Clear Sky Science · zh
用于鲁棒多尺度目标分类的元学习动态分层融合
为何更聪明的视觉重要
从自动驾驶汽车到医学影像,现代相机和传感器为计算机提供了海量视觉数据。然而,即便是强大的视觉系统在光照变化、目标以奇怪角度出现或图像来自新来源时也会出现失误。本研究提出了一种方法,使图像识别模型能够根据所见每张图像自适应其内部工作方式,旨在在不显著降低速度的前提下做出更可靠的决策。
以多尺度观察图像
计算机视觉系统看待照片的方式不同于人类。它们将图像分解为多个特征层级,从简单的边缘与颜色到复杂的形状如车轮或人脸。传统模型必须在训练阶段就确定如何将这些层级组合为最终判断,采用固定的规则。当新图像与训练数据相似时这些规则表现良好,但当细节发生变化——例如不同纹理、相机风格或相似物体间的细微差异——时,规则可能失效。
从固定规则到灵活决策
作者提出了元学习动态分层融合(Meta Learned Dynamic Hierarchical Fusion,MDHF),用一个可学习的决策者来替代固定的融合规则,从而实现即时调整。MDHF不再固守一种从各层混合信息的方式,而是学习一个更高层的策略,能够为每张输入图像选择不同的组合。在训练过程中,系统暴露于多种人为制造的风格与噪声变化,教会它在多样条件下挑选有效的融合策略。测试时,它能在单次前向过程中对每张新图像做出响应,而无需额外微调或缓慢的调整步骤。
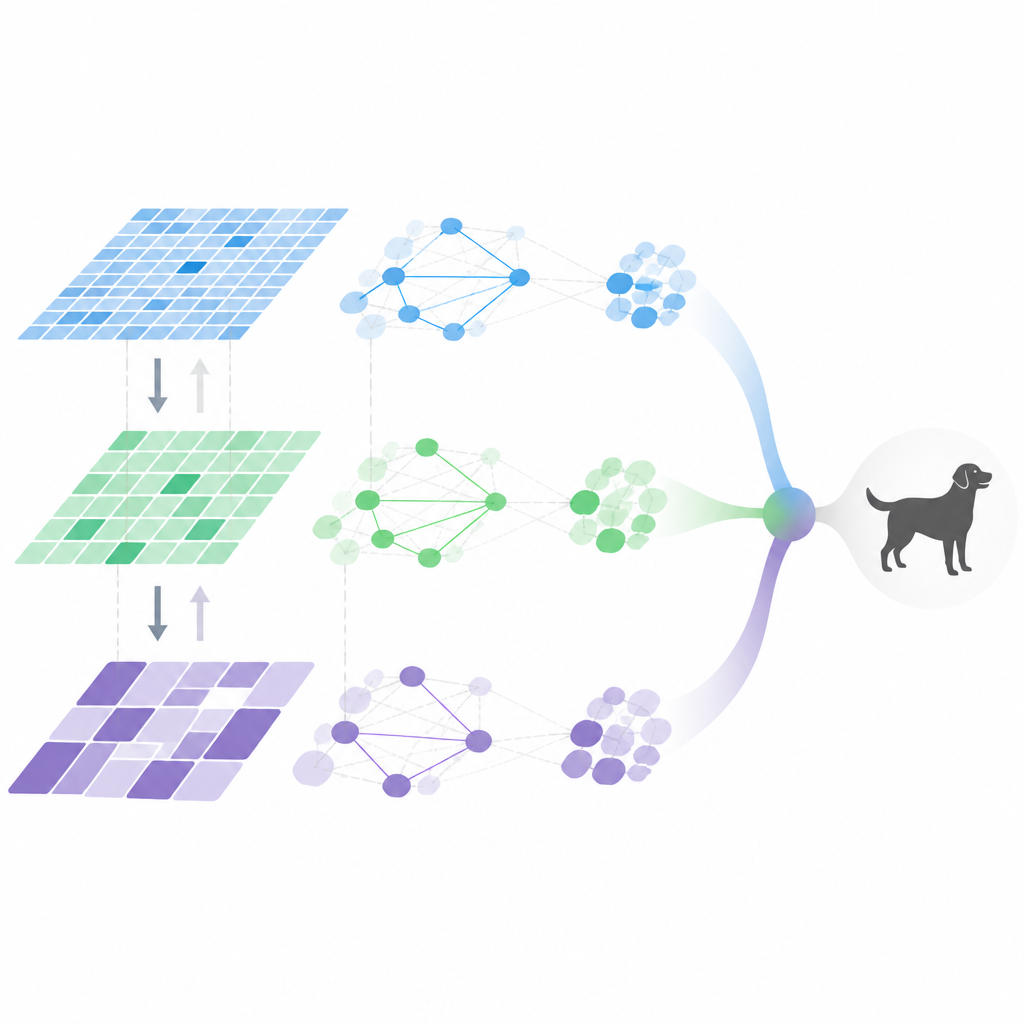
自适应视觉流水线的内部
MDHF结合了若干思想以实现这种灵活行为。首先,它使用可调采样位置的特殊卷积构建多尺度特征,从而捕获不同大小的细节。一个元学习的注意力模块随后决定每张图像应强调哪些通道和尺度,该模块由跨多项训练任务学到的先验引导。接着,信息在特征层次间双向流动,使细节与高层语义能够相互强化而非消退。最后,特征间的关系用稀疏图建模,仅保留最重要的连接,这在减少计算量的同时仍能捕捉关键交互。
在真实与高压场景中的表现
研究者在五个图像数据集上测试了 MDHF,涵盖简单物体、大规模识别、精细车类与宠物类别,以及一个具有类别不均衡挑战的数据集。在所有数据集上,MDHF与十五种对比方法相比表现相当或更好,常常参数远少于基于 Transformer 的模型且推理更快。其优势在精细任务上尤为明显,这类任务需要注意样本特定的小线索,例如车部件或动物面部的细微差异。MDHF 在图像被噪声、模糊或对比度变化破坏时,以及在面对精心设计的对抗攻击时也表现出强大的韧性;在其他模型性能急剧下降的情况下,它保留了较大比例的准确率。
灵活性的局限
尽管 MDHF 能很好地适应多种变化,作者也探讨了其薄弱之处。当图像与元训练期间见到的任何样本差异过大时,例如极端视角或主要依赖纹理而非结构的任务,所有方法(包括 MDHF)的性能都会下降。尽管 MDHF 比许多先进基线更高效,但在极低功耗设备上其资源需求仍可能成为挑战。这些分析有助于明确动态融合最有用的场景及未来需要改进的方向。
对日常 AI 的意义
对非专业读者而言,主要结论是这项工作将视觉系统中一个僵化的部分转变为更像一本可学习的手册,能即时选择策略。MDHF 不再以相同方式始终融合视觉线索,而是学习在每张图像上以不同方式混合它们,同时保持实用的预测速度。这带来更高的准确率,尤以棘手的精细差异以及噪声或分布偏移条件下为著称,并指向未来 AI 系统能让其内部决策过程随所见环境自适应的方向。
引用: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
关键词: 计算机视觉, 特征融合, 元学习, 目标分类, 鲁棒识别