattia è esplicitamente esclusa, così da conservare solo i problemi reali. Infine, ogni segmento rimanente viene trasformato in un “embedding” matematico e confrontato con la voce più vicina in una versione ampliata e multilingue dell’Human Phenotype Ontology, restituendo un termine fenotipico oculare specifico e standardizzato.
Insegnare al sistema il linguaggio della cura oculistica
Poiché molte condizioni oculari molto specifiche o modi di esprimerle mancavano nel catalogo standard, il team ha creato una lista locale di sinonimi adattata alla loro clinica. Ogni volta che il sistema sceglieva il termine sbagliato per un pezzo di testo, gli esperti lo correggevano e aggiungevano la frase come nuovo sinonimo per il codice corretto. Questo processo “esperto-in-the-loop” è stato ripetuto su circa 10.000 referti medici. I nuovi fenotipi oculari che non esistevano ancora nell’ontologia globale sono stati proposti al consorzio internazionale dell’Human Phenotype Ontology, contribuendo a migliorare lo standard condiviso per gli utenti futuri.
Quanto l’IA concordava con gli esperti umani
Per testare le prestazioni, i ricercatori hanno selezionato casualmente 175 cartelle cliniche reali e un oftalmologo esperto le ha annotate manualmente con termini dell’ontologia. In media, gli esseri umani hanno trovato 2,53 reperti oculari pertinenti per lettera, mentre l’IA ne ha prodotti 2,52—quasi identici. Su 342 termini identificati dagli umani, il sistema ne ha recuperati 341. Le misure chiave di accuratezza sono risultate solide: la sovrapposizione tra i set di termini IA e umani (somiglianza di Jaccard) era di circa due terzi, e l’equilibrio tra correttezza e completezza (punteggio F1) era circa 0,80, comparabile agli strumenti all’avanguardia in altri domini medici. La maggior parte degli errori residui si è verificata quando il termine oculare necessario semplicemente non esisteva ancora nell’ontologia.
Mantenere la privacy dei dati mentre si collegano le informazioni
Un aspetto notevole di questo approccio è che viene eseguito interamente sull’hardware locale dell’ospedale, aiutando le cliniche a rispettare rigide norme di protezione dei dati pur sbloccando il valore dei loro referti. Trasformando le note in testo libero in codici standardizzati che non contengono più nomi o identificatori diretti, il sistema favorisce condivisioni di dati più sicure per registri e ricerca. Il suo design modulare consente ad altri ospedali di adattarlo al proprio linguaggio e alle proprie abbreviazioni regolando i prompt ed estendendo le liste di sinonimi, senza dover riaddestrare grandi modelli di IA.
Cosa potrebbe significare per i pazienti e la ricerca oculistica
Per i pazienti, questo tipo di fenotipizzazione automatizzata potrebbe significare che pattern rari di malattia vengono riconosciuti prima e che i trattamenti possono essere meglio abbinati e studiati tra più centri. Per medici e ricercatori, promette revisioni delle cartelle più veloci, registri più completi e meno ore dedicate alla codifica manuale. Gli autori concludono che una pipeline IA basata su recupero delle informazioni—costruita attorno a un’ontologia medica affidabile e sintonizzata sul linguaggio di una clinica locale—può tradurre con precisione le note oftalmologiche di uso quotidiano in dati strutturati e pronti per la ricerca, aprendo la strada a un uso più ampio dell’IA nella cura oftalmologica di routine.
Citazione: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Parole chiave: oftalmologia, estrazione di testo clinico, fenotipizzazione, ontologie mediche, interoperabilità dei dati sanitari