Clear Sky Science · ru
Автоматизированный фенотипинг офтальмологических заболеваний по рутинным медицинским записям с помощью компактных языковых моделей и Онтологии человеческих фенотипов (HPO)
Почему важно лучше «читать» записи офтальмологов
Каждый визит к офтальмологу сопровождается письмом или отчётом, наполненным наблюдениями о состоянии глаз пациента. Эти заметки жизненно важны для ухода, но они оформлены в свободном тексте, часто на разных языках и с использованием индивидуальной терминологии каждого врача. Это затрудняет объединение данных между клиниками, создание крупных регистров для исследований и быстрый поиск пациентов с похожими проблемами. В этом исследовании показано, как продуманная система искусственного интеллекта (ИИ) автоматически преобразует такие неструктурированные тексты в чистый, стандартизованный список офтальмологических признаков — при этом не отправляя чувствительные данные пациентов в облако.
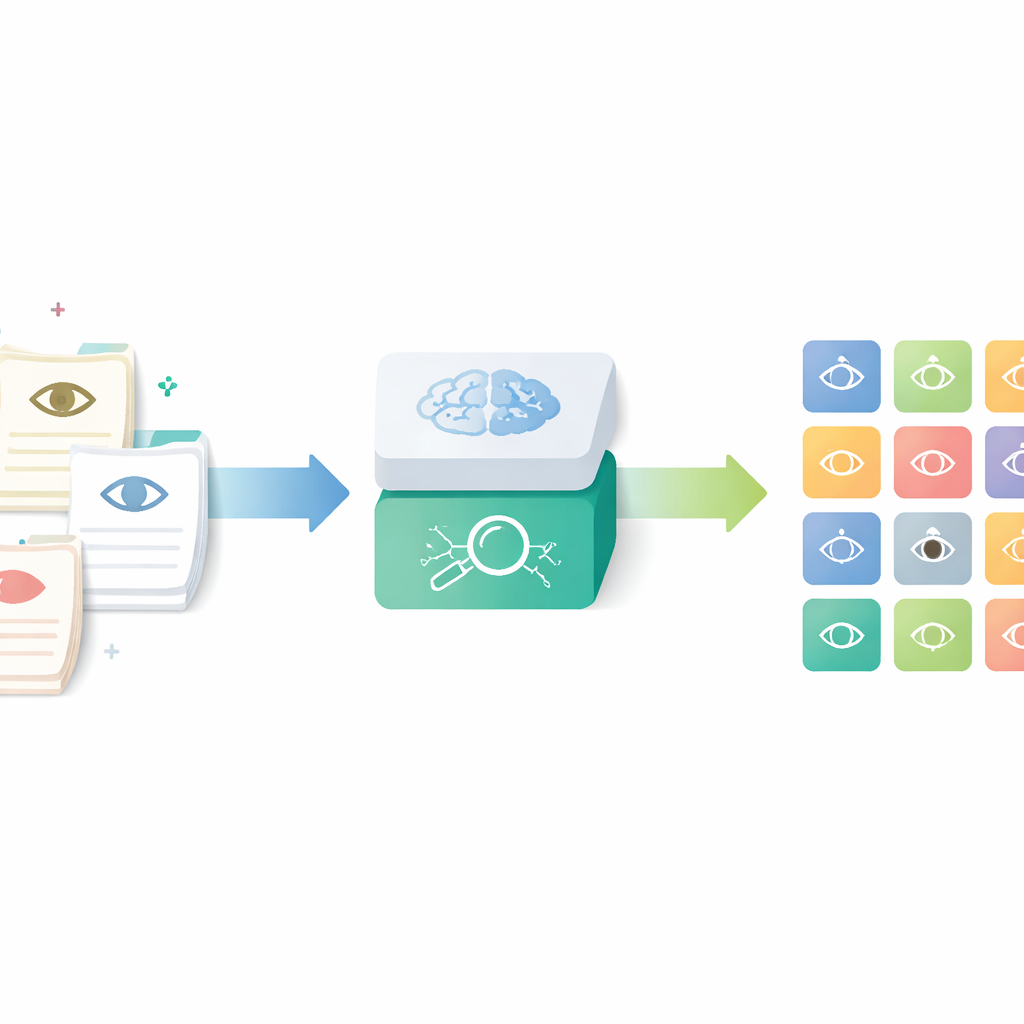
Преобразование повседневных записей в структурированные данные
Исследователи сосредоточились на инструменте под названием Онтология человеческих фенотипов (Human Phenotype Ontology), глобальном каталоге точно определённых медицинских признаков, включая офтальмологические. Вместо того чтобы полагаться на ручное присвоение кодов врачами — трудоёмкий и непоследовательный процесс — они разработали конвейер ИИ, который читает рутинные офтальмологические письма и выдаёт соответствующие стандартизованные термины. Цель заключалась в том, чтобы сохранить богатую детализацию реальных клинических заметок и одновременно сделать результаты пригодными для исследований, контроля качества и многоцентровых регистров.
Пошаговый путь от текста к офтальмологическим находкам
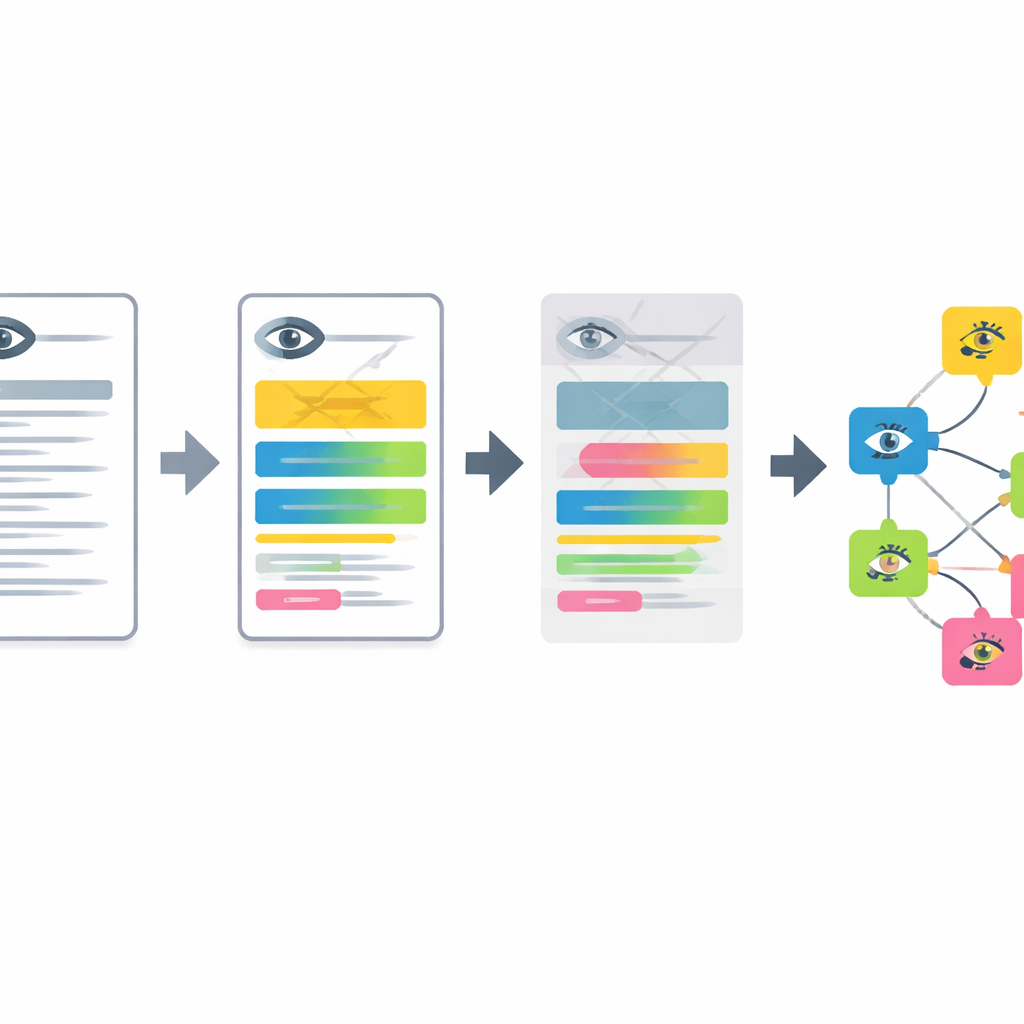
Конвейер работает в четырёх основных этапах. Сначала анонимизированные записи из офтальмологической клиники, написанные по-немецки, переводятся на английский компактной языковой моделью, настроенной с помощью примеров запросов. Затем система разбивает длинные описания на короткие сегменты, каждый из которых описывает одну характеристику переднего или заднего отрезка глаза. Третьим этапом отфильтровываются нормальные находки и распознаётся, когда заболевание явно исключается, так что сохраняются только реальные патологии. Наконец, каждый оставшийся сегмент преобразуется в математическое «встраивание» (embedding) и сопоставляется с ближайшей записью в расширенной многоязычной версии Онтологии человеческих фенотипов, что даёт конкретный стандартизованный термин офтальмологического фенотипа.
Обучение системы языку офтальмологической помощи
Поскольку многие узкоспецифические офтальмологические состояния или варианты формулировок отсутствовали в стандартном каталоге, команда составила локальный список синонимов, адаптированный к их клинике. Когда система выбирала неверный термин для отрывка текста, эксперты исправляли ошибку и добавляли фразу как новый синоним для правильного кода. Этот процесс «эксперт в петле» повторяли примерно на 10 000 медицинских отчётов. Новые офтальмологические фенотипы, которых ещё не было в глобальной онтологии, предлагались обратно в международный консорциум Human Phenotype Ontology, помогая улучшить общий стандарт для будущих пользователей.
Насколько ИИ совпадал с мнением экспертов
Для оценки производительности исследователи случайно выбрали 175 реальных историй болезни и попросили опытного офтальмолога вручную аннотировать их терминами онтологии. В среднем люди находили 2,53 релевантных офтальмологических признака на письмо, тогда как ИИ выдавал 2,52 — почти идентично. Из 342 терминов, отмеченных людьми, система извлекла 341. Ключевые метрики точности были высоки: пересечение множеств терминов ИИ и человека (коэффициент Жаккара) составляло около двух третей, а баланс корректности и полноты (F1‑мера) — примерно 0,80, сопоставимо с передовыми инструментами в других медицинских областях. Большинство оставшихся ошибок возникали тогда, когда требуемого офтальмологического термина просто ещё не было в онтологии.
Сохранение приватности данных при объединении информации
Важной особенностью подхода является то, что он выполняется полностью на локальном оборудовании больницы, что помогает клиникам соответствовать строгим правилам защиты данных и одновременно раскрывать ценность своих записей. Преобразуя свободно оформленные заметки в стандартизованные коды, которые больше не содержат имён или прямых идентификаторов, система поддерживает более безопасный обмен данными для регистров и исследований. Модульная архитектура позволяет другим больницам адаптировать её к своей терминологии и аббревиатурам, корректируя промпты и расширяя списки синонимов, без необходимости дообучать крупные модели ИИ.
Что это может значить для пациентов и офтальмологических исследований
Для пациентов такой автоматизированный фенотипинг может означать более раннее распознавание редких паттернов заболеваний и лучшее сопоставление и изучение лечебных подходов между центрами. Для врачей и исследователей это обещает ускорение обзоров карт, более полные регистры и меньше часов, затрачиваемых на ручное кодирование. Авторы делают вывод, что продуманно обоснованный конвейер ИИ на основе поиска и сопоставления — построенный вокруг надёжной медицинской онтологии и настроенный под язык локальной клиники — способен точно переводить повседневные офтальмологические заметки в структурированные данные, готовые для исследований, открывая путь к более широкому применению ИИ в рутинной офтальмологической помощи.
Цитирование: Thai, B.D., Arens, S., Reinhard, T. et al. Automated phenotyping of ophthalmologic diseases from routine medical records using small language models and the human phenotype ontology (HPO). Sci Rep 16, 14682 (2026). https://doi.org/10.1038/s41598-026-51512-z
Ключевые слова: офтальмология, извлечение информации из клинических текстов, фенотипирование, медицинские онтологии, взаимодействие данных здравоохранения